 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Optimization of an Autoencoder for Clustering and Embedding
Dec 07, 2020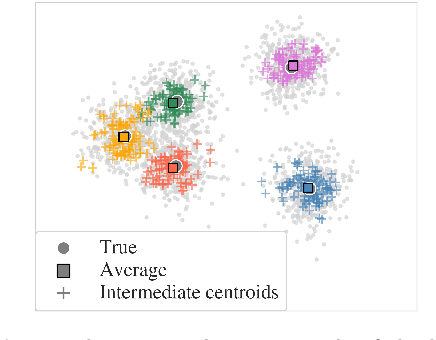

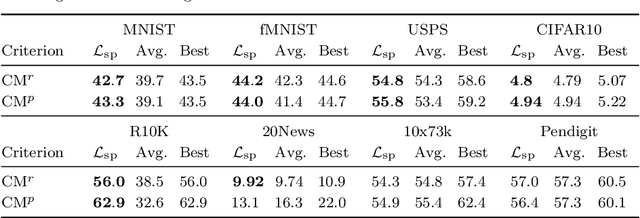
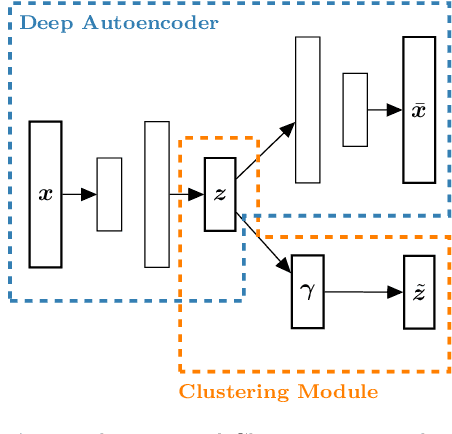
Incorporating k-means-like clustering techniques into (deep) autoencoders constitutes an interesting idea as the clustering may exploit the learned similarities in the embedding to compute a non-linear grouping of data at-hand. Unfortunately, the resulting contributions are often limited by ad-hoc choices, decoupled optimization problems and other issues. We present a theoretically-driven deep clustering approach that does not suffer from these limitations and allows for joint optimization of clustering and embedding. The network in its simplest form is derived from a Gaussian mixture model and can be incorporated seamlessly into deep autoencoders for state-of-the-art performance.
Principled Interpolation in Normalizing Flows
Oct 22, 2020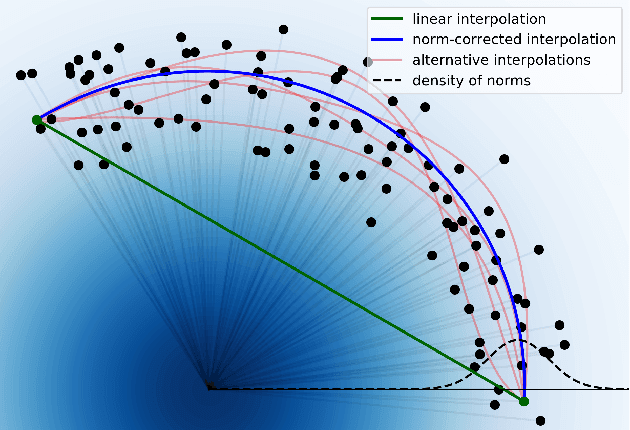
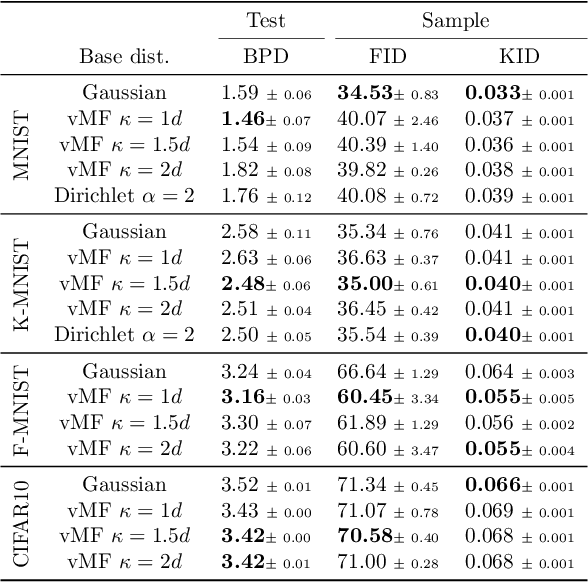

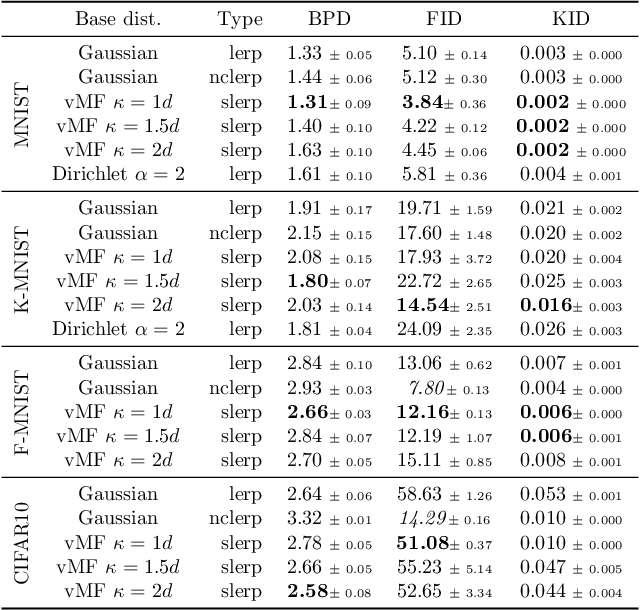
Generative models based on normalizing flows are very successful in modeling complex data distributions using simpler ones. However, straightforward linear interpolations show unexpected side effects, as interpolation paths lie outside the area where samples are observed. This is caused by the standard choice of Gaussian base distributions and can be seen in the norms of the interpolated samples. This observation suggests that correcting the norm should generally result in better interpolations, but it is not clear how to correct the norm in an unambiguous way. In this paper, we solve this issue by enforcing a fixed norm and, hence, change the base distribution, to allow for a principled way of interpolation. Specifically, we use the Dirichlet and von Mises-Fisher base distributions. Our experimental results show superior performance in terms of bits per dimension, Fr\'echet Inception Distance (FID), and Kernel Inception Distance (KID) scores for interpolation, while maintaining the same generative performance.
