 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnpicking Data at the Seams: VAEs, Disentanglement and Independent Components
Oct 29, 2024Disentanglement, or identifying salient statistically independent factors of the data, is of interest in many areas of machine learning and statistics, with relevance to synthetic data generation with controlled properties, robust classification of features, parsimonious encoding, and a greater understanding of the generative process underlying the data. Disentanglement arises in several generative paradigms, including Variational Autoencoders (VAEs), Generative Adversarial Networks and diffusion models. Particular progress has recently been made in understanding disentanglement in VAEs, where the choice of diagonal posterior covariance matrices is shown to promote mutual orthogonality between columns of the decoder's Jacobian. We continue this thread to show how this linear independence translates to statistical independence, completing the chain in understanding how the VAE's objective identifies independent components of, or disentangles, the data.
A Probabilistic Model to explain Self-Supervised Representation Learning
Feb 02, 2024



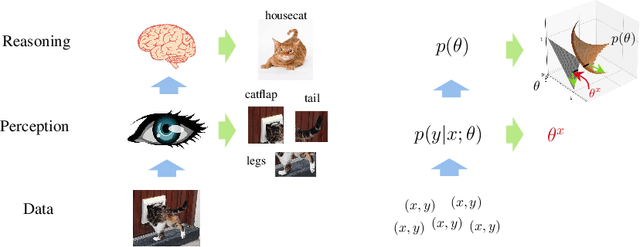
Self-supervised learning (SSL) learns representations by leveraging an auxiliary unsupervised task, such as classifying semantically related samples, e.g. different data augmentations or modalities. Of the many approaches to SSL, contrastive methods, e.g. SimCLR, CLIP and VicREG, have gained attention for learning representations that achieve downstream performance close to that of supervised learning. However, a theoretical understanding of the mechanism behind these methods eludes. We propose a generative latent variable model for the data and show that several families of discriminative self-supervised algorithms, including contrastive methods, approximately induce its latent structure over representations, providing a unifying theoretical framework. We also justify links to mutual information and the use of a projection head. Fitting our model generatively, as SimVE, improves performance over previous VAE methods on common benchmarks (e.g. FashionMNIST, CIFAR10, CelebA), narrows the gap to discriminative methods on _content_ classification and, as our analysis predicts, outperforms them where _style_ information is required, taking a step toward task-agnostic representations.
Variational Classification
May 17, 2023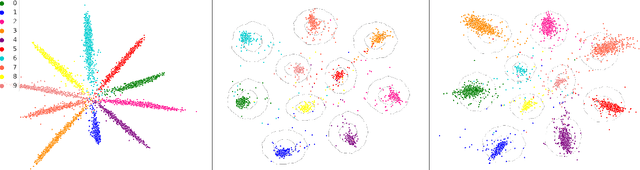

