 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining deep learning for ECG using time-localized clusters
Sep 18, 2025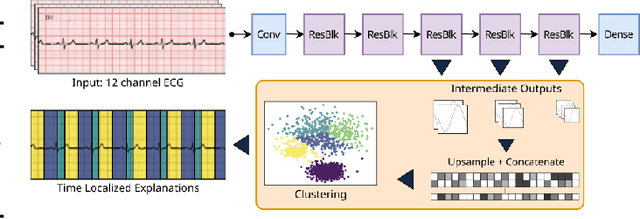
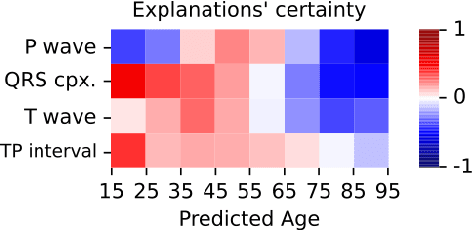
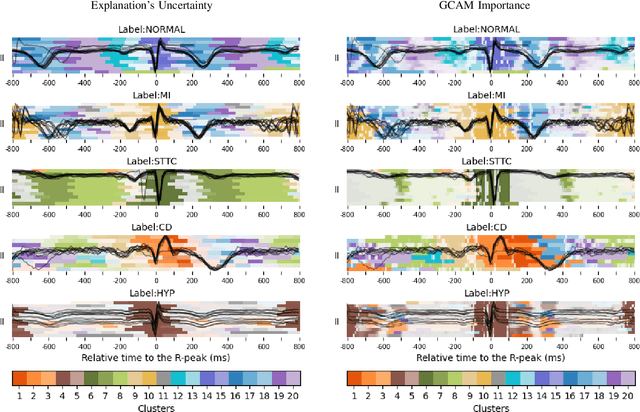
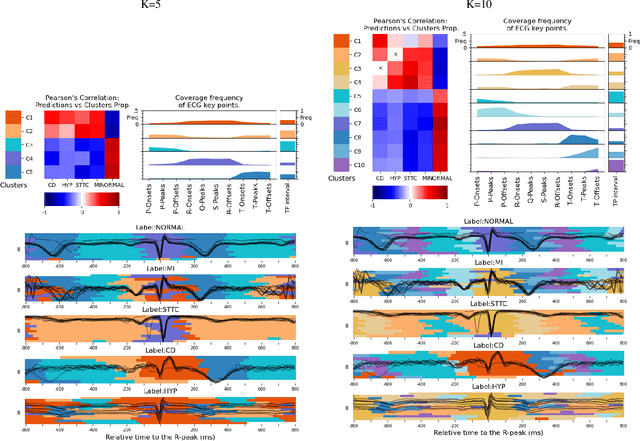
Deep learning has significantly advanced electrocardiogram (ECG) analysis, enabling automatic annotation, disease screening, and prognosis beyond traditional clinical capabilities. However, understanding these models remains a challenge, limiting interpretation and gaining knowledge from these developments. In this work, we propose a novel interpretability method for convolutional neural networks applied to ECG analysis. Our approach extracts time-localized clusters from the model's internal representations, segmenting the ECG according to the learned characteristics while quantifying the uncertainty of these representations. This allows us to visualize how different waveform regions contribute to the model's predictions and assess the certainty of its decisions. By providing a structured and interpretable view of deep learning models for ECG, our method enhances trust in AI-driven diagnostics and facilitates the discovery of clinically relevant electrophysiological patterns.
Explaining the Impact of Training on Vision Models via Activation Clustering
Nov 29, 2024
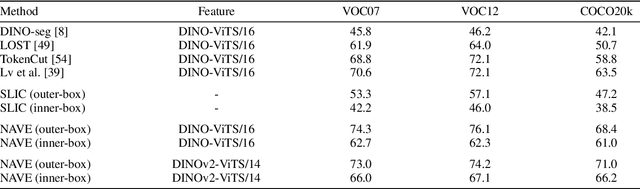
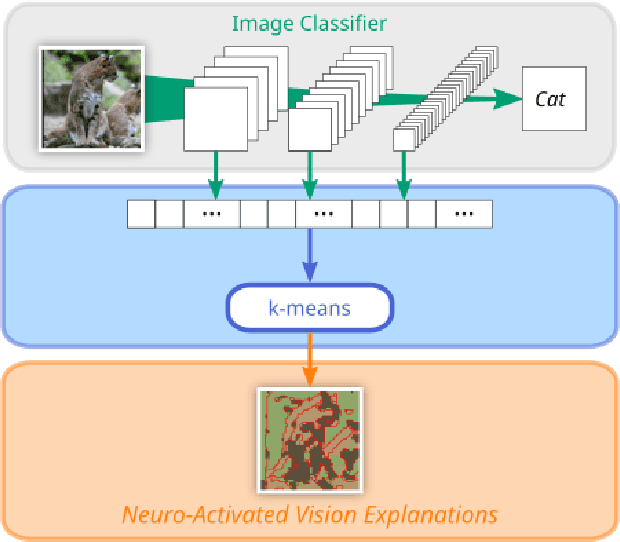

Recent developments in the field of explainable artificial intelligence (XAI) for vision models investigate the information extracted by their feature encoder. We contribute to this effort and propose Neuro-Activated Vision Explanations (NAVE), which extracts the information captured by the encoder by clustering the feature activations of the frozen network to be explained. The method does not aim to explain the model's prediction but to answer questions such as which parts of the image are processed similarly or which information is kept in deeper layers. Experimentally, we leverage NAVE to show that the training dataset and the level of supervision affect which concepts are captured. In addition, our method reveals the impact of registers on vision transformers (ViT) and the information saturation caused by the watermark Clever Hans effect in the training set.
