 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Sparse Regularization for Multiple Kernel Learning
Paper and Code
Oct 26, 2010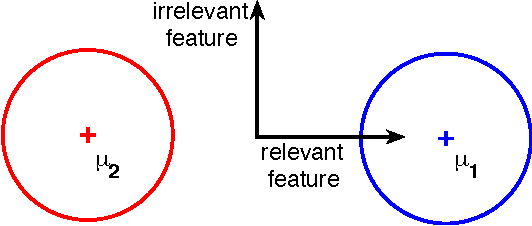
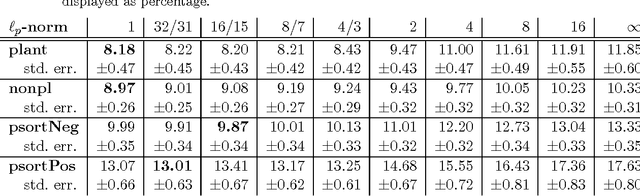
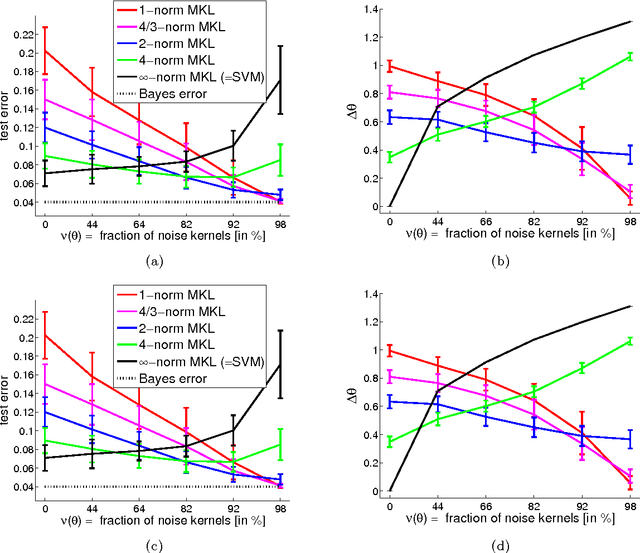
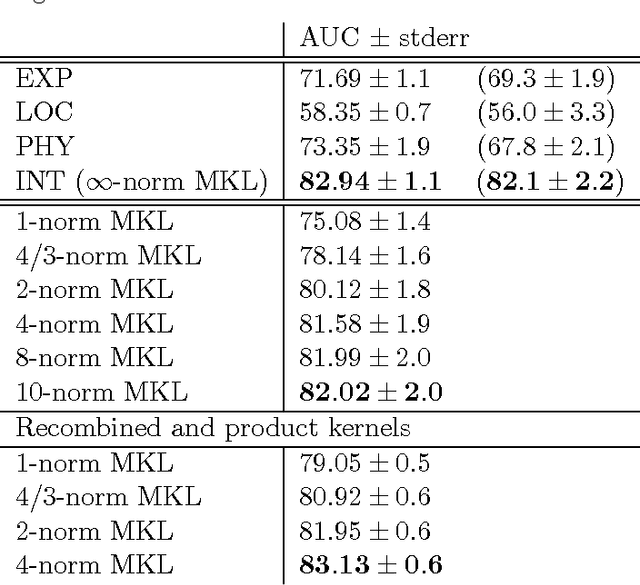
Learning linear combinations of multiple kernels is an appealing strategy when the right choice of features is unknown. Previous approaches to multiple kernel learning (MKL) promote sparse kernel combinations to support interpretability and scalability. Unfortunately, this 1-norm MKL is rarely observed to outperform trivial baselines in practical applications. To allow for robust kernel mixtures, we generalize MKL to arbitrary norms. We devise new insights on the connection between several existing MKL formulations and develop two efficient interleaved optimization strategies for arbitrary norms, like p-norms with p>1. Empirically, we demonstrate that the interleaved optimization strategies are much faster compared to the commonly used wrapper approaches. A theoretical analysis and an experiment on controlled artificial data experiment sheds light on the appropriateness of sparse, non-sparse and $\ell_\infty$-norm MKL in various scenarios. Empirical applications of p-norm MKL to three real-world problems from computational biology show that non-sparse MKL achieves accuracies that go beyond the state-of-the-art.