Infinite Mixture Model of Markov Chains
Jun 19, 2017



We propose a Bayesian nonparametric mixture model for prediction- and information extraction tasks with an efficient inference scheme. It models categorical-valued time series that exhibit dynamics from multiple underlying patterns (e.g. user behavior traces). We simplify the idea of capturing these patterns by hierarchical hidden Markov models (HHMMs) - and extend the existing approaches by the additional representation of structural information. Our empirical results are based on both synthetic- and real world data. They indicate that the results are easily interpretable, and that the model excels at segmentation and prediction performance: it successfully identifies the generating patterns and can be used for effective prediction of future observations.
Toward Supervised Anomaly Detection
Jan 23, 2014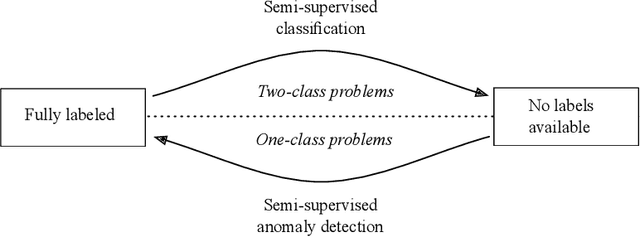


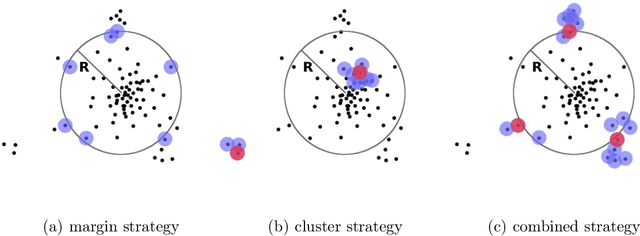
Anomaly detection is being regarded as an unsupervised learning task as anomalies stem from adversarial or unlikely events with unknown distributions. However, the predictive performance of purely unsupervised anomaly detection often fails to match the required detection rates in many tasks and there exists a need for labeled data to guide the model generation. Our first contribution shows that classical semi-supervised approaches, originating from a supervised classifier, are inappropriate and hardly detect new and unknown anomalies. We argue that semi-supervised anomaly detection needs to ground on the unsupervised learning paradigm and devise a novel algorithm that meets this requirement. Although being intrinsically non-convex, we further show that the optimization problem has a convex equivalent under relatively mild assumptions. Additionally, we propose an active learning strategy to automatically filter candidates for labeling. In an empirical study on network intrusion detection data, we observe that the proposed learning methodology requires much less labeled data than the state-of-the-art, while achieving higher detection accuracies.
