 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Soft Computing Approach for Selecting and Combining Spectral Bands
Nov 10, 2020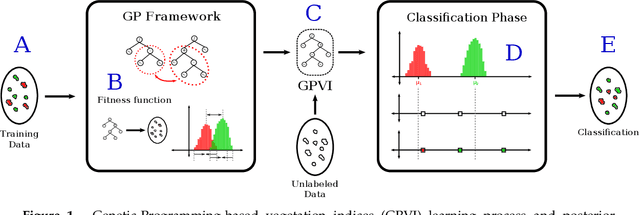

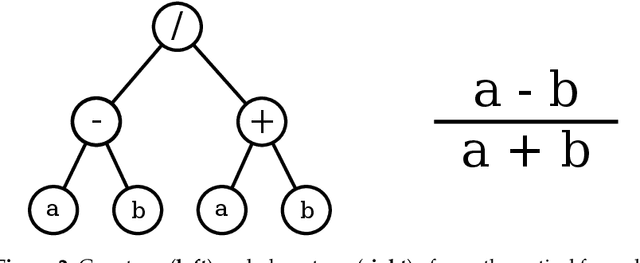

We introduce a soft computing approach for automatically selecting and combining indices from remote sensing multispectral images that can be used for classification tasks. The proposed approach is based on a Genetic-Programming (GP) framework, a technique successfully used in a wide variety of optimization problems. Through GP, it is possible to learn indices that maximize the separability of samples from two different classes. Once the indices specialized for all the pairs of classes are obtained, they are used in pixelwise classification tasks. We used the GP-based solution to evaluate complex classification problems, such as those that are related to the discrimination of vegetation types within and between tropical biomes. Using time series defined in terms of the learned spectral indices, we show that the GP framework leads to superior results than other indices that are used to discriminate and classify tropical biomes.
* MDPI Remote Sensing - Special Issue "Current Limits and New Challenges and Opportunities in Soft Computing, Machine Learning and Computational Intelligence for Remote Sensing"
Principled Interpolation in Normalizing Flows
Oct 22, 2020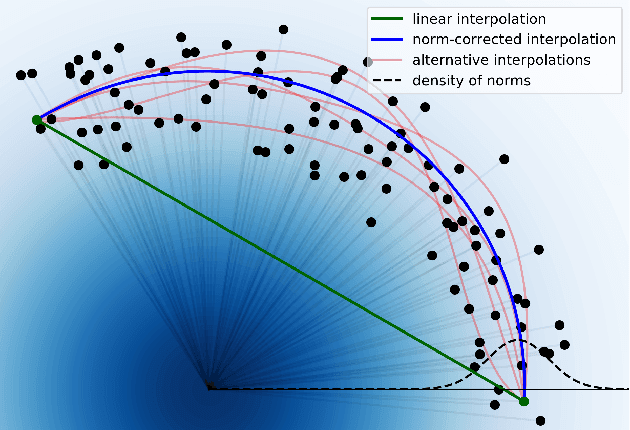
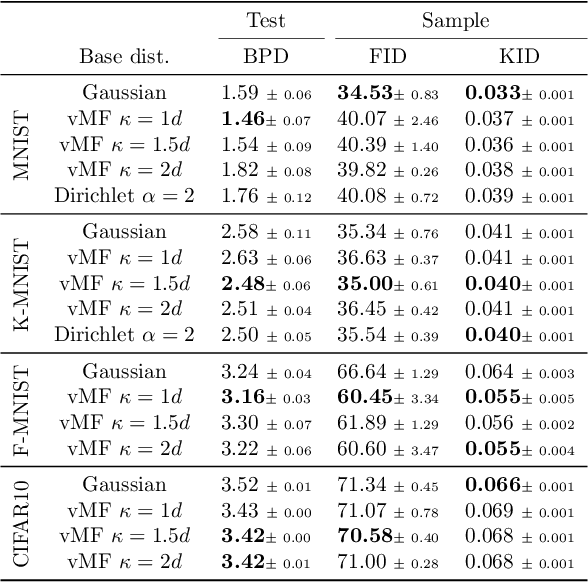

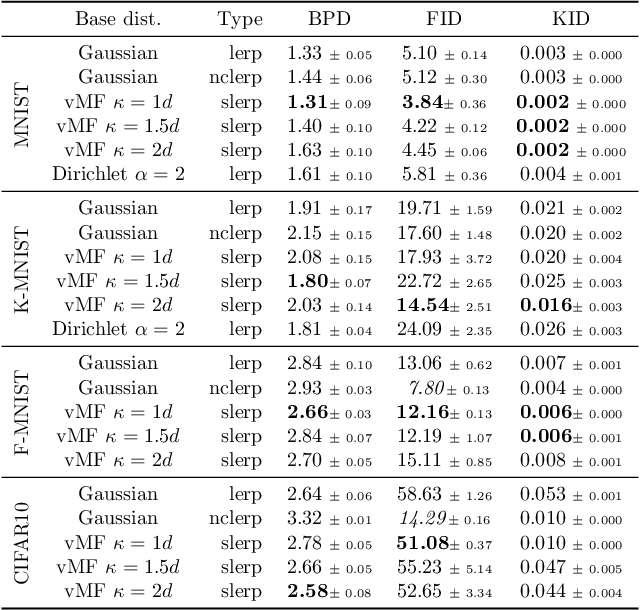
Generative models based on normalizing flows are very successful in modeling complex data distributions using simpler ones. However, straightforward linear interpolations show unexpected side effects, as interpolation paths lie outside the area where samples are observed. This is caused by the standard choice of Gaussian base distributions and can be seen in the norms of the interpolated samples. This observation suggests that correcting the norm should generally result in better interpolations, but it is not clear how to correct the norm in an unambiguous way. In this paper, we solve this issue by enforcing a fixed norm and, hence, change the base distribution, to allow for a principled way of interpolation. Specifically, we use the Dirichlet and von Mises-Fisher base distributions. Our experimental results show superior performance in terms of bits per dimension, Fr\'echet Inception Distance (FID), and Kernel Inception Distance (KID) scores for interpolation, while maintaining the same generative performance.
