 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining the Impact of Training on Vision Models via Activation Clustering
Nov 29, 2024
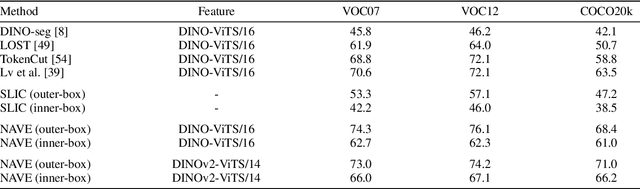
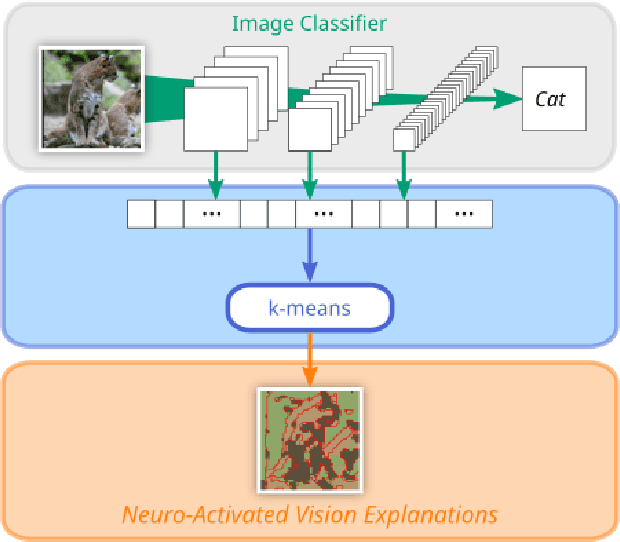

Recent developments in the field of explainable artificial intelligence (XAI) for vision models investigate the information extracted by their feature encoder. We contribute to this effort and propose Neuro-Activated Vision Explanations (NAVE), which extracts the information captured by the encoder by clustering the feature activations of the frozen network to be explained. The method does not aim to explain the model's prediction but to answer questions such as which parts of the image are processed similarly or which information is kept in deeper layers. Experimentally, we leverage NAVE to show that the training dataset and the level of supervision affect which concepts are captured. In addition, our method reveals the impact of registers on vision transformers (ViT) and the information saturation caused by the watermark Clever Hans effect in the training set.
Leveraging Activations for Superpixel Explanations
Jun 07, 2024Saliency methods have become standard in the explanation toolkit of deep neural networks. Recent developments specific to image classifiers have investigated region-based explanations with either new methods or by adapting well-established ones using ad-hoc superpixel algorithms. In this paper, we aim to avoid relying on these segmenters by extracting a segmentation from the activations of a deep neural network image classifier without fine-tuning the network. Our so-called Neuro-Activated Superpixels (NAS) can isolate the regions of interest in the input relevant to the model's prediction, which boosts high-threshold weakly supervised object localization performance. This property enables the semi-supervised semantic evaluation of saliency methods. The aggregation of NAS with existing saliency methods eases their interpretation and reveals the inconsistencies of the widely used area under the relevance curve metric.
Self-Supervised Siamese Autoencoders
Apr 05, 2023Fully supervised models often require large amounts of labeled training data, which tends to be costly and hard to acquire. In contrast, self-supervised representation learning reduces the amount of labeled data needed for achieving the same or even higher downstream performance. The goal is to pre-train deep neural networks on a self-supervised task such that afterwards the networks are able to extract meaningful features from raw input data. These features are then used as inputs in downstream tasks, such as image classification. Previously, autoencoders and Siamese networks such as SimSiam have been successfully employed in those tasks. Yet, challenges remain, such as matching characteristics of the features (e.g., level of detail) to the given task and data set. In this paper, we present a new self-supervised method that combines the benefits of Siamese architectures and denoising autoencoders. We show that our model, called SidAE (Siamese denoising autoencoder), outperforms two self-supervised baselines across multiple data sets, settings, and scenarios. Crucially, this includes conditions in which only a small amount of labeled data is available.
