 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Do Large Language Models Know? Tacit Knowledge as a Potential Causal-Explanatory Structure
Apr 16, 2025It is sometimes assumed that Large Language Models (LLMs) know language, or for example that they know that Paris is the capital of France. But what -- if anything -- do LLMs actually know? In this paper, I argue that LLMs can acquire tacit knowledge as defined by Martin Davies (1990). Whereas Davies himself denies that neural networks can acquire tacit knowledge, I demonstrate that certain architectural features of LLMs satisfy the constraints of semantic description, syntactic structure, and causal systematicity. Thus, tacit knowledge may serve as a conceptual framework for describing, explaining, and intervening on LLMs and their behavior.
Benchmark data to study the influence of pre-training on explanation performance in MR image classification
Jun 21, 2023



Convolutional Neural Networks (CNNs) are frequently and successfully used in medical prediction tasks. They are often used in combination with transfer learning, leading to improved performance when training data for the task are scarce. The resulting models are highly complex and typically do not provide any insight into their predictive mechanisms, motivating the field of 'explainable' artificial intelligence (XAI). However, previous studies have rarely quantitatively evaluated the 'explanation performance' of XAI methods against ground-truth data, and transfer learning and its influence on objective measures of explanation performance has not been investigated. Here, we propose a benchmark dataset that allows for quantifying explanation performance in a realistic magnetic resonance imaging (MRI) classification task. We employ this benchmark to understand the influence of transfer learning on the quality of explanations. Experimental results show that popular XAI methods applied to the same underlying model differ vastly in performance, even when considering only correctly classified examples. We further observe that explanation performance strongly depends on the task used for pre-training and the number of CNN layers pre-trained. These results hold after correcting for a substantial correlation between explanation and classification performance.
Evaluating saliency methods on artificial data with different background types
Dec 09, 2021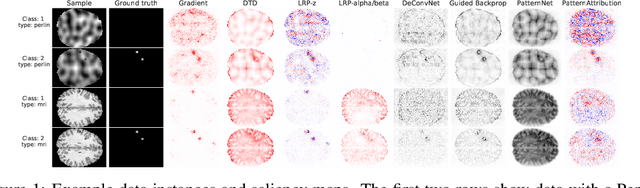
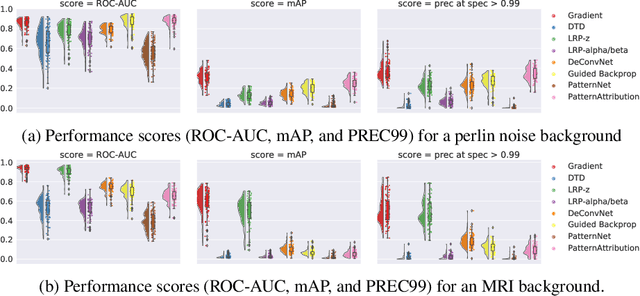
Over the last years, many 'explainable artificial intelligence' (xAI) approaches have been developed, but these have not always been objectively evaluated. To evaluate the quality of heatmaps generated by various saliency methods, we developed a framework to generate artificial data with synthetic lesions and a known ground truth map. Using this framework, we evaluated two data sets with different backgrounds, Perlin noise and 2D brain MRI slices, and found that the heatmaps vary strongly between saliency methods and backgrounds. We strongly encourage further evaluation of saliency maps and xAI methods using this framework before applying these in clinical or other safety-critical settings.
Scrutinizing XAI using linear ground-truth data with suppressor variables
Nov 14, 2021

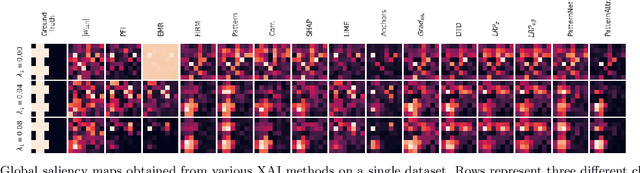
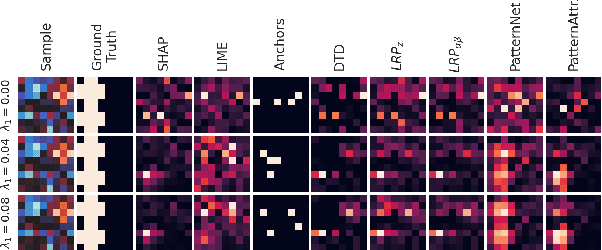
Machine learning (ML) is increasingly often used to inform high-stakes decisions. As complex ML models (e.g., deep neural networks) are often considered black boxes, a wealth of procedures has been developed to shed light on their inner workings and the ways in which their predictions come about, defining the field of 'explainable AI' (XAI). Saliency methods rank input features according to some measure of 'importance'. Such methods are difficult to validate since a formal definition of feature importance is, thus far, lacking. It has been demonstrated that some saliency methods can highlight features that have no statistical association with the prediction target (suppressor variables). To avoid misinterpretations due to such behavior, we propose the actual presence of such an association as a necessary condition and objective preliminary definition for feature importance. We carefully crafted a ground-truth dataset in which all statistical dependencies are well-defined and linear, serving as a benchmark to study the problem of suppressor variables. We evaluate common explanation methods including LRP, DTD, PatternNet, PatternAttribution, LIME, Anchors, SHAP, and permutation-based methods with respect to our objective definition. We show that most of these methods are unable to distinguish important features from suppressors in this setting.