 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature salience -- not task-informativeness -- drives machine learning model explanations
Feb 15, 2026Explainable AI (XAI) promises to provide insight into machine learning models' decision processes, where one goal is to identify failures such as shortcut learning. This promise relies on the field's assumption that input features marked as important by an XAI must contain information about the target variable. However, it is unclear whether informativeness is indeed the main driver of importance attribution in practice, or if other data properties such as statistical suppression, novelty at test-time, or high feature salience substantially contribute. To clarify this, we trained deep learning models on three variants of a binary image classification task, in which translucent watermarks are either absent, act as class-dependent confounds, or represent class-independent noise. Results for five popular attribution methods show substantially elevated relative importance in watermarked areas (RIW) for all models regardless of the training setting ($R^2 \geq .45$). By contrast, whether the presence of watermarks is class-dependent or not only has a marginal effect on RIW ($R^2 \leq .03$), despite a clear impact impact on model performance and generalisation ability. XAI methods show similar behaviour to model-agnostic edge detection filters and attribute substantially less importance to watermarks when bright image intensities are encoded by smaller instead of larger feature values. These results indicate that importance attribution is most strongly driven by the salience of image structures at test time rather than statistical associations learned by machine learning models. Previous studies demonstrating successful XAI application should be reevaluated with respect to a possibly spurious concurrency of feature salience and informativeness, and workflows using feature attribution methods as building blocks should be scrutinised.
The effect of whitening on explanation performance
Feb 09, 2026Explainable Artificial Intelligence (XAI) aims to provide transparent insights into machine learning models, yet the reliability of many feature attribution methods remains a critical challenge. Prior research (Haufe et al., 2014; Wilming et al., 2022, 2023) has demonstrated that these methods often erroneously assign significant importance to non-informative variables, such as suppressor variables, leading to fundamental misinterpretations. Since statistical suppression is induced by feature dependencies, this study investigates whether data whitening, a common preprocessing technique for decorrelation, can mitigate such errors. Using the established XAI-TRIS benchmark (Clark et al., 2024b), which offers synthetic ground-truth data and quantitative measures of explanation correctness, we empirically evaluate 16 popular feature attribution methods applied in combination with 5 distinct whitening transforms. Additionally, we analyze a minimal linear two-dimensional classification problem (Wilming et al., 2023) to theoretically assess whether whitening can remove the impact of suppressor features from Bayes-optimal models. Our results indicate that, while specific whitening techniques can improve explanation performance, the degree of improvement varies substantially across XAI methods and model architectures. These findings highlight the complex relationship between data non-linearities, preprocessing quality, and attribution fidelity, underscoring the vital role of pre-processing techniques in enhancing model interpretability.
Explainable AI needs formal notions of explanation correctness
Sep 26, 2024The use of machine learning (ML) in critical domains such as medicine poses risks and requires regulation. One requirement is that decisions of ML systems in high-risk applications should be human-understandable. The field of "explainable artificial intelligence" (XAI) seemingly addresses this need. However, in its current form, XAI is unfit to provide quality control for ML; it itself needs scrutiny. Popular XAI methods cannot reliably answer important questions about ML models, their training data, or a given test input. We recapitulate results demonstrating that popular XAI methods systematically attribute importance to input features that are independent of the prediction target. This limits their utility for purposes such as model and data (in)validation, model improvement, and scientific discovery. We argue that the fundamental reason for this limitation is that current XAI methods do not address well-defined problems and are not evaluated against objective criteria of explanation correctness. Researchers should formally define the problems they intend to solve first and then design methods accordingly. This will lead to notions of explanation correctness that can be theoretically verified and objective metrics of explanation performance that can be assessed using ground-truth data.
GECOBench: A Gender-Controlled Text Dataset and Benchmark for Quantifying Biases in Explanations
Jun 17, 2024



Large pre-trained language models have become popular for many applications and form an important backbone of many downstream tasks in natural language processing (NLP). Applying 'explainable artificial intelligence' (XAI) techniques to enrich such models' outputs is considered crucial for assuring their quality and shedding light on their inner workings. However, large language models are trained on a plethora of data containing a variety of biases, such as gender biases, affecting model weights and, potentially, behavior. Currently, it is unclear to what extent such biases also impact model explanations in possibly unfavorable ways. We create a gender-controlled text dataset, GECO, in which otherwise identical sentences appear in male and female forms. This gives rise to ground-truth 'world explanations' for gender classification tasks, enabling the objective evaluation of the correctness of XAI methods. We also provide GECOBench, a rigorous quantitative evaluation framework benchmarking popular XAI methods, applying them to pre-trained language models fine-tuned to different degrees. This allows us to investigate how pre-training induces undesirable bias in model explanations and to what extent fine-tuning can mitigate such explanation bias. We show a clear dependency between explanation performance and the number of fine-tuned layers, where XAI methods are observed to particularly benefit from fine-tuning or complete retraining of embedding layers. Remarkably, this relationship holds for models achieving similar classification performance on the same task. With that, we highlight the utility of the proposed gender-controlled dataset and novel benchmarking approach for research and development of novel XAI methods. All code including dataset generation, model training, evaluation and visualization is available at: https://github.com/braindatalab/gecobench
EXACT: Towards a platform for empirically benchmarking Machine Learning model explanation methods
May 20, 2024The evolving landscape of explainable artificial intelligence (XAI) aims to improve the interpretability of intricate machine learning (ML) models, yet faces challenges in formalisation and empirical validation, being an inherently unsupervised process. In this paper, we bring together various benchmark datasets and novel performance metrics in an initial benchmarking platform, the Explainable AI Comparison Toolkit (EXACT), providing a standardised foundation for evaluating XAI methods. Our datasets incorporate ground truth explanations for class-conditional features, and leveraging novel quantitative metrics, this platform assesses the performance of post-hoc XAI methods in the quality of the explanations they produce. Our recent findings have highlighted the limitations of popular XAI methods, as they often struggle to surpass random baselines, attributing significance to irrelevant features. Moreover, we show the variability in explanations derived from different equally performing model architectures. This initial benchmarking platform therefore aims to allow XAI researchers to test and assure the high quality of their newly developed methods.
XAI-TRIS: Non-linear benchmarks to quantify ML explanation performance
Jun 22, 2023The field of 'explainable' artificial intelligence (XAI) has produced highly cited methods that seek to make the decisions of complex machine learning (ML) methods 'understandable' to humans, for example by attributing 'importance' scores to input features. Yet, a lack of formal underpinning leaves it unclear as to what conclusions can safely be drawn from the results of a given XAI method and has also so far hindered the theoretical verification and empirical validation of XAI methods. This means that challenging non-linear problems, typically solved by deep neural networks, presently lack appropriate remedies. Here, we craft benchmark datasets for three different non-linear classification scenarios, in which the important class-conditional features are known by design, serving as ground truth explanations. Using novel quantitative metrics, we benchmark the explanation performance of a wide set of XAI methods across three deep learning model architectures. We show that popular XAI methods are often unable to significantly outperform random performance baselines and edge detection methods. Moreover, we demonstrate that explanations derived from different model architectures can be vastly different; thus, prone to misinterpretation even under controlled conditions.
Benchmark data to study the influence of pre-training on explanation performance in MR image classification
Jun 21, 2023