Parallax Motion Effect Generation Through Instance Segmentation And Depth Estimation
Oct 06, 2020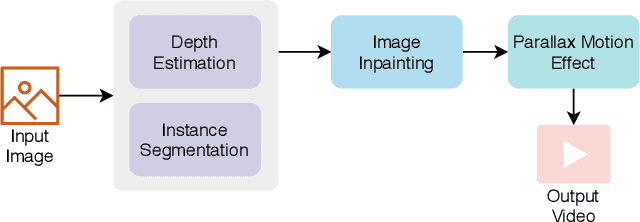



Stereo vision is a growing topic in computer vision due to the innumerable opportunities and applications this technology offers for the development of modern solutions, such as virtual and augmented reality applications. To enhance the user's experience in three-dimensional virtual environments, the motion parallax estimation is a promising technique to achieve this objective. In this paper, we propose an algorithm for generating parallax motion effects from a single image, taking advantage of state-of-the-art instance segmentation and depth estimation approaches. This work also presents a comparison against such algorithms to investigate the trade-off between efficiency and quality of the parallax motion effects, taking into consideration a multi-task learning network capable of estimating instance segmentation and depth estimation at once. Experimental results and visual quality assessment indicate that the PyD-Net network (depth estimation) combined with Mask R-CNN or FBNet networks (instance segmentation) can produce parallax motion effects with good visual quality.
* 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates
Spatio-Temporal Vegetation Pixel Classification By Using Convolutional Networks
Mar 02, 2019



Plant phenology studies rely on long-term monitoring of life cycles of plants. High-resolution unmanned aerial vehicles (UAVs) and near-surface technologies have been used for plant monitoring, demanding the creation of methods capable of locating and identifying plant species through time and space. However, this is a challenging task given the high volume of data, the constant data missing from temporal dataset, the heterogeneity of temporal profiles, the variety of plant visual patterns, and the unclear definition of individuals' boundaries in plant communities. In this letter, we propose a novel method, suitable for phenological monitoring, based on Convolutional Networks (ConvNets) to perform spatio-temporal vegetation pixel-classification on high resolution images. We conducted a systematic evaluation using high-resolution vegetation image datasets associated with the Brazilian Cerrado biome. Experimental results show that the proposed approach is effective, overcoming other spatio-temporal pixel-classification strategies.