Insights from Classifying Visual Concepts with Multiple Kernel Learning
Dec 16, 2011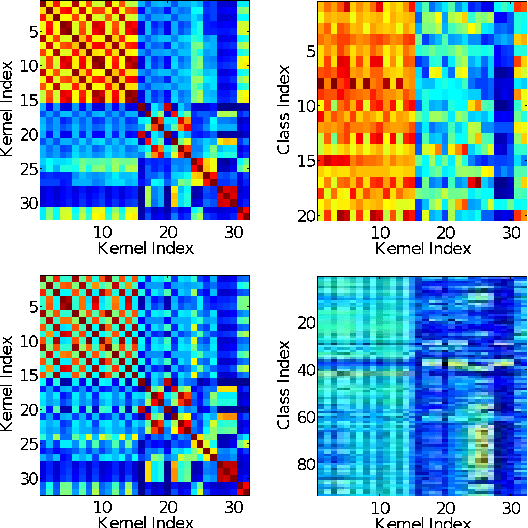
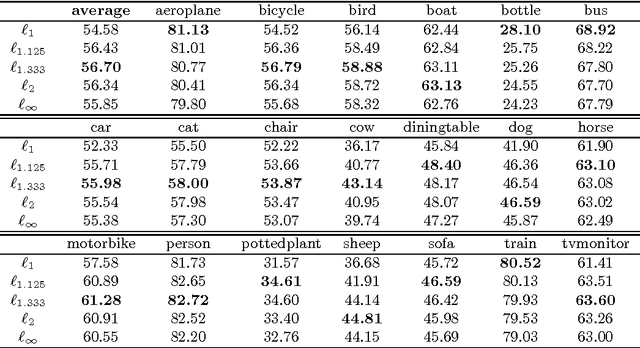

Combining information from various image features has become a standard technique in concept recognition tasks. However, the optimal way of fusing the resulting kernel functions is usually unknown in practical applications. Multiple kernel learning (MKL) techniques allow to determine an optimal linear combination of such similarity matrices. Classical approaches to MKL promote sparse mixtures. Unfortunately, so-called 1-norm MKL variants are often observed to be outperformed by an unweighted sum kernel. The contribution of this paper is twofold: We apply a recently developed non-sparse MKL variant to state-of-the-art concept recognition tasks within computer vision. We provide insights on benefits and limits of non-sparse MKL and compare it against its direct competitors, the sum kernel SVM and the sparse MKL. We report empirical results for the PASCAL VOC 2009 Classification and ImageCLEF2010 Photo Annotation challenge data sets. About to be submitted to PLoS ONE.
