 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaliGemma: A versatile 3B VLM for transfer
Jul 10, 2024



PaliGemma is an open Vision-Language Model (VLM) that is based on the SigLIP-So400m vision encoder and the Gemma-2B language model. It is trained to be a versatile and broadly knowledgeable base model that is effective to transfer. It achieves strong performance on a wide variety of open-world tasks. We evaluate PaliGemma on almost 40 diverse tasks including standard VLM benchmarks, but also more specialized tasks such as remote-sensing and segmentation.
Benchmark and Best Practices for Biomedical Knowledge Graph Embeddings
Jun 24, 2020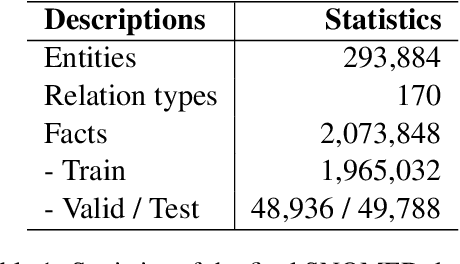
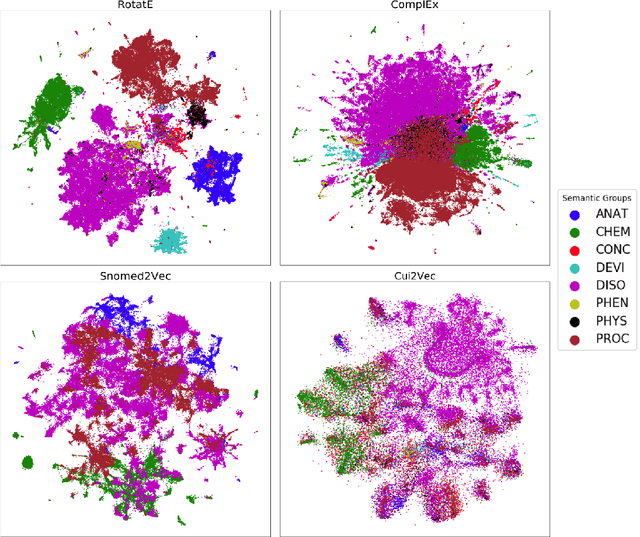
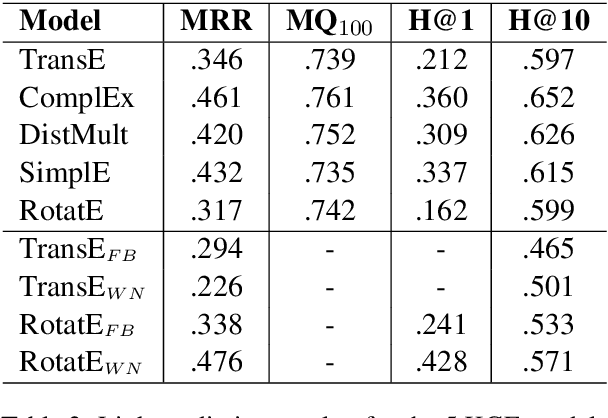
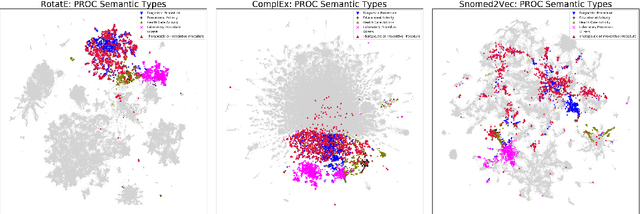
Much of biomedical and healthcare data is encoded in discrete, symbolic form such as text and medical codes. There is a wealth of expert-curated biomedical domain knowledge stored in knowledge bases and ontologies, but the lack of reliable methods for learning knowledge representation has limited their usefulness in machine learning applications. While text-based representation learning has significantly improved in recent years through advances in natural language processing, attempts to learn biomedical concept embeddings so far have been lacking. A recent family of models called knowledge graph embeddings have shown promising results on general domain knowledge graphs, and we explore their capabilities in the biomedical domain. We train several state-of-the-art knowledge graph embedding models on the SNOMED-CT knowledge graph, provide a benchmark with comparison to existing methods and in-depth discussion on best practices, and make a case for the importance of leveraging the multi-relational nature of knowledge graphs for learning biomedical knowledge representation. The embeddings, code, and materials will be made available to the communitY.
On Understanding Knowledge Graph Representation
Sep 25, 2019
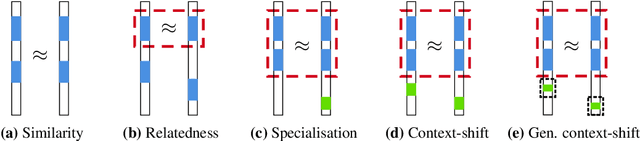