Link Prediction in Dynamic Graphs for Recommendation
Nov 17, 2018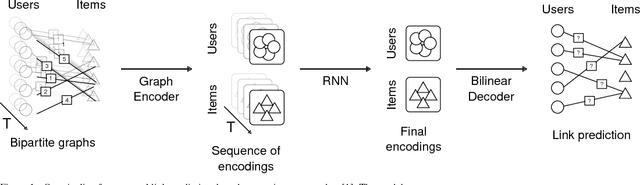
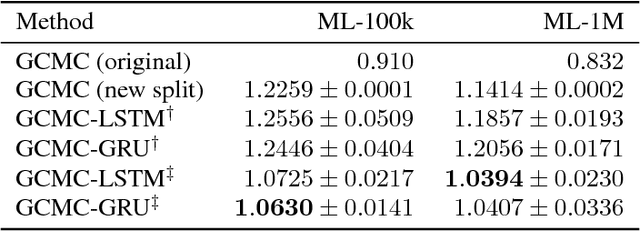
Recent advances in employing neural networks on graph domains helped push the state of the art in link prediction tasks, particularly in recommendation services. However, the use of temporal contextual information, often modeled as dynamic graphs that encode the evolution of user-item relationships over time, has been overlooked in link prediction problems. In this paper, we consider the hypothesis that leveraging such information enables models to make better predictions, proposing a new neural network approach for this. Our experiments, performed on the widely used ML-100k and ML-1M datasets, show that our approach produces better predictions in scenarios where the pattern of user-item relationships change over time. In addition, they suggest that existing approaches are significantly impacted by those changes.
Exploiting ConvNet Diversity for Flooding Identification
Jun 05, 2018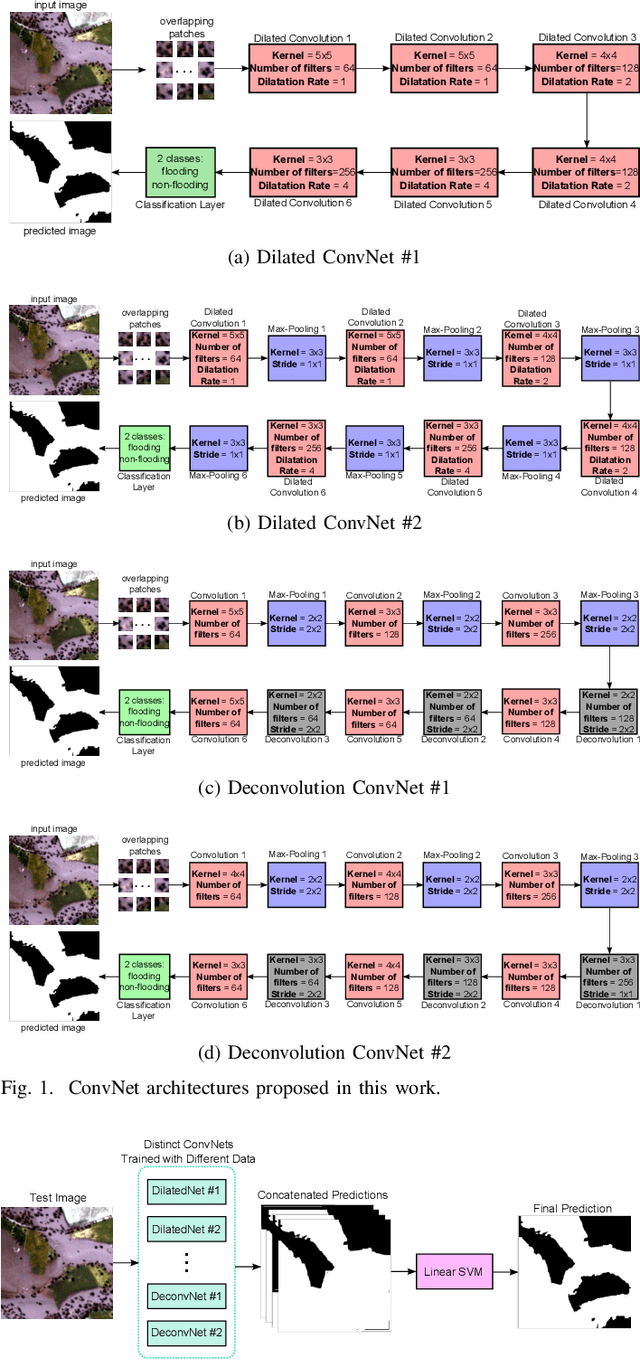


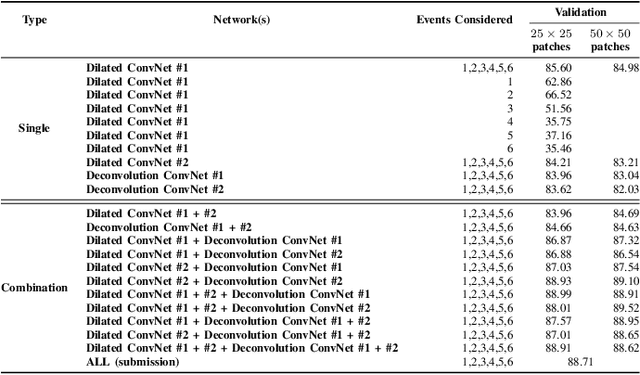
Flooding is the world's most costly type of natural disaster in terms of both economic losses and human causalities. A first and essential procedure towards flood monitoring is based on identifying the area most vulnerable to flooding, which gives authorities relevant regions to focus. In this work, we propose several methods to perform flooding identification in high-resolution remote sensing images using deep learning. Specifically, some