 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning multiplane images from single views with self-supervision
Oct 19, 2021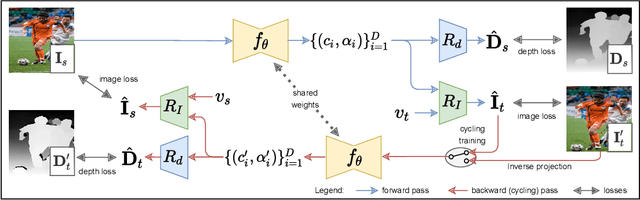
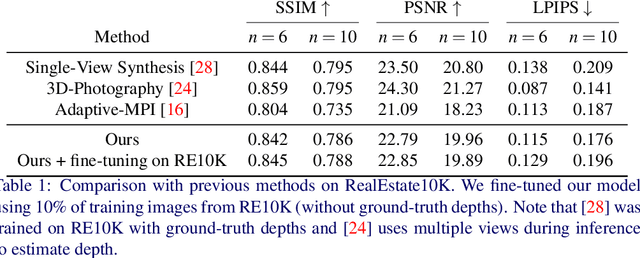


Generating static novel views from an already captured image is a hard task in computer vision and graphics, in particular when the single input image has dynamic parts such as persons or moving objects. In this paper, we tackle this problem by proposing a new framework, called CycleMPI, that is capable of learning a multiplane image representation from single images through a cyclic training strategy for self-supervision. Our framework does not require stereo data for training, therefore it can be trained with massive visual data from the Internet, resulting in a better generalization capability even for very challenging cases. Although our method does not require stereo data for supervision, it reaches results on stereo datasets comparable to the state of the art in a zero-shot scenario. We evaluated our method on RealEstate10K and Mannequin Challenge datasets for view synthesis and presented qualitative results on Places II dataset.
Adaptive Multiplane Image Generation from a Single Internet Picture
Nov 26, 2020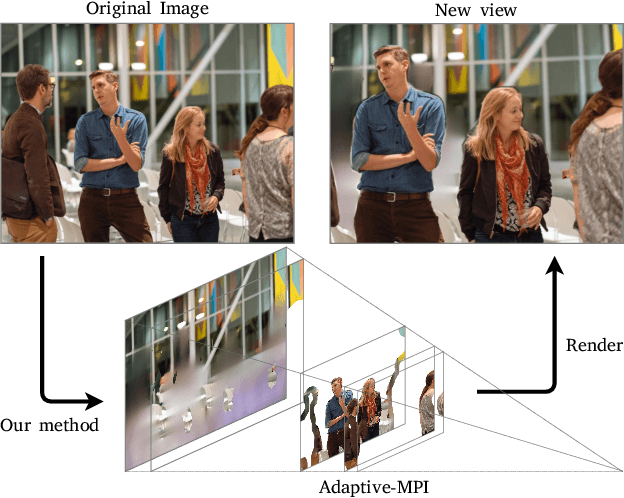
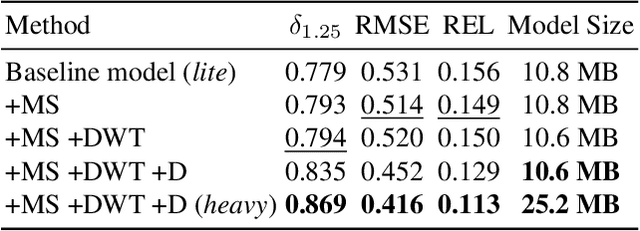
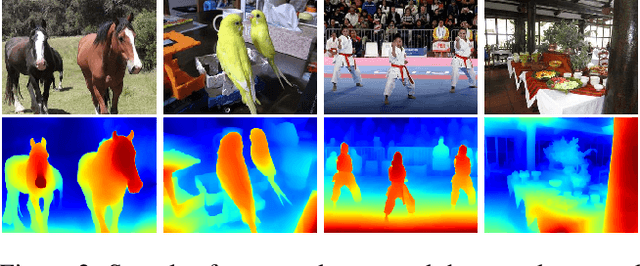
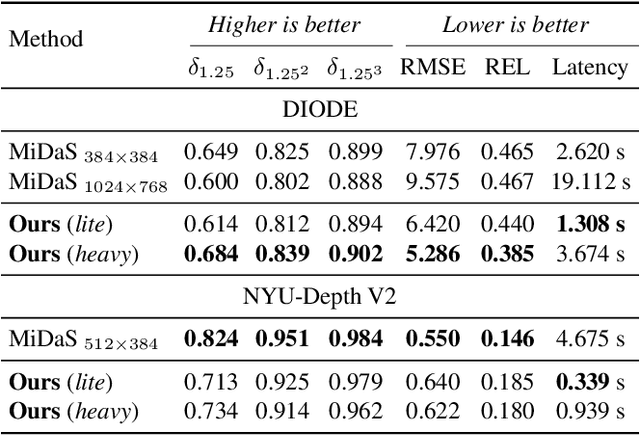
In the last few years, several works have tackled the problem of novel view synthesis from stereo images or even from a single picture. However, previous methods are computationally expensive, specially for high-resolution images. In this paper, we address the problem of generating a multiplane image (MPI) from a single high-resolution picture. We present the adaptive-MPI