 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the Prediction Distribution for Semi-Supervised Learning with Normalising Flows
Paper and Code
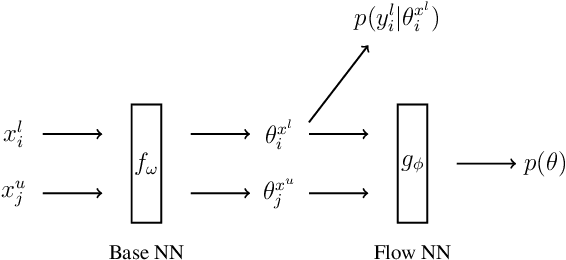
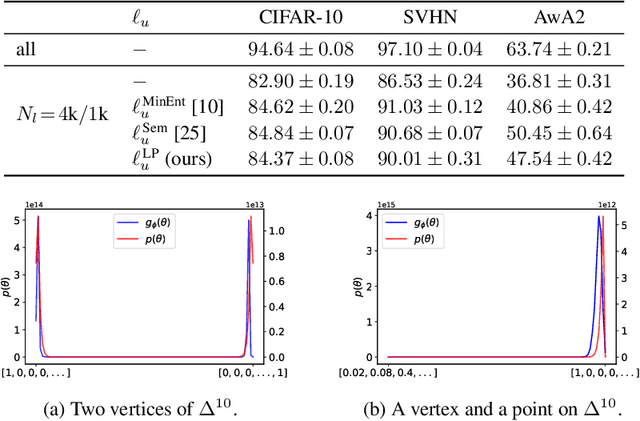

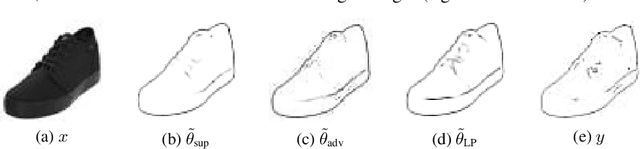
As data volumes continue to grow, the labelling process increasingly becomes a bottleneck, creating demand for methods that leverage information from unlabelled data. Impressive results have been achieved in semi-supervised learning (SSL) for image classification, nearing fully supervised performance, with only a fraction of the data labelled. In this work, we propose a probabilistically principled general approach to SSL that considers the distribution over label predictions, for labels of different complexity, from "one-hot" vectors to binary vectors and images. Our method regularises an underlying supervised model, using a normalising flow that learns the posterior distribution over predictions for labelled data, to serve as a prior over the predictions on unlabelled data. We demonstrate the general applicability of this approach on a range of computer vision tasks with varying output complexity: classification, attribute prediction and image-to-image translation.