 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining the Impact of Training on Vision Models via Activation Clustering
Paper and Code
Nov 29, 2024
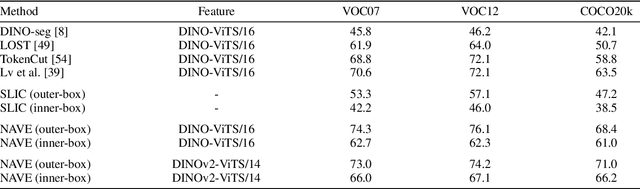
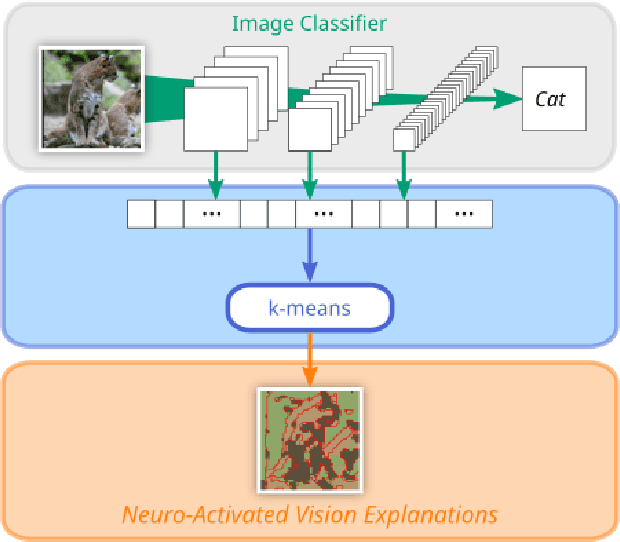

Recent developments in the field of explainable artificial intelligence (XAI) for vision models investigate the information extracted by their feature encoder. We contribute to this effort and propose Neuro-Activated Vision Explanations (NAVE), which extracts the information captured by the encoder by clustering the feature activations of the frozen network to be explained. The method does not aim to explain the model's prediction but to answer questions such as which parts of the image are processed similarly or which information is kept in deeper layers. Experimentally, we leverage NAVE to show that the training dataset and the level of supervision affect which concepts are captured. In addition, our method reveals the impact of registers on vision transformers (ViT) and the information saturation caused by the watermark Clever Hans effect in the training set.