 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre visual dictionaries generalizable?
Paper and Code
May 11, 2012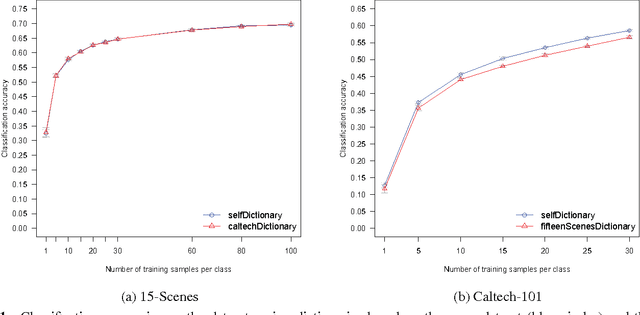
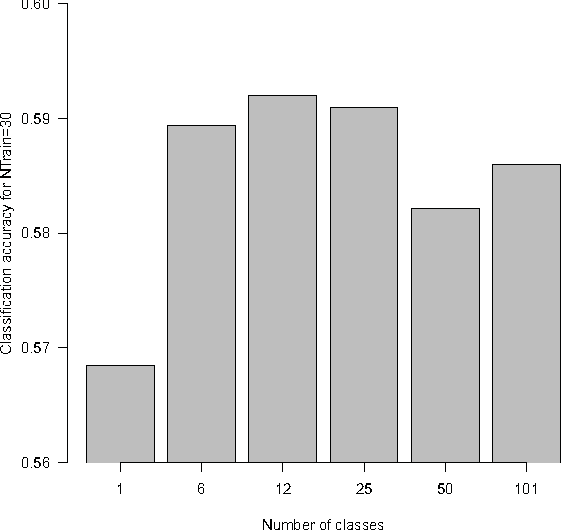
Mid-level features based on visual dictionaries are today a cornerstone of systems for classification and retrieval of images. Those state-of-the-art representations depend crucially on the choice of a codebook (visual dictionary), which is usually derived from the dataset. In general-purpose, dynamic image collections (e.g., the Web), one cannot have the entire collection in order to extract a representative dictionary. However, based on the hypothesis that the dictionary reflects only the diversity of low-level appearances and does not capture semantics, we argue that a dictionary based on a small subset of the data, or even on an entirely different dataset, is able to produce a good representation, provided that the chosen images span a diverse enough portion of the low-level feature space. Our experiments confirm that hypothesis, opening the opportunity to greatly alleviate the burden in generating the codebook, and confirming the feasibility of employing visual dictionaries in large-scale dynamic environments.