Explainable AI needs formal notions of explanation correctness
Sep 26, 2024The use of machine learning (ML) in critical domains such as medicine poses risks and requires regulation. One requirement is that decisions of ML systems in high-risk applications should be human-understandable. The field of "explainable artificial intelligence" (XAI) seemingly addresses this need. However, in its current form, XAI is unfit to provide quality control for ML; it itself needs scrutiny. Popular XAI methods cannot reliably answer important questions about ML models, their training data, or a given test input. We recapitulate results demonstrating that popular XAI methods systematically attribute importance to input features that are independent of the prediction target. This limits their utility for purposes such as model and data (in)validation, model improvement, and scientific discovery. We argue that the fundamental reason for this limitation is that current XAI methods do not address well-defined problems and are not evaluated against objective criteria of explanation correctness. Researchers should formally define the problems they intend to solve first and then design methods accordingly. This will lead to notions of explanation correctness that can be theoretically verified and objective metrics of explanation performance that can be assessed using ground-truth data.
Leveraging Activations for Superpixel Explanations
Jun 07, 2024Saliency methods have become standard in the explanation toolkit of deep neural networks. Recent developments specific to image classifiers have investigated region-based explanations with either new methods or by adapting well-established ones using ad-hoc superpixel algorithms. In this paper, we aim to avoid relying on these segmenters by extracting a segmentation from the activations of a deep neural network image classifier without fine-tuning the network. Our so-called Neuro-Activated Superpixels (NAS) can isolate the regions of interest in the input relevant to the model's prediction, which boosts high-threshold weakly supervised object localization performance. This property enables the semi-supervised semantic evaluation of saliency methods. The aggregation of NAS with existing saliency methods eases their interpretation and reveals the inconsistencies of the widely used area under the relevance curve metric.
EXACT: Towards a platform for empirically benchmarking Machine Learning model explanation methods
May 20, 2024The evolving landscape of explainable artificial intelligence (XAI) aims to improve the interpretability of intricate machine learning (ML) models, yet faces challenges in formalisation and empirical validation, being an inherently unsupervised process. In this paper, we bring together various benchmark datasets and novel performance metrics in an initial benchmarking platform, the Explainable AI Comparison Toolkit (EXACT), providing a standardised foundation for evaluating XAI methods. Our datasets incorporate ground truth explanations for class-conditional features, and leveraging novel quantitative metrics, this platform assesses the performance of post-hoc XAI methods in the quality of the explanations they produce. Our recent findings have highlighted the limitations of popular XAI methods, as they often struggle to surpass random baselines, attributing significance to irrelevant features. Moreover, we show the variability in explanations derived from different equally performing model architectures. This initial benchmarking platform therefore aims to allow XAI researchers to test and assure the high quality of their newly developed methods.
Pantypes: Diverse Representatives for Self-Explainable Models
Mar 14, 2024Prototypical self-explainable classifiers have emerged to meet the growing demand for interpretable AI systems. These classifiers are designed to incorporate high transparency in their decisions by basing inference on similarity with learned prototypical objects. While these models are designed with diversity in mind, the learned prototypes often do not sufficiently represent all aspects of the input distribution, particularly those in low density regions. Such lack of sufficient data representation, known as representation bias, has been associated with various detrimental properties related to machine learning diversity and fairness. In light of this, we introduce pantypes, a new family of prototypical objects designed to capture the full diversity of the input distribution through a sparse set of objects. We show that pantypes can empower prototypical self-explainable models by occupying divergent regions of the latent space and thus fostering high diversity, interpretability and fairness.
Joint Optimization of an Autoencoder for Clustering and Embedding
Dec 07, 2020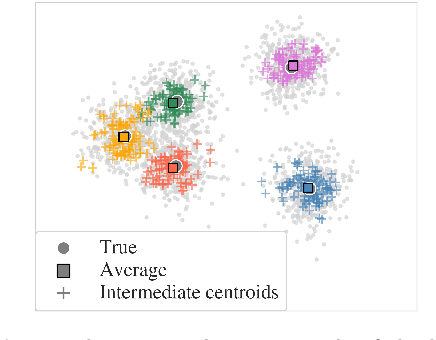

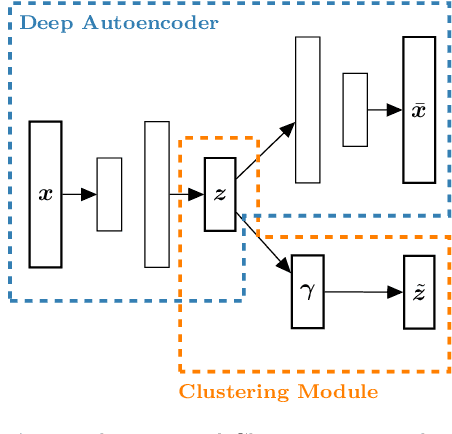
Incorporating k-means-like clustering techniques into (deep) autoencoders constitutes an interesting idea as the clustering may exploit the learned similarities in the embedding to compute a non-linear grouping of data at-hand. Unfortunately, the resulting contributions are often limited by ad-hoc choices, decoupled optimization problems and other issues. We present a theoretically-driven deep clustering approach that does not suffer from these limitations and allows for joint optimization of clustering and embedding. The network in its simplest form is derived from a Gaussian mixture model and can be incorporated seamlessly into deep autoencoders for state-of-the-art performance.