proposed techniques are based upon unique networks, such as dilated and deconvolutional ones, while other was conceived to exploit diversity of distinct networks in order to extract the maximum performance of each classifier. Evaluation of the proposed algorithms were conducted in a high-resolution remote sensing dataset. Results show that the proposed algorithms outperformed several state-of-the-art baselines, providing improvements ranging from 1 to 4% in terms of the Jaccard Index.
Semantic Diversity versus Visual Diversity in Visual Dictionaries
Nov 20, 2015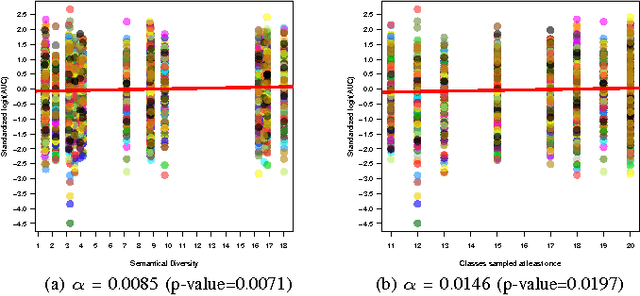
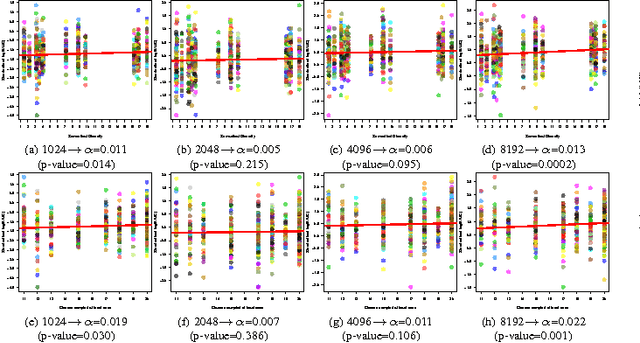
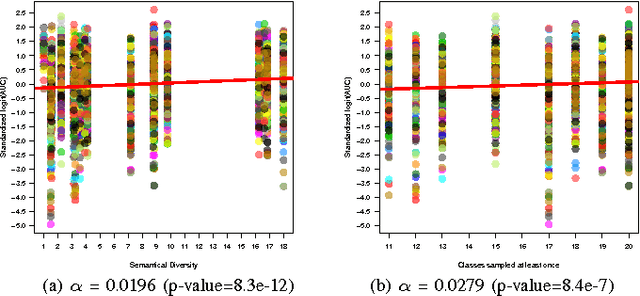
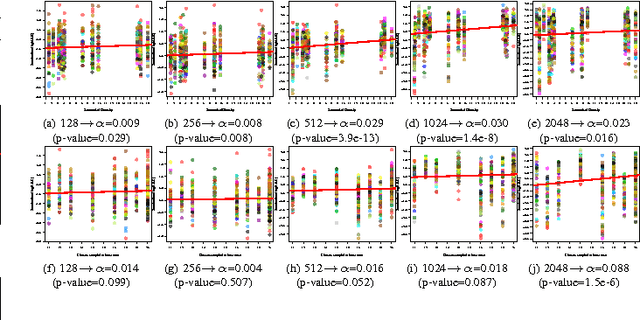
Visual dictionaries are a critical component for image classification/retrieval systems based on the bag-of-visual-words (BoVW) model. Dictionaries are usually learned without supervision from a training set of images sampled from the collection of interest. However, for large, general-purpose, dynamic image collections (e.g., the Web), obtaining a representative sample in terms of semantic concepts is not straightforward. In this paper, we evaluate the impact of semantics in the dictionary quality, aiming at verifying the importance of semantic diversity in relation visual diversity for visual dictionaries. In the experiments, we vary the amount of classes used for creating the dictionary and then compute different BoVW descriptors, using multiple codebook sizes and different coding and pooling methods (standard