 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBag of Attributes for Video Event Retrieval
Jul 18, 2016



In this paper, we present the Bag-of-Attributes (BoA) model for video representation aiming at video event retrieval. The BoA model is based on a semantic feature space for representing videos, resulting in high-level video feature vectors. For creating a semantic space, i.e., the attribute space, we can train a classifier using a labeled image dataset, obtaining a classification model that can be understood as a high-level codebook. This model is used to map low-level frame vectors into high-level vectors (e.g., classifier probability scores). Then, we apply pooling operations on the frame vectors to create the final bag of attributes for the video. In the BoA representation, each dimension corresponds to one category (or attribute) of the semantic space. Other interesting properties are: compactness, flexibility regarding the classifier, and ability to encode multiple semantic concepts in a single video representation. Our experiments considered the semantic space created by a deep convolutional neural network (OverFeat) pre-trained on 1000 object categories of ImageNet. OverFeat was then used to classify each video frame and max pooling combined the frame vectors in the BoA representation for the video. Results using BoA outperformed the baselines with statistical significance in the task of video event retrieval using the EVVE dataset.
Bag-of-Genres for Video Genre Retrieval
May 30, 2015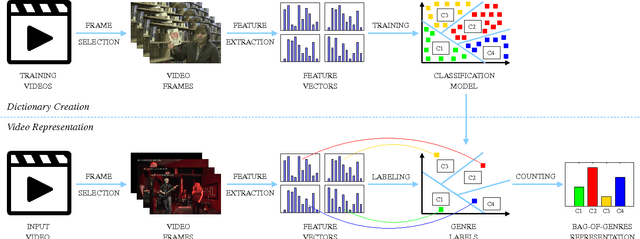

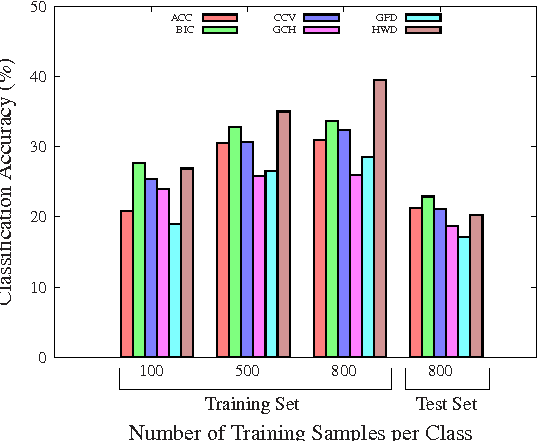
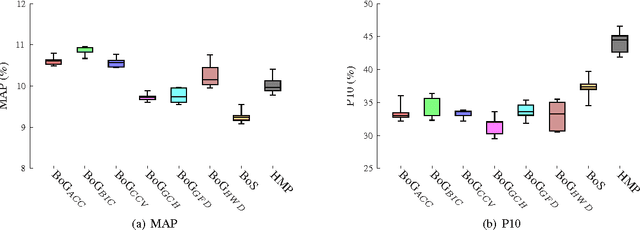
This paper presents a higher level representation for videos aiming at video genre retrieval. In video genre retrieval, there is a challenge that videos may comprise multiple categories, for instance, news videos may be composed of sports, documentary, and action. Therefore, it is interesting to encode the distribution of such genres in a compact and effective manner. We propose to create a visual dictionary using a genre classifier. Each visual word in the proposed model corresponds to a region in the classification space determined by the classifier's model learned on the training frames. Therefore, the video feature vector contains a summary of the activations of each genre in its contents. We evaluate the bag-of-genres model for video genre retrieval, using the dataset of MediaEval Tagging Task of 2012. Results show that the proposed model increases the quality of the representation being more compact than existing features.