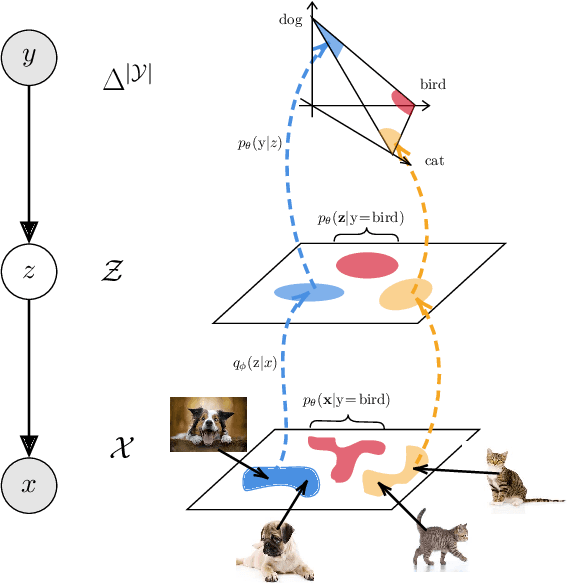

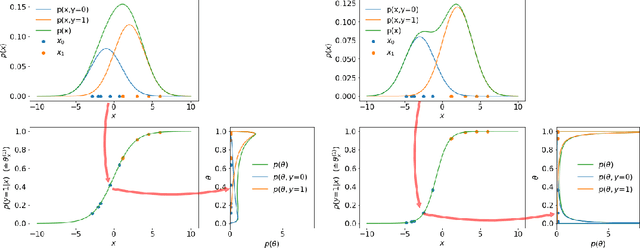
We present a novel extension of the traditional neural network approach to classification tasks, referred to as variational classification (VC). By incorporating latent variable modeling, akin to the relationship between variational autoencoders and traditional autoencoders, we derive a training objective based on the evidence lower bound (ELBO), optimized using an adversarial approach. Our VC model allows for more flexibility in design choices, in particular class-conditional latent priors, in place of the implicit assumptions made in off-the-shelf softmax classifiers. Empirical evaluation on image and text classification datasets demonstrates the effectiveness of our approach in terms of maintaining prediction accuracy while improving other desirable properties such as calibration and adversarial robustness, even when applied to out-of-domain data.
Adapters for Enhanced Modeling of Multilingual Knowledge and Text
Oct 26, 2022
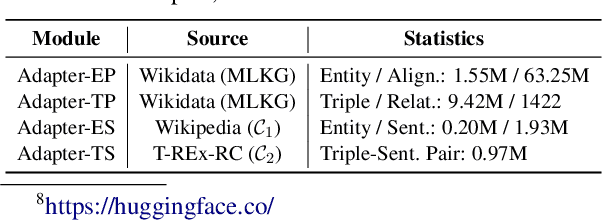

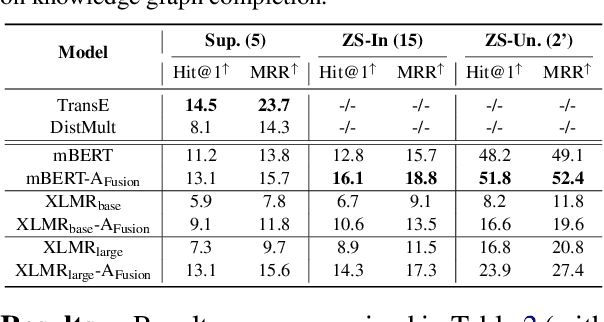
Large language models appear to learn facts from the large text corpora they are trained on. Such facts are encoded implicitly within their many parameters, making it difficult to verify or manipulate what knowledge has been learned. Language models have recently been extended to multilingual language models (MLLMs), enabling knowledge to be learned across hundreds of languages. Meanwhile, knowledge graphs contain facts in an explicit triple format, which require careful and costly curation and are only available in a few high-resource languages, restricting their research and application. To address these issues, we propose to enhance MLLMs with knowledge from multilingual knowledge graphs (MLKGs) so as to tackle language and knowledge graph tasks across many languages, including low-resource ones. Specifically, we introduce a lightweight adapter set to enhance MLLMs with cross-lingual entity alignment and facts from MLKGs for many languages. Experiments on common benchmarks show that such enhancement benefits both MLLMs and MLKGs, achieving: (1) comparable or improved performance for knowledge graph completion and entity alignment relative to baselines, especially for low-resource languages (for which knowledge graphs are unavailable); and (2) improved MLLM performance on language understanding tasks that require multilingual factual knowledge; all while maintaining performance on other general language tasks.
Learning to Drop Out: An Adversarial Approach to Training Sequence VAEs
Sep 26, 2022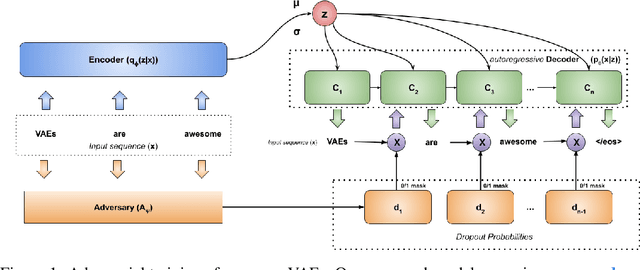
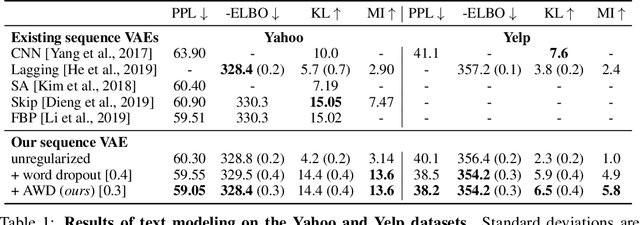
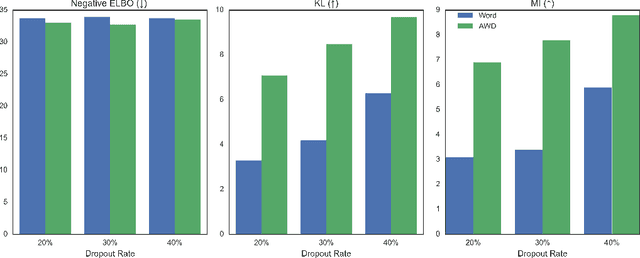

