 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting ConvNet Diversity for Flooding Identification
Jun 05, 2018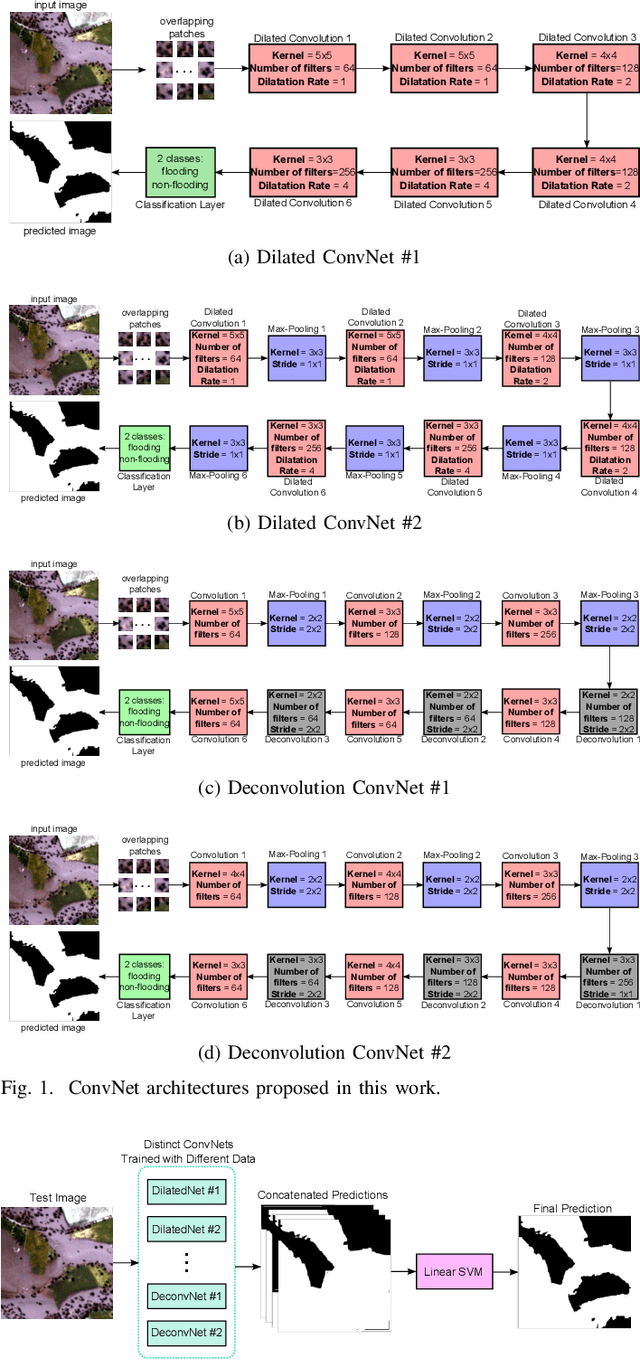


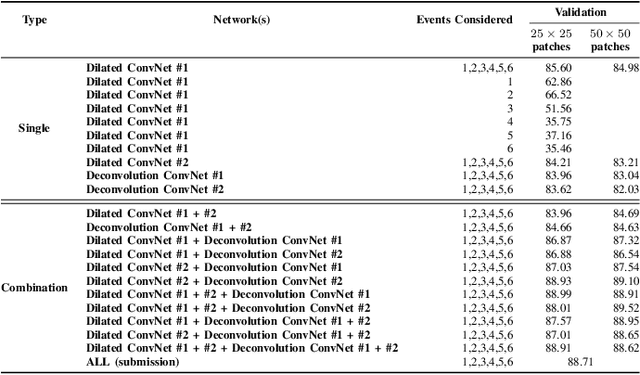
Flooding is the world's most costly type of natural disaster in terms of both economic losses and human causalities. A first and essential procedure towards flood monitoring is based on identifying the area most vulnerable to flooding, which gives authorities relevant regions to focus. In this work, we propose several methods to perform flooding identification in high-resolution remote sensing images using deep learning. Specifically, some proposed techniques are based upon unique networks, such as dilated and deconvolutional ones, while other was conceived to exploit diversity of distinct networks in order to extract the maximum performance of each classifier. Evaluation of the proposed algorithms were conducted in a high-resolution remote sensing dataset. Results show that the proposed algorithms outperformed several state-of-the-art baselines, providing improvements ranging from 1 to 4% in terms of the Jaccard Index.
Data, Depth, and Design: Learning Reliable Models for Melanoma Screening
Mar 23, 2018



Deep learning fostered a leap ahead in automated melanoma screening in the last two years. Those models, however, are expensive to train and difficult to parameterize. Objective: We investigate methodological issues for designing and evaluating deep learning models for melanoma detection. We explore ten choices faced by researchers: use of transfer learning, model architecture, train dataset, image resolution, type of data augmentation, input normalization, use of segmentation, duration of training, additional use of SVM, and test data augmentation. Methods: We perform two full factorial experiment, for five different test datasets, resulting in 2560 exhaustive trials in our main experiment, and 1280 trials in our assessment of transfer learning. We analyze both with multi-way ANOVA. We use the exhaustive trials to simulate sequential decisions and ensembles, with and without the use of privileged information from the test set. Results - main experiment: Amount of train data has disproportionate influence, explaining almost half the variation in performance. Of the other factors, test data augmentation and input resolution are the most influential. Deeper models, when combined, with extra data, also help. - transfer experiment: Transfer learning is critical, its absence brings huge performance penalties. - simulations: Ensembles of models are the best option to provide reliable results with limited resources, without using privileged information and sacrificing methodological rigor. Conclusions and Significance: Advancing research on automated melanoma screening requires curating larger public datasets. Indirect use of privileged information from the test set to design the models is a subtle, but frequent methodological mistake that leads to overoptimistic results. Ensembles of models are a cost-effective alternative to the expensive full-factorial and to the unstable sequential designs.
RECOD Titans at ISIC Challenge 2017
Mar 14, 2017
This extended abstract describes the participation of RECOD Titans in parts 1 and 3 of the ISIC Challenge 2017 "Skin Lesion Analysis Towards Melanoma Detection" (ISBI 2017). Although our team has a long experience with melanoma classification, the ISIC Challenge 2017 was the very first time we worked on skin-lesion segmentation. For part 1 (segmentation), our final submission used four of our models: two trained with all 2000 samples, without a validation split, for 250 and for 500 epochs respectively; and other two trained and validated with two different 1600/400 splits, for 220 epochs. Those four models, individually, achieved between 0.780 and 0.783 official validation scores. Our final submission averaged the output of those four models achieved a score of 0.793. For part 3 (classification), the submitted test run as well as our last official validation run were the result from a meta-model that assembled seven base deep-learning models: three based on Inception-V4 trained on our largest dataset; three based on Inception trained on our smallest dataset; and one based on ResNet-101 trained on our smaller dataset. The results of those component models were stacked in a meta-learning layer based on an SVM trained on the validation set of our largest dataset.