representation, which allows rendering novel views with low computational requirements. To this end, we propose an adaptive slicing algorithm that produces an MPI with a variable number of image planes. We present a new lightweight CNN for depth estimation, which is learned by knowledge distillation from a larger network. Occluded regions in the adaptive-MPI are inpainted also by a lightweight CNN. We show that our method is capable of producing high-quality predictions with one order of magnitude less parameters compared to previous approaches. The robustness of our method is evidenced on challenging pictures from the Internet.
Are visual dictionaries generalizable?
May 11, 2012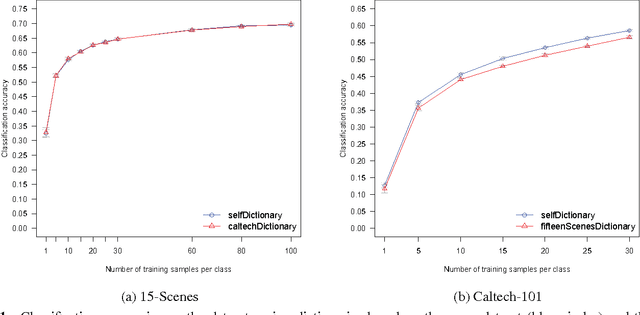
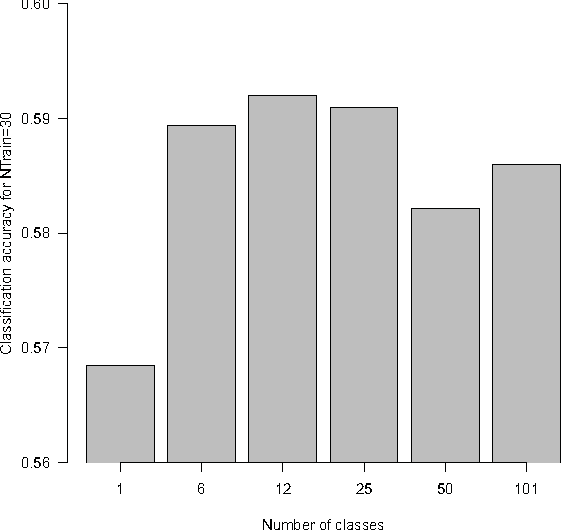
Mid-level features based on visual dictionaries are today a cornerstone of systems for classification and retrieval of images. Those state-of-the-art representations depend crucially on the choice of a codebook (visual dictionary), which is usually derived from the dataset. In general-purpose, dynamic image collections (e.g., the Web), one cannot have the entire collection in order to extract a representative dictionary. However, based on the hypothesis that the dictionary reflects only the diversity of low-level appearances and does not capture semantics, we argue that a dictionary based on a small subset of the data, or even on an entirely different dataset, is able to produce a good representation, provided that the chosen images span a diverse enough portion of the low-level feature space. Our experiments confirm that hypothesis, opening the opportunity to greatly alleviate the burden in generating the codebook, and confirming the feasibility of employing visual dictionaries in large-scale dynamic environments.