 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Self-Organizing Clustering System for Unsupervised Distribution Shift Detection
Apr 25, 2024Modeling non-stationary data is a challenging problem in the field of continual learning, and data distribution shifts may result in negative consequences on the performance of a machine learning model. Classic learning tools are often vulnerable to perturbations of the input covariates, and are sensitive to outliers and noise, and some tools are based on rigid algebraic assumptions. Distribution shifts are frequently occurring due to changes in raw materials for production, seasonality, a different user base, or even adversarial attacks. Therefore, there is a need for more effective distribution shift detection techniques. In this work, we propose a continual learning framework for monitoring and detecting distribution changes. We explore the problem in a latent space generated by a bio-inspired self-organizing clustering and statistical aspects of the latent space. In particular, we investigate the projections made by two topology-preserving maps: the Self-Organizing Map and the Scale Invariant Map. Our method can be applied in both a supervised and an unsupervised context. We construct the assessment of changes in the data distribution as a comparison of Gaussian signals, making the proposed method fast and robust. We compare it to other unsupervised techniques, specifically Principal Component Analysis (PCA) and Kernel-PCA. Our comparison involves conducting experiments using sequences of images (based on MNIST and injected shifts with adversarial samples), chemical sensor measurements, and the environmental variable related to ozone levels. The empirical study reveals the potential of the proposed approach.
Evolutionary Echo State Network: evolving reservoirs in the Fourier space
Jun 10, 2022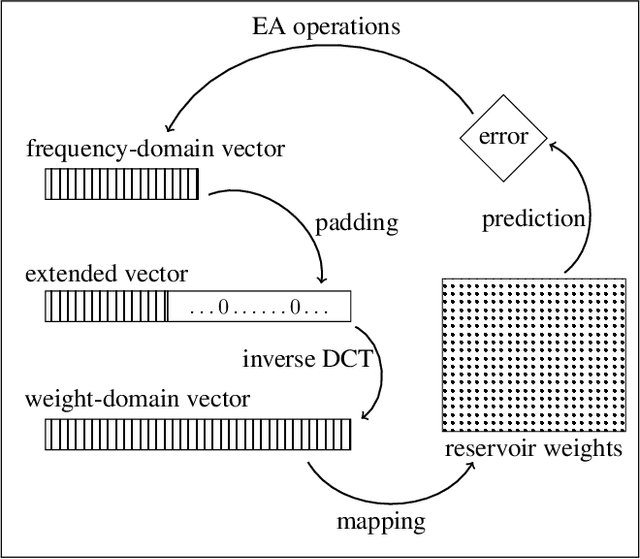


The Echo State Network (ESN) is a class of Recurrent Neural Network with a large number of hidden-hidden weights (in the so-called reservoir). Canonical ESN and its variations have recently received significant attention due to their remarkable success in the modeling of non-linear dynamical systems. The reservoir is randomly connected with fixed weights that don't change in the learning process. Only the weights from reservoir to output are trained. Since the reservoir is fixed during the training procedure, we may wonder if the computational power of the recurrent structure is fully harnessed. In this article, we propose a new computational model of the ESN type, that represents the reservoir weights in the Fourier space and performs a fine-tuning of these weights applying genetic algorithms in the frequency domain. The main interest is that this procedure will work in a much smaller space compared to the classical ESN, thus providing a dimensionality reduction transformation of the initial method. The proposed technique allows us to exploit the benefits of the large recurrent structure avoiding the training problems of gradient-based method. We provide a detailed experimental study that demonstrates the good performances of our approach with well-known chaotic systems and real-world data.
A Tutorial about Random Neural Networks in Supervised Learning
Sep 15, 2016