In principle, applying variational autoencoders (VAEs) to sequential data offers a method for controlled sequence generation, manipulation, and structured representation learning. However, training sequence VAEs is challenging: autoregressive decoders can often explain the data without utilizing the latent space, known as posterior collapse. To mitigate this, state-of-the-art models weaken the powerful decoder by applying uniformly random dropout to the decoder input. We show theoretically that this removes pointwise mutual information provided by the decoder input, which is compensated for by utilizing the latent space. We then propose an adversarial training strategy to achieve information-based stochastic dropout. Compared to uniform dropout on standard text benchmark datasets, our targeted approach increases both sequence modeling performance and the information captured in the latent space.
Towards a Theoretical Understanding of Word and Relation Representation
Feb 01, 2022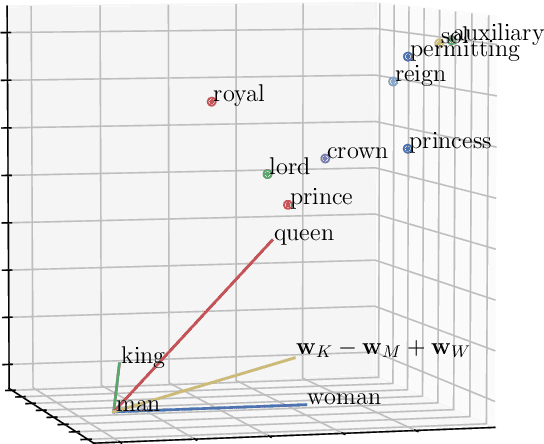

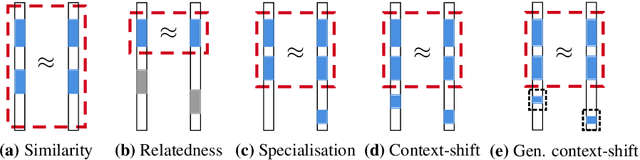
Representing words by vectors, or embeddings, enables computational reasoning and is foundational to automating natural language tasks. For example, if word embeddings of similar words contain similar values, word similarity can be readily assessed, whereas judging that from their spelling is often impossible (e.g. cat /feline) and to predetermine and store similarities between all words is prohibitively time-consuming, memory intensive and subjective. We focus on word embeddings learned from text corpora and knowledge graphs. Several well-known algorithms learn word embeddings from text on an unsupervised basis by learning to predict those words that occur around each word, e.g. word2vec and GloVe. Parameters of such word embeddings are known to reflect word co-occurrence statistics, but how they capture semantic meaning has been unclear. Knowledge graph representation models learn representations both of entities (words, people, places, etc.) and relations between them, typically by training a model to predict known facts in a supervised manner. Despite steady improvements in fact prediction accuracy, little is understood of the latent structure that enables this. The limited understanding of how latent semantic structure is encoded in the geometry of word embeddings and knowledge graph representations makes a principled means of improving their performance, reliability or interpretability unclear. To address this: 1. we theoretically justify the empirical observation that particular geometric relationships between word embeddings learned by algorithms such as word2vec and GloVe correspond to semantic relations between words; and 2. we extend this correspondence between semantics and geometry to the entities and relations of knowledge graphs, providing a model for the latent structure of knowledge graph representation linked to that of word embeddings.
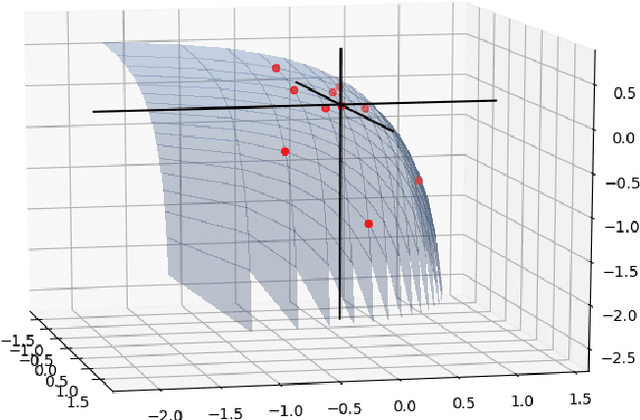
Learning the Prediction Distribution for Semi-Supervised Learning with Normalising Flows
Jul 06, 2020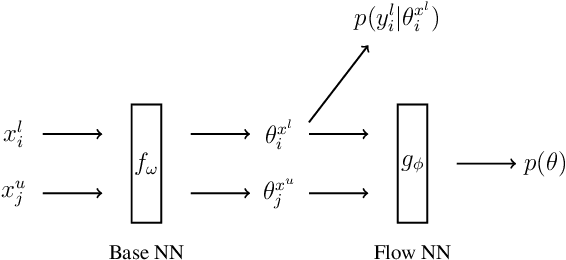
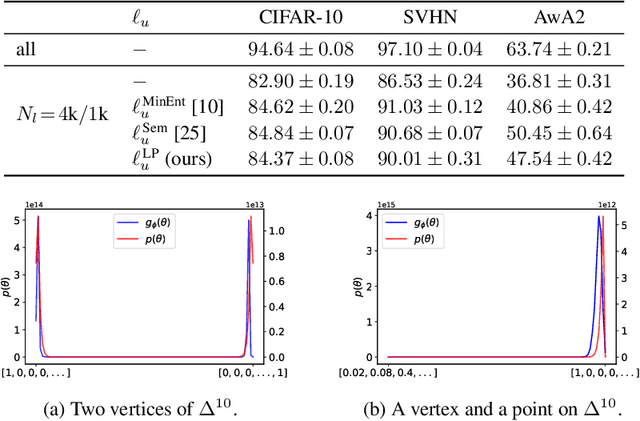