* 18 pages, 8 tables, 4 figures, format deviating from plos one submission format requirements for aesthetic reasons
Non-Sparse Regularization for Multiple Kernel Learning
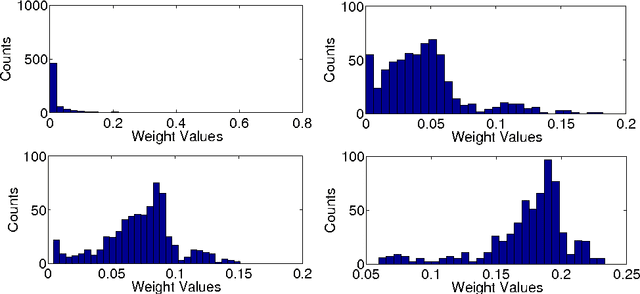
Oct 26, 2010
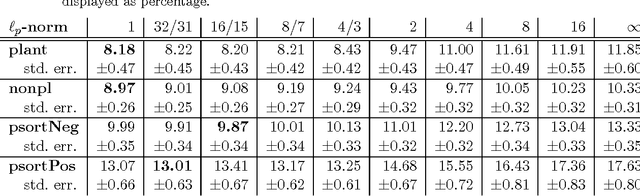
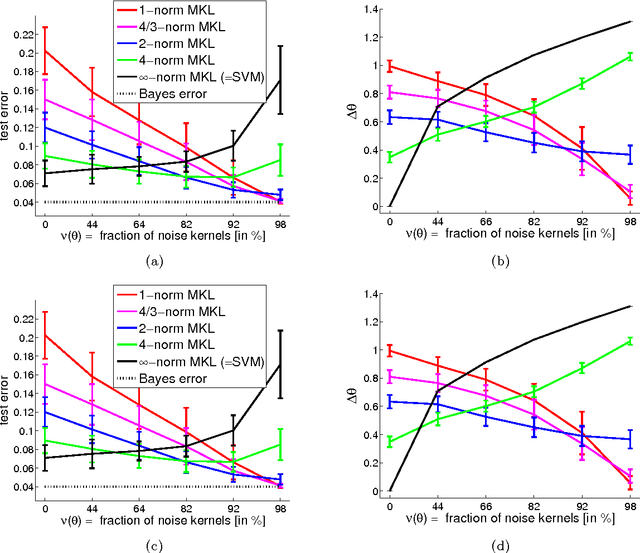
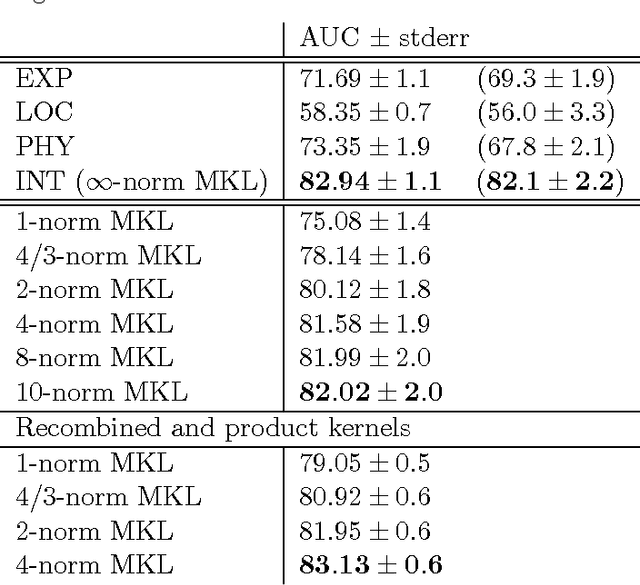
Learning linear combinations of multiple kernels is an appealing strategy when the right choice of features is unknown. Previous approaches to multiple kernel learning (MKL) promote sparse kernel combinations to support interpretability and scalability. Unfortunately, this 1-norm MKL is rarely observed to outperform trivial baselines in practical applications. To allow for robust kernel mixtures, we generalize MKL to arbitrary norms. We devise new insights on the connection between several existing MKL formulations and develop two efficient interleaved optimization strategies for arbitrary norms, like p-norms with p>1. Empirically, we demonstrate that the interleaved optimization strategies are much faster compared to the commonly used wrapper approaches. A theoretical analysis and an experiment on controlled artificial data experiment sheds light on the appropriateness of sparse, non-sparse and $\ell_\infty$-norm MKL in various scenarios. Empirical applications of p-norm MKL to three real-world problems from computational biology show that non-sparse MKL achieves accuracies that go beyond the state-of-the-art.