Convolutional Neural Networks (CNNs) are frequently and successfully used in medical prediction tasks. They are often used in combination with transfer learning, leading to improved performance when training data for the task are scarce. The resulting models are highly complex and typically do not provide any insight into their predictive mechanisms, motivating the field of 'explainable' artificial intelligence (XAI). However, previous studies have rarely quantitatively evaluated the 'explanation performance' of XAI methods against ground-truth data, and transfer learning and its influence on objective measures of explanation performance has not been investigated. Here, we propose a benchmark dataset that allows for quantifying explanation performance in a realistic magnetic resonance imaging (MRI) classification task. We employ this benchmark to understand the influence of transfer learning on the quality of explanations. Experimental results show that popular XAI methods applied to the same underlying model differ vastly in performance, even when considering only correctly classified examples. We further observe that explanation performance strongly depends on the task used for pre-training and the number of CNN layers pre-trained. These results hold after correcting for a substantial correlation between explanation and classification performance.
Theoretical Behavior of XAI Methods in the Presence of Suppressor Variables
Jun 02, 2023



In recent years, the community of 'explainable artificial intelligence' (XAI) has created a vast body of methods to bridge a perceived gap between model 'complexity' and 'interpretability'. However, a concrete problem to be solved by XAI methods has not yet been formally stated. As a result, XAI methods are lacking theoretical and empirical evidence for the 'correctness' of their explanations, limiting their potential use for quality-control and transparency purposes. At the same time, Haufe et al. (2014) showed, using simple toy examples, that even standard interpretations of linear models can be highly misleading. Specifically, high importance may be attributed to so-called suppressor variables lacking any statistical relation to the prediction target. This behavior has been confirmed empirically for a large array of XAI methods in Wilming et al. (2022). Here, we go one step further by deriving analytical expressions for the behavior of a variety of popular XAI methods on a simple two-dimensional binary classification problem involving Gaussian class-conditional distributions. We show that the majority of the studied approaches will attribute non-zero importance to a non-class-related suppressor feature in the presence of correlated noise. This poses important limitations on the interpretations and conclusions that the outputs of these XAI methods can afford.
Scrutinizing XAI using linear ground-truth data with suppressor variables
Nov 14, 2021

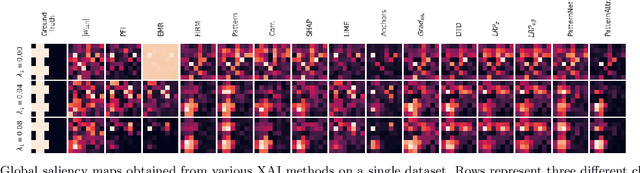
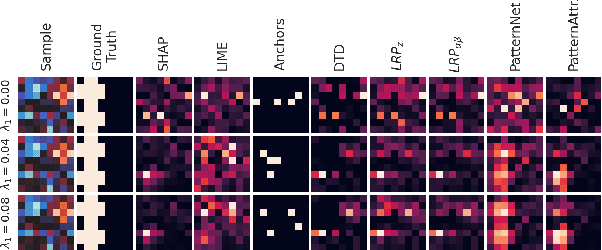
Machine learning (ML) is increasingly often used to inform high-stakes decisions. As complex ML models (e.g., deep neural networks) are often considered black boxes, a wealth of procedures has been developed to shed light on their inner workings and the ways in which their predictions come about, defining the field of 'explainable AI' (XAI). Saliency methods rank input features according to some measure of 'importance'. Such methods are difficult to validate since a formal definition of feature importance is, thus far, lacking. It has been demonstrated that some saliency methods can highlight features that have no statistical association with the prediction target (suppressor variables). To avoid misinterpretations due to such behavior, we propose the actual presence of such an association as a necessary condition and objective preliminary definition for feature importance. We carefully crafted a ground-truth dataset in which all statistical dependencies are well-defined and linear, serving as a benchmark to study the problem of suppressor variables. We evaluate common explanation methods including LRP, DTD, PatternNet, PatternAttribution, LIME, Anchors, SHAP, and permutation-based methods with respect to our objective definition. We show that most of these methods are unable to distinguish important features from suppressors in this setting.