 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning multiplane images from single views with self-supervision
Oct 19, 2021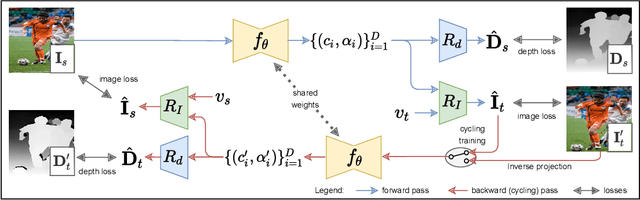
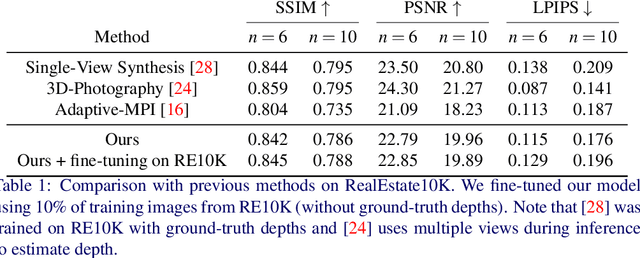


Generating static novel views from an already captured image is a hard task in computer vision and graphics, in particular when the single input image has dynamic parts such as persons or moving objects. In this paper, we tackle this problem by proposing a new framework, called CycleMPI, that is capable of learning a multiplane image representation from single images through a cyclic training strategy for self-supervision. Our framework does not require stereo data for training, therefore it can be trained with massive visual data from the Internet, resulting in a better generalization capability even for very challenging cases. Although our method does not require stereo data for supervision, it reaches results on stereo datasets comparable to the state of the art in a zero-shot scenario. We evaluated our method on RealEstate10K and Mannequin Challenge datasets for view synthesis and presented qualitative results on Places II dataset.
Adaptive Multiplane Image Generation from a Single Internet Picture
Nov 26, 2020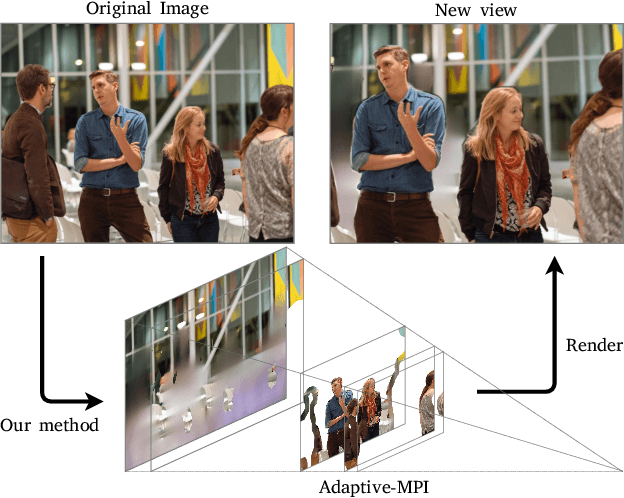
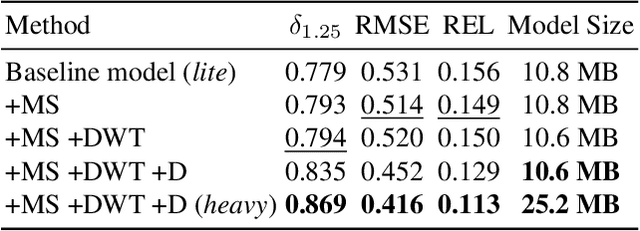
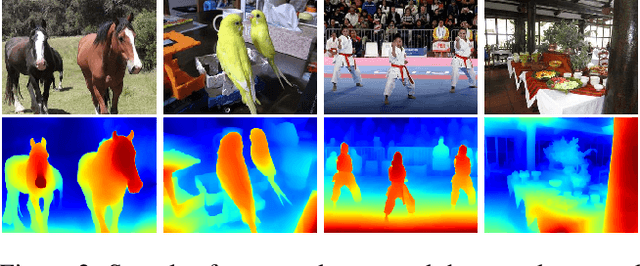
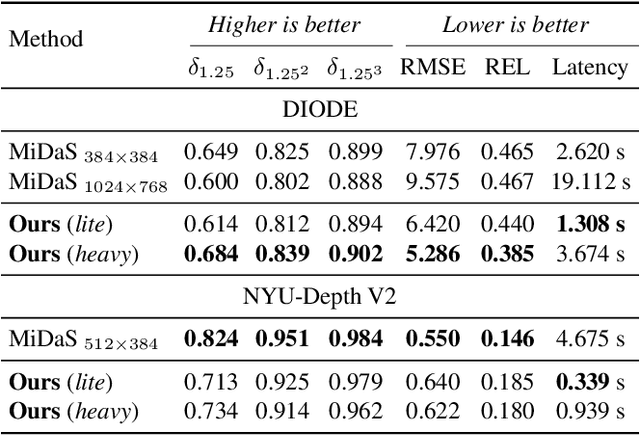
In the last few years, several works have tackled the problem of novel view synthesis from stereo images or even from a single picture. However, previous methods are computationally expensive, specially for high-resolution images. In this paper, we address the problem of generating a multiplane image (MPI) from a single high-resolution picture. We present the adaptive-MPI representation, which allows rendering novel views with low computational requirements. To this end, we propose an adaptive slicing algorithm that produces an MPI with a variable number of image planes. We present a new lightweight CNN for depth estimation, which is learned by knowledge distillation from a larger network. Occluded regions in the adaptive-MPI are inpainted also by a lightweight CNN. We show that our method is capable of producing high-quality predictions with one order of magnitude less parameters compared to previous approaches. The robustness of our method is evidenced on challenging pictures from the Internet.
Parallax Motion Effect Generation Through Instance Segmentation And Depth Estimation
Oct 06, 2020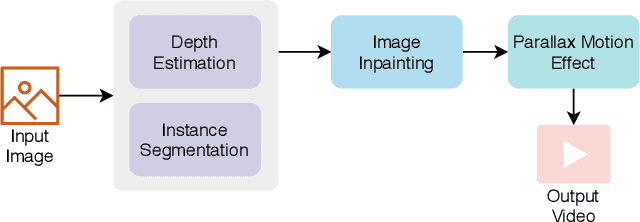



