 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting ConvNet Diversity for Flooding Identification
Jun 05, 2018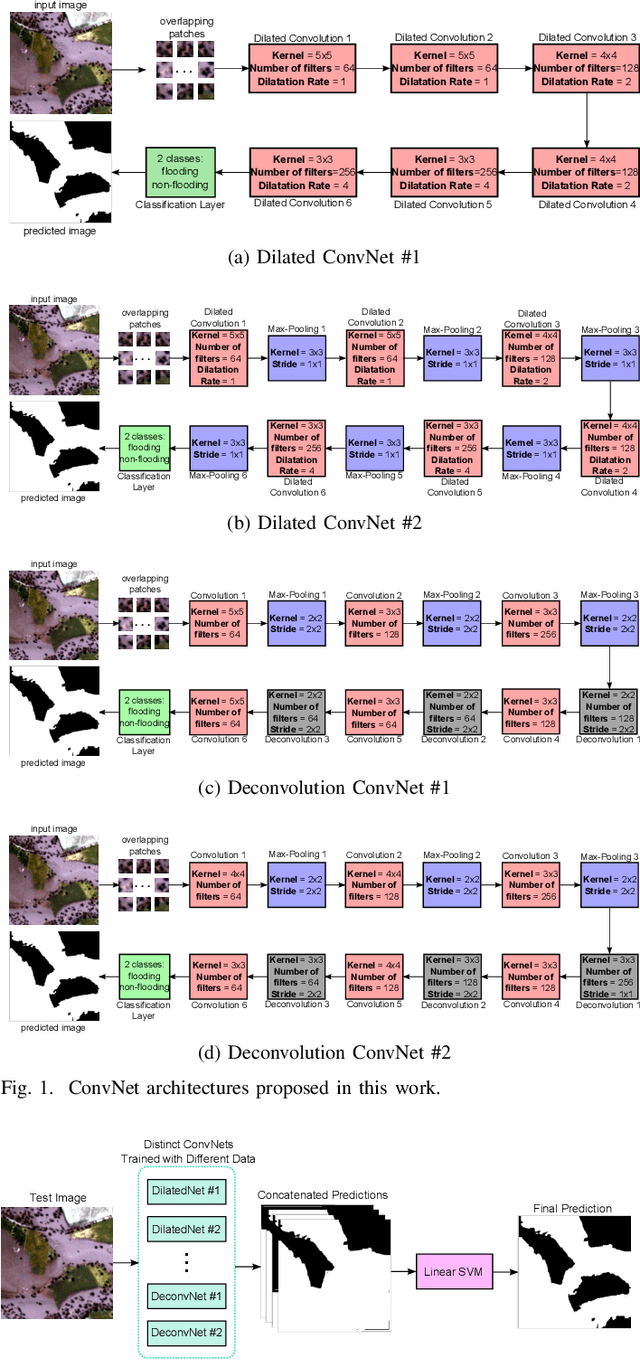


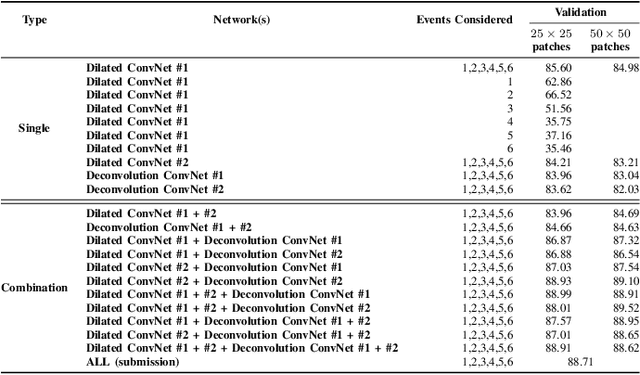
Flooding is the world's most costly type of natural disaster in terms of both economic losses and human causalities. A first and essential procedure towards flood monitoring is based on identifying the area most vulnerable to flooding, which gives authorities relevant regions to focus. In this work, we propose several methods to perform flooding identification in high-resolution remote sensing images using deep learning. Specifically, some proposed techniques are based upon unique networks, such as dilated and deconvolutional ones, while other was conceived to exploit diversity of distinct networks in order to extract the maximum performance of each classifier. Evaluation of the proposed algorithms were conducted in a high-resolution remote sensing dataset. Results show that the proposed algorithms outperformed several state-of-the-art baselines, providing improvements ranging from 1 to 4% in terms of the Jaccard Index.
Human activity recognition from mobile inertial sensors using recurrence plots
Dec 05, 2017