BoVW and Fisher Vectors). Results for image classification show that as visual dictionaries are based on low-level visual appearances, visual diversity is more important than semantic diversity. Our conclusions open the opportunity to alleviate the burden in generating visual dictionaries as we need only a visually diverse set of images instead of the whole collection to create a good dictionary.
Are visual dictionaries generalizable?
May 11, 2012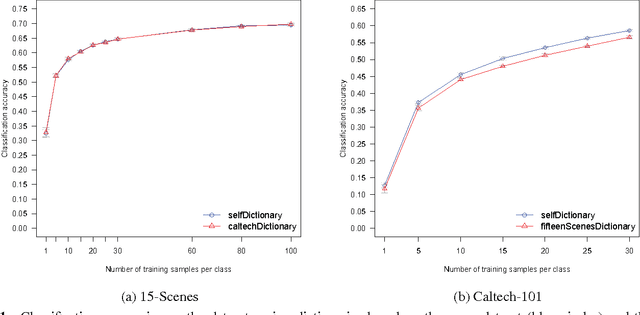
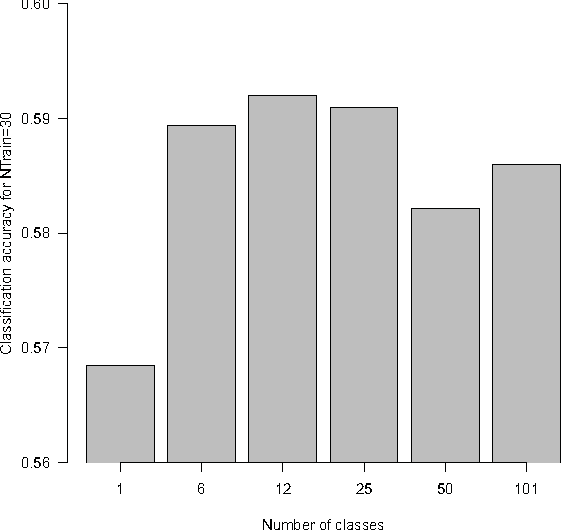
Mid-level features based on visual dictionaries are today a cornerstone of systems for classification and retrieval of images. Those state-of-the-art representations depend crucially on the choice of a codebook (visual dictionary), which is usually derived from the dataset. In general-purpose, dynamic image collections (e.g., the Web), one cannot have the entire collection in order to extract a representative dictionary. However, based on the hypothesis that the dictionary reflects only the diversity of low-level appearances and does not capture semantics, we argue that a dictionary based on a small subset of the data, or even on an entirely different dataset, is able to produce a good representation, provided that the chosen images span a diverse enough portion of the low-level feature space. Our experiments confirm that hypothesis, opening the opportunity to greatly alleviate the burden in generating the codebook, and confirming the feasibility of employing visual dictionaries in large-scale dynamic environments.