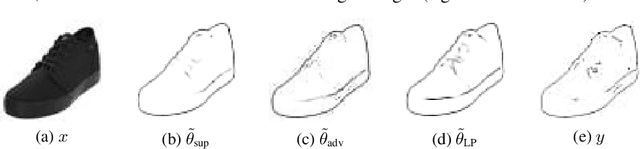
As data volumes continue to grow, the labelling process increasingly becomes a bottleneck, creating demand for methods that leverage information from unlabelled data. Impressive results have been achieved in semi-supervised learning (SSL) for image classification, nearing fully supervised performance, with only a fraction of the data labelled. In this work, we propose a probabilistically principled general approach to SSL that considers the distribution over label predictions, for labels of different complexity, from "one-hot" vectors to binary vectors and images. Our method regularises an underlying supervised model, using a normalising flow that learns the posterior distribution over predictions for labelled data, to serve as a prior over the predictions on unlabelled data. We demonstrate the general applicability of this approach on a range of computer vision tasks with varying output complexity: classification, attribute prediction and image-to-image translation.
Benchmark and Best Practices for Biomedical Knowledge Graph Embeddings
Jun 24, 2020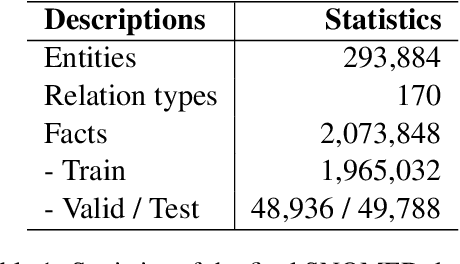
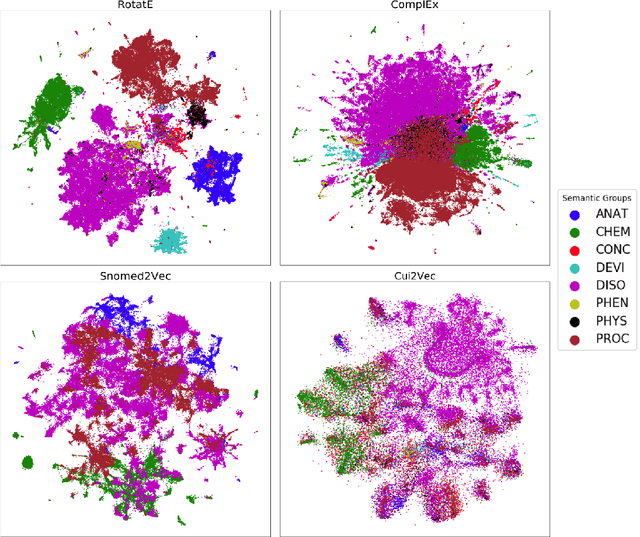
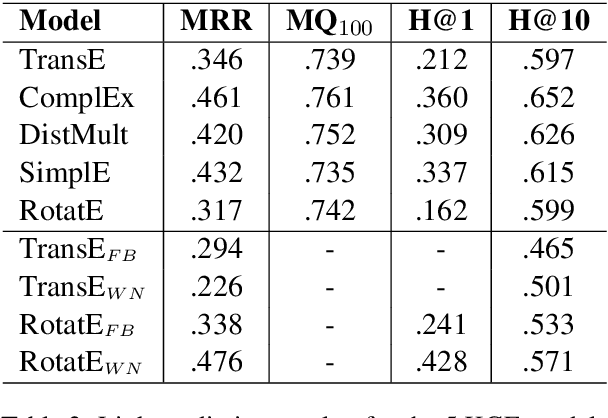
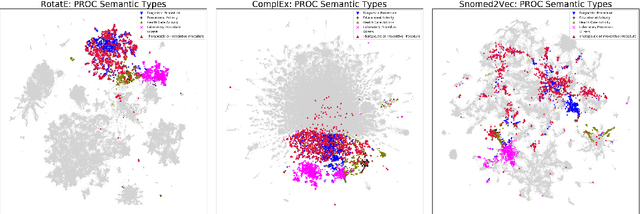
Much of biomedical and healthcare data is encoded in discrete, symbolic form such as text and medical codes. There is a wealth of expert-curated biomedical domain knowledge stored in knowledge bases and ontologies, but the lack of reliable methods for learning knowledge representation has limited their usefulness in machine learning applications. While text-based representation learning has significantly improved in recent years through advances in natural language processing, attempts to learn biomedical concept embeddings so far have been lacking. A recent family of models called knowledge graph embeddings have shown promising results on general domain knowledge graphs, and we explore their capabilities in the biomedical domain. We train several state-of-the-art knowledge graph embedding models on the SNOMED-CT knowledge graph, provide a benchmark with comparison to existing methods and in-depth discussion on best practices, and make a case for the importance of leveraging the multi-relational nature of knowledge graphs for learning biomedical knowledge representation. The embeddings, code, and materials will be made available to the communitY.
A Probabilistic Framework for Discriminative and Neuro-Symbolic Semi-Supervised Learning
Jun 10, 2020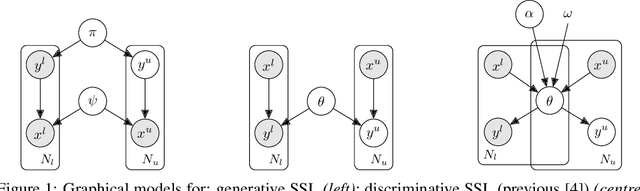