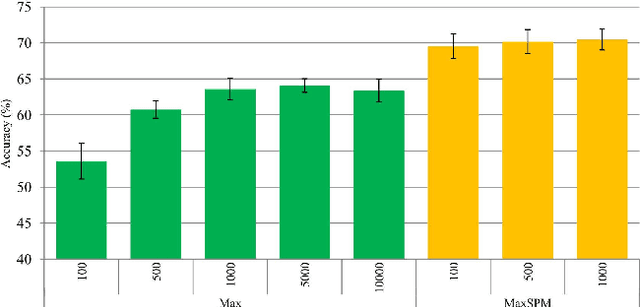
Inertial sensors are present in most mobile devices nowadays and such devices are used by people during most of their daily activities. In this paper, we present an approach for human activity recognition based on inertial sensors by employing recurrence plots (RP) and visual descriptors. The pipeline of the proposed approach is the following: compute RPs from sensor data, compute visual features from RPs and use them in a machine learning protocol. As RPs generate texture visual patterns, we transform the problem of sensor data classification to a problem of texture classification. Experiments for classifying human activities based on accelerometer data showed that the proposed approach obtains the highest accuracies, outperforming time- and frequency-domain features directly extracted from sensor data. The best results are obtained when using RGB RPs, in which each RGB channel corresponds to the RP of an independent accelerometer axis.
Bag of Attributes for Video Event Retrieval
Jul 18, 2016



In this paper, we present the Bag-of-Attributes (BoA) model for video representation aiming at video event retrieval. The BoA model is based on a semantic feature space for representing videos, resulting in high-level video feature vectors. For creating a semantic space, i.e., the attribute space, we can train a classifier using a labeled image dataset, obtaining a classification model that can be understood as a high-level codebook. This model is used to map low-level frame vectors into high-level vectors (e.g., classifier probability scores). Then, we apply pooling operations on the frame vectors to create the final bag of attributes for the video. In the BoA representation, each dimension corresponds to one category (or attribute) of the semantic space. Other interesting properties are: compactness, flexibility regarding the classifier, and ability to encode multiple semantic concepts in a single video representation. Our experiments considered the semantic space created by a deep convolutional neural network (OverFeat) pre-trained on 1000 object categories of ImageNet. OverFeat was then used to classify each video frame and max pooling combined the frame vectors in the BoA representation for the video. Results using BoA outperformed the baselines with statistical significance in the task of video event retrieval using the EVVE dataset.
Towards Better Exploiting Convolutional Neural Networks for Remote Sensing Scene Classification
Feb 04, 2016