Stereo vision is a growing topic in computer vision due to the innumerable opportunities and applications this technology offers for the development of modern solutions, such as virtual and augmented reality applications. To enhance the user's experience in three-dimensional virtual environments, the motion parallax estimation is a promising technique to achieve this objective. In this paper, we propose an algorithm for generating parallax motion effects from a single image, taking advantage of state-of-the-art instance segmentation and depth estimation approaches. This work also presents a comparison against such algorithms to investigate the trade-off between efficiency and quality of the parallax motion effects, taking into consideration a multi-task learning network capable of estimating instance segmentation and depth estimation at once. Experimental results and visual quality assessment indicate that the PyD-Net network (depth estimation) combined with Mask R-CNN or FBNet networks (instance segmentation) can produce parallax motion effects with good visual quality.
* 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates
2D/3D Pose Estimation and Action Recognition using Multitask Deep Learning
Mar 21, 2018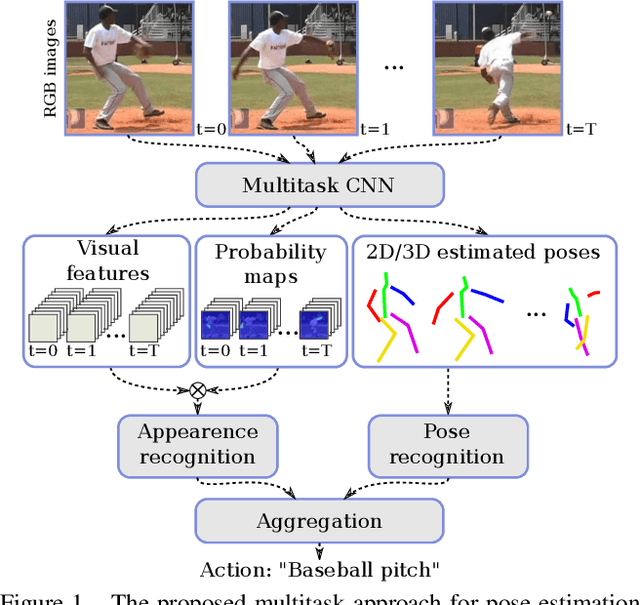


Action recognition and human pose estimation are closely related but both problems are generally handled as distinct tasks in the literature. In this work, we propose a multitask framework for jointly 2D and 3D pose estimation from still images and human action recognition from video sequences. We show that a single architecture can be used to solve the two problems in an efficient way and still achieves state-of-the-art results. Additionally, we demonstrate that optimization from end-to-end leads to significantly higher accuracy than separated learning. The proposed architecture can be trained with data from different categories simultaneously in a seamlessly way. The reported results on four datasets (MPII, Human3.6M, Penn Action and NTU) demonstrate the effectiveness of our method on the targeted tasks.
Human Pose Regression by Combining Indirect Part Detection and Contextual Information
Oct 06, 2017
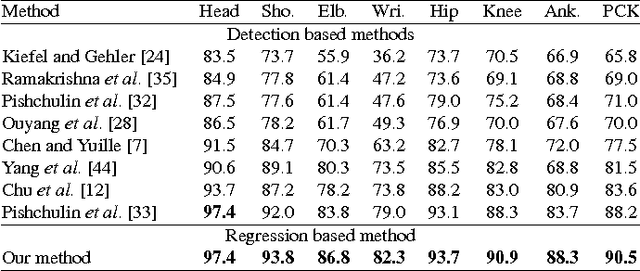


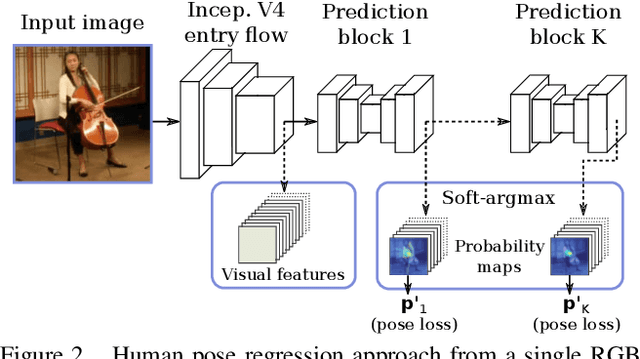
In this paper, we propose an end-to-end trainable regression approach for human pose estimation from still images. We use the proposed Soft-argmax function to convert feature maps directly to joint coordinates, resulting in a fully differentiable framework. Our method is able to learn heat maps representations indirectly, without additional steps of artificial ground truth generation. Consequently, contextual information can be included to the pose predictions in a seamless way. We evaluated our method on two very challenging datasets, the Leeds Sports Poses (LSP) and the MPII Human Pose datasets, reaching the best performance among all the existing regression methods and comparable results to the state-of-the-art detection based approaches.