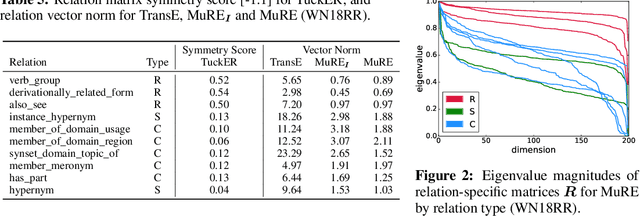
Many methods have been developed to represent knowledge graph data, which implicitly exploit low-rank latent structure in the data to encode known information and enable unknown facts to be inferred. To predict whether a relationship holds between entities, their embeddings are typically compared in the latent space following a relation-specific mapping. Whilst link prediction has steadily improved, the latent structure, and hence why such models capture semantic information, remains unexplained. We build on recent theoretical interpretation of word embeddings as a basis to consider an explicit structure for representations of relations between entities. For identifiable relation types, we are able to predict properties and justify the relative performance of leading knowledge graph representation methods, including their often overlooked ability to make independent predictions.
Hypernetwork Knowledge Graph Embeddings
Oct 18, 2018



Knowledge graphs are large graph-structured databases of facts, which typically suffer from incompleteness. Link prediction is the task of inferring missing relations (links) between entities (nodes) in a knowledge graph. We approach this task using a hypernetwork architecture to generate convolutional layer filters specific to each relation and apply those filters to the subject entity embeddings. This architecture enables a trade-off between non-linear expressiveness and the number of parameters to learn. Our model simplifies the entity and relation embedding interactions introduced by the predecessor convolutional model, while outperforming all previous approaches to link prediction across all standard link prediction datasets.
Language Detection For Short Text Messages In Social Media
Aug 30, 2016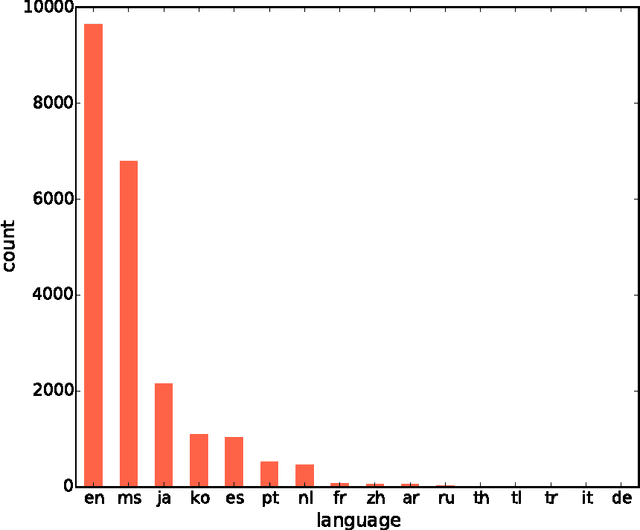
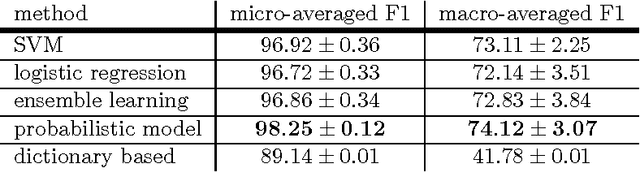

With the constant growth of the World Wide Web and the number of documents in different languages accordingly, the need for reliable language detection tools has increased as well. Platforms such as Twitter with predominantly short texts are becoming important information resources, which additionally imposes the need for short texts language detection algorithms. In this paper, we show how incorporating personalized user-specific information into the language detection algorithm leads to an important improvement of detection results. To choose the best algorithm for language detection for short text messages, we investigate several machine learning approaches. These approaches include the use of the well-known classifiers such as SVM and logistic regression, a dictionary based approach, and a probabilistic model based on modified Kneser-Ney smoothing. Furthermore, the extension of the probabilistic model to include additional user-specific information such as evidence accumulation per user and user interface language is explored, with the goal of improving the classification performance. The proposed approaches are evaluated on randomly collected Twitter data containing Latin as well as non-Latin alphabet languages and the quality of the obtained results is compared, followed by the selection of the best performing algorithm. This algorithm is then evaluated against two already existing general language detection tools: Chromium Compact Language Detector 2 (CLD2) and langid, where our method significantly outperforms the results achieved by both of the mentioned methods. Additionally, a preview of benefits and possible applications of having a reliable language detection algorithm is given.