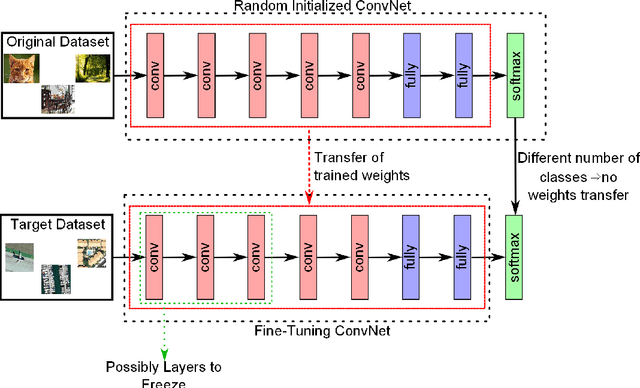

We present an analysis of three possible strategies for exploiting the power of existing convolutional neural networks (ConvNets) in different scenarios from the ones they were trained: full training, fine tuning, and using ConvNets as feature extractors. In many applications, especially including remote sensing, it is not feasible to fully design and train a new ConvNet, as this usually requires a considerable amount of labeled data and demands high computational costs. Therefore, it is important to understand how to obtain the best profit from existing ConvNets. We perform experiments with six popular ConvNets using three remote sensing datasets. We also compare ConvNets in each strategy with existing descriptors and with state-of-the-art baselines. Results point that fine tuning tends to be the best performing strategy. In fact, using the features from the fine-tuned ConvNet with linear SVM obtains the best results. We also achieved state-of-the-art results for the three datasets used.
Semantic Diversity versus Visual Diversity in Visual Dictionaries
Nov 20, 2015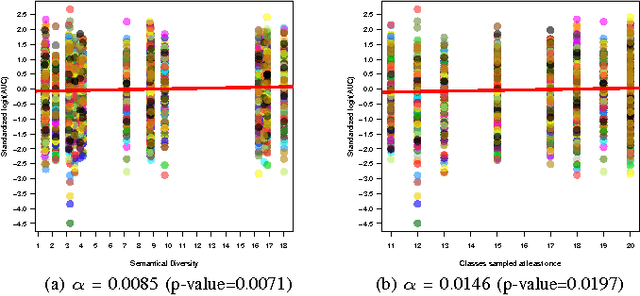
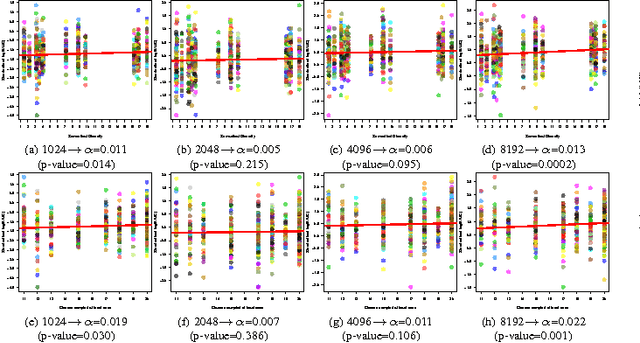
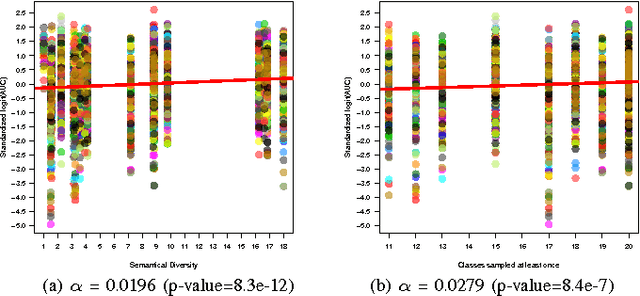
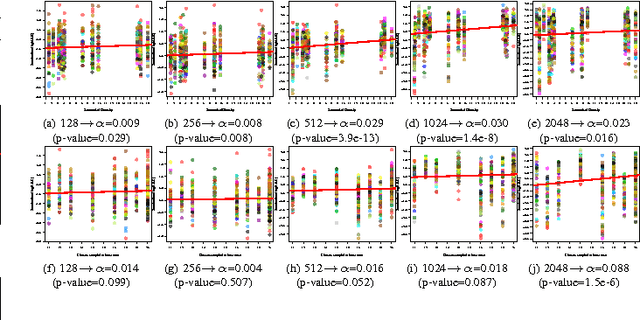
Visual dictionaries are a critical component for image classification/retrieval systems based on the bag-of-visual-words (BoVW) model. Dictionaries are usually learned without supervision from a training set of images sampled from the collection of interest. However, for large, general-purpose, dynamic image collections (e.g., the Web), obtaining a representative sample in terms of semantic concepts is not straightforward. In this paper, we evaluate the impact of semantics in the dictionary quality, aiming at verifying the importance of semantic diversity in relation visual diversity for visual dictionaries. In the experiments, we vary the amount of classes used for creating the dictionary and then compute different BoVW descriptors, using multiple codebook sizes and different coding and pooling methods (standard BoVW and Fisher Vectors). Results for image classification show that as visual dictionaries are based on low-level visual appearances, visual diversity is more important than semantic diversity. Our conclusions open the opportunity to alleviate the burden in generating visual dictionaries as we need only a visually diverse set of images instead of the whole collection to create a good dictionary.
Bag-of-Genres for Video Genre Retrieval
May 30, 2015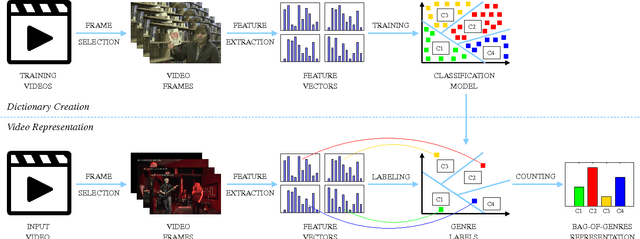

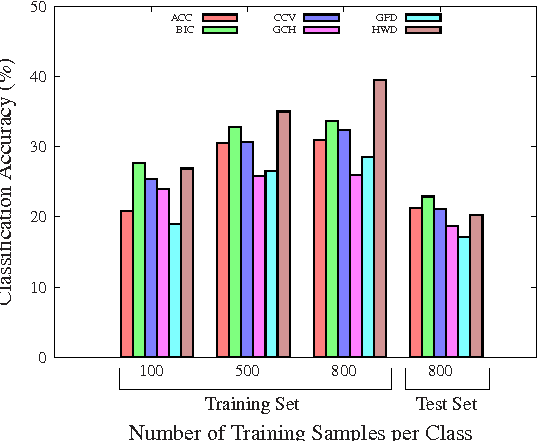
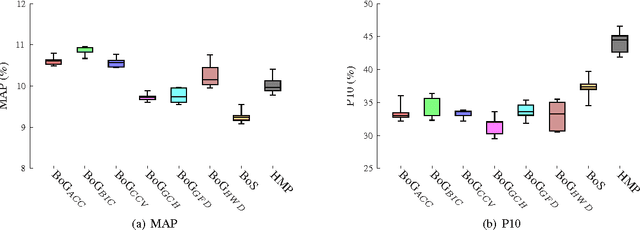
This paper presents a higher level representation for videos aiming at video genre retrieval. In video genre retrieval, there is a challenge that videos may comprise multiple categories, for instance, news videos may be composed of sports, documentary, and action. Therefore, it is interesting to encode the distribution of such genres in a compact and effective manner. We propose to create a visual dictionary using a genre classifier. Each visual word in the proposed model corresponds to a region in the classification space determined by the classifier's model learned on the training frames. Therefore, the video feature vector contains a summary of the activations of each genre in its contents. We evaluate the bag-of-genres model for video genre retrieval, using the dataset of MediaEval Tagging Task of 2012. Results show that the proposed model increases the quality of the representation being more compact than existing features.