Principled Interpolation in Normalizing Flows
Oct 22, 2020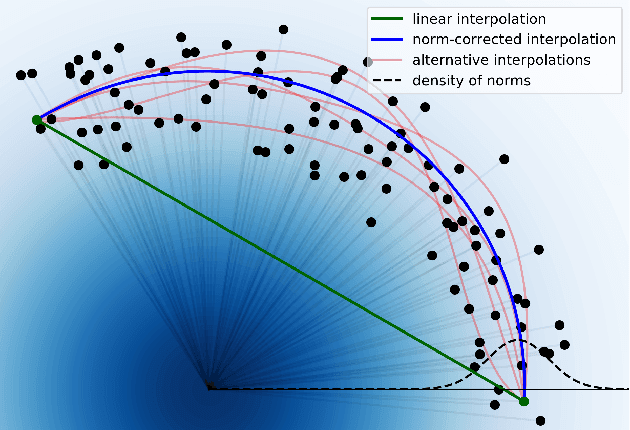
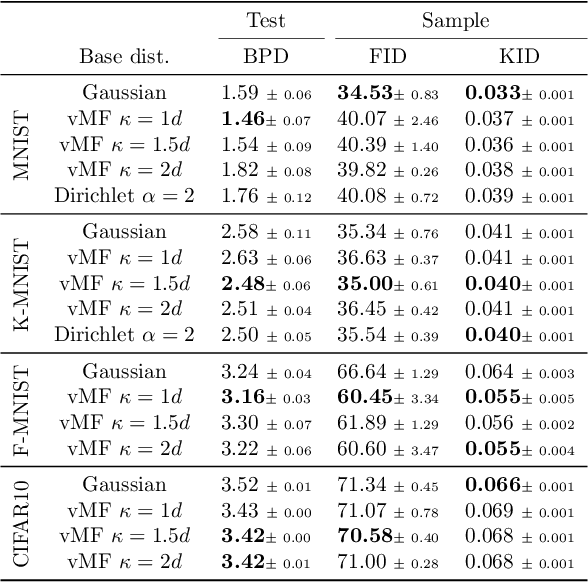

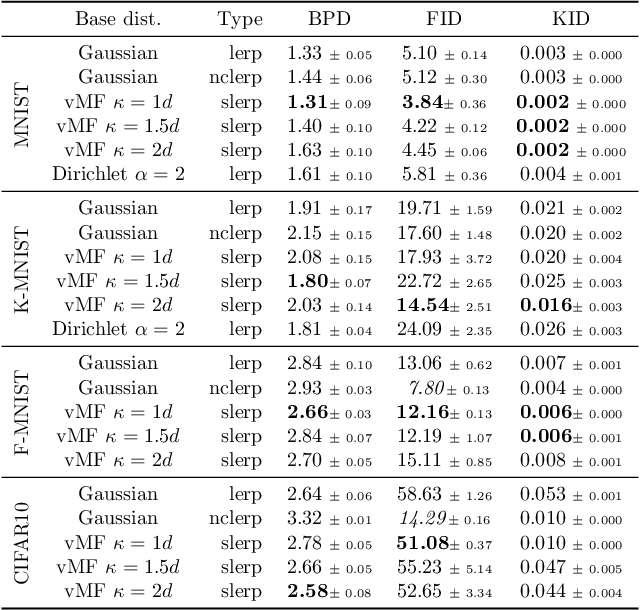
Generative models based on normalizing flows are very successful in modeling complex data distributions using simpler ones. However, straightforward linear interpolations show unexpected side effects, as interpolation paths lie outside the area where samples are observed. This is caused by the standard choice of Gaussian base distributions and can be seen in the norms of the interpolated samples. This observation suggests that correcting the norm should generally result in better interpolations, but it is not clear how to correct the norm in an unambiguous way. In this paper, we solve this issue by enforcing a fixed norm and, hence, change the base distribution, to allow for a principled way of interpolation. Specifically, we use the Dirichlet and von Mises-Fisher base distributions. Our experimental results show superior performance in terms of bits per dimension, Fr\'echet Inception Distance (FID), and Kernel Inception Distance (KID) scores for interpolation, while maintaining the same generative performance.
Link Prediction in Dynamic Graphs for Recommendation
Nov 17, 2018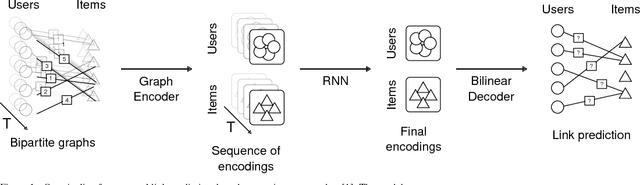
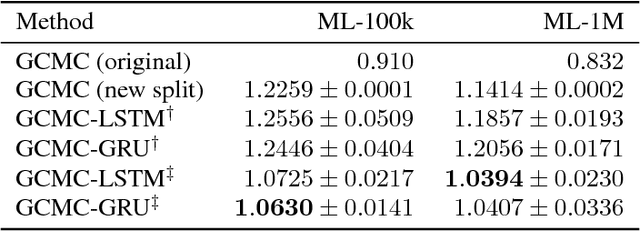
Recent advances in employing neural networks on graph domains helped push the state of the art in link prediction tasks, particularly in recommendation services. However, the use of temporal contextual information, often modeled as dynamic graphs that encode the evolution of user-item relationships over time, has been overlooked in link prediction problems. In this paper, we consider the hypothesis that leveraging such information enables models to make better predictions, proposing a new neural network approach for this. Our experiments, performed on the widely used ML-100k and ML-1M datasets, show that our approach produces better predictions in scenarios where the pattern of user-item relationships change over time. In addition, they suggest that existing approaches are significantly impacted by those changes.
