 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Large Language Models: STEM education and Gender Stereotypes
Jun 14, 2024

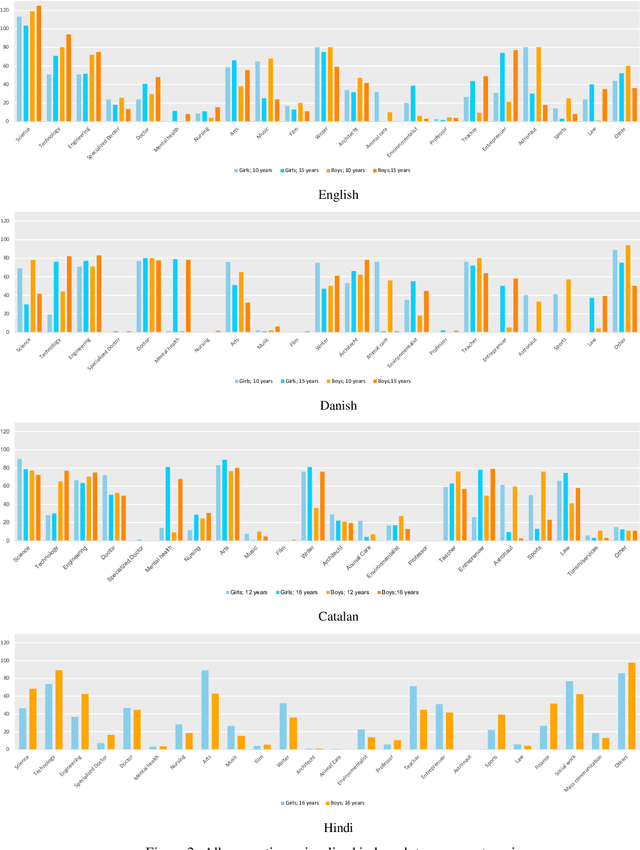

Large Language Models (LLMs) have an increasing impact on our lives with use cases such as chatbots, study support, coding support, ideation, writing assistance, and more. Previous studies have revealed linguistic biases in pronouns used to describe professions or adjectives used to describe men vs women. These issues have to some degree been addressed in updated LLM versions, at least to pass existing tests. However, biases may still be present in the models, and repeated use of gender stereotypical language may reinforce the underlying assumptions and are therefore important to examine further. This paper investigates gender biases in LLMs in relation to educational choices through an open-ended, true to user-case experimental design and a quantitative analysis. We investigate the biases in the context of four different cultures, languages, and educational systems (English/US/UK, Danish/DK, Catalan/ES, and Hindi/IN) for ages ranging from 10 to 16 years, corresponding to important educational transition points in the different countries. We find that there are significant and large differences in the ratio of STEM to non-STEM suggested education paths provided by chatGPT when using typical girl vs boy names to prompt lists of suggested things to become. There are generally fewer STEM suggestions in the Danish, Spanish, and Indian context compared to the English. We also find subtle differences in the suggested professions, which we categorise and report.
A Self-Organizing Clustering System for Unsupervised Distribution Shift Detection
Apr 25, 2024Modeling non-stationary data is a challenging problem in the field of continual learning, and data distribution shifts may result in negative consequences on the performance of a machine learning model. Classic learning tools are often vulnerable to perturbations of the input covariates, and are sensitive to outliers and noise, and some tools are based on rigid algebraic assumptions. Distribution shifts are frequently occurring due to changes in raw materials for production, seasonality, a different user base, or even adversarial attacks. Therefore, there is a need for more effective distribution shift detection techniques. In this work, we propose a continual learning framework for monitoring and detecting distribution changes. We explore the problem in a latent space generated by a bio-inspired self-organizing clustering and statistical aspects of the latent space. In particular, we investigate the projections made by two topology-preserving maps: the Self-Organizing Map and the Scale Invariant Map. Our method can be applied in both a supervised and an unsupervised context. We construct the assessment of changes in the data distribution as a comparison of Gaussian signals, making the proposed method fast and robust. We compare it to other unsupervised techniques, specifically Principal Component Analysis (PCA) and Kernel-PCA. Our comparison involves conducting experiments using sequences of images (based on MNIST and injected shifts with adversarial samples), chemical sensor measurements, and the environmental variable related to ozone levels. The empirical study reveals the potential of the proposed approach.
Pantypes: Diverse Representatives for Self-Explainable Models
Mar 14, 2024Prototypical self-explainable classifiers have emerged to meet the growing demand for interpretable AI systems. These classifiers are designed to incorporate high transparency in their decisions by basing inference on similarity with learned prototypical objects. While these models are designed with diversity in mind, the learned prototypes often do not sufficiently represent all aspects of the input distribution, particularly those in low density regions. Such lack of sufficient data representation, known as representation bias, has been associated with various detrimental properties related to machine learning diversity and fairness. In light of this, we introduce pantypes, a new family of prototypical objects designed to capture the full diversity of the input distribution through a sparse set of objects. We show that pantypes can empower prototypical self-explainable models by occupying divergent regions of the latent space and thus fostering high diversity, interpretability and fairness.
Deep learning for Chemometric and non-translational data
Nov 07, 2019

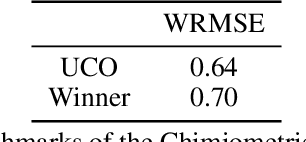

We propose a novel method to train deep convolutional neural networks which learn from multiple data sets of varying input sizes through weight sharing. This is an advantage in chemometrics where individual measurements represent exact chemical compounds and thus signals cannot be translated or resized without disturbing their interpretation. Our approach show superior performance compared to transfer learning when a medium sized and a small data set are trained together. While we observe a small improvement compared to individual training when two medium sized data sets are trained together, in particular through a reduction in the variance.