In semi-supervised learning (SSL), a rule to predict labels $y$ for data $x$ is learned from labelled data $(x^l,y^l)$ and unlabelled samples $x^u$. Strong progress has been made by combining a variety of methods, some of which pertain to $p(x)$, e.g. data augmentation that generates artificial samples from true $x$; whilst others relate to model outputs $p(y|x)$, e.g. regularising predictions on unlabelled data to minimise entropy or induce mutual exclusivity. Focusing on the latter, we fill a gap in the standard text by introducing a unifying probabilistic model for discriminative semi-supervised learning, mirroring that for classical generative methods. We show that several SSL methods can be theoretically justified under our model as inducing approximate priors over predicted parameters of $p(y|x)$. For tasks where labels represent binary attributes, our model leads to a principled approach to neuro-symbolic SSL, bridging the divide between statistical learning and logical rules.
Multi-scale Attributed Node Embedding
Sep 28, 2019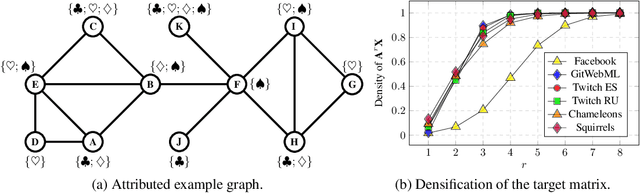
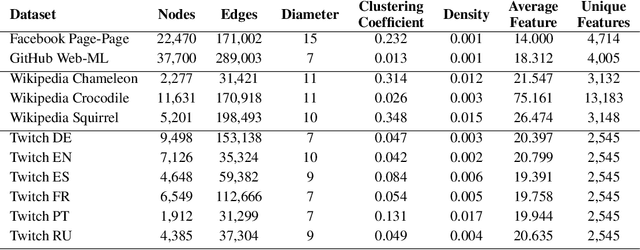

We present network embedding algorithms that capture information about a node from the local distribution over node attributes around it, as observed over random walks following an approach similar to Skip-gram. Observations from neighborhoods of different sizes are either pooled (AE) or encoded distinctly in a multi-scale approach (MUSAE). Capturing attribute-neighborhood relationships over multiple scales is useful for a diverse range of applications, including latent feature identification across disconnected networks with similar attributes. We prove theoretically that matrices of node-feature pointwise mutual information are implicitly factorized by the embeddings. Experiments show that our algorithms are robust, computationally efficient and outperform comparable models on social, web and citation network datasets.