Exploiting ConvNet Diversity for Flooding Identification
Jun 05, 2018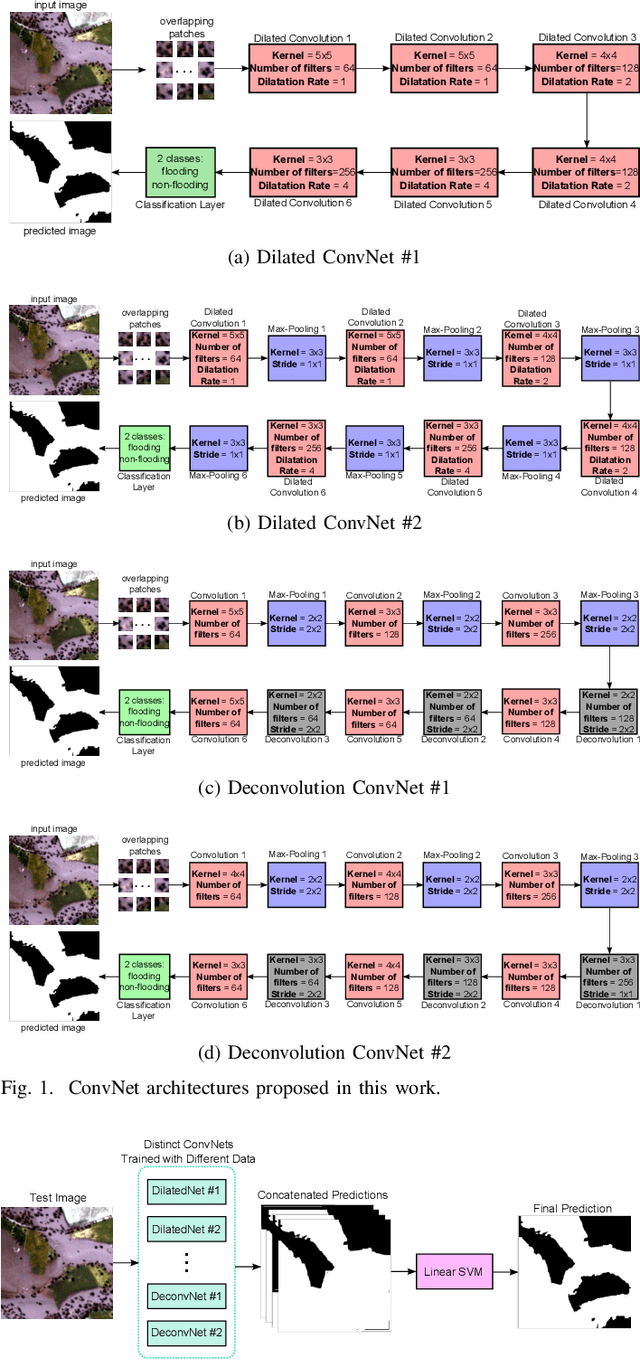


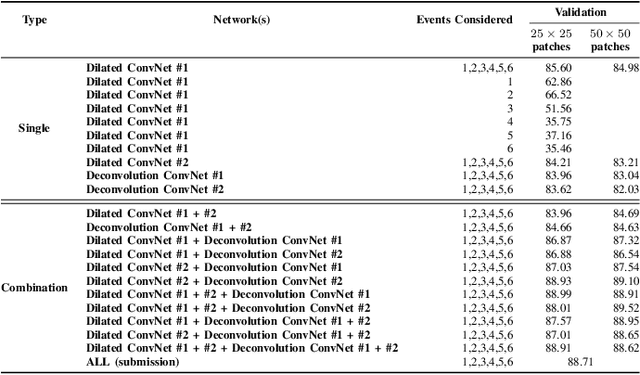
Flooding is the world's most costly type of natural disaster in terms of both economic losses and human causalities. A first and essential procedure towards flood monitoring is based on identifying the area most vulnerable to flooding, which gives authorities relevant regions to focus. In this work, we propose several methods to perform flooding identification in high-resolution remote sensing images using deep learning. Specifically, some proposed techniques are based upon unique networks, such as dilated and deconvolutional ones, while other was conceived to exploit diversity of distinct networks in order to extract the maximum performance of each classifier. Evaluation of the proposed algorithms were conducted in a high-resolution remote sensing dataset. Results show that the proposed algorithms outperformed several state-of-the-art baselines, providing improvements ranging from 1 to 4% in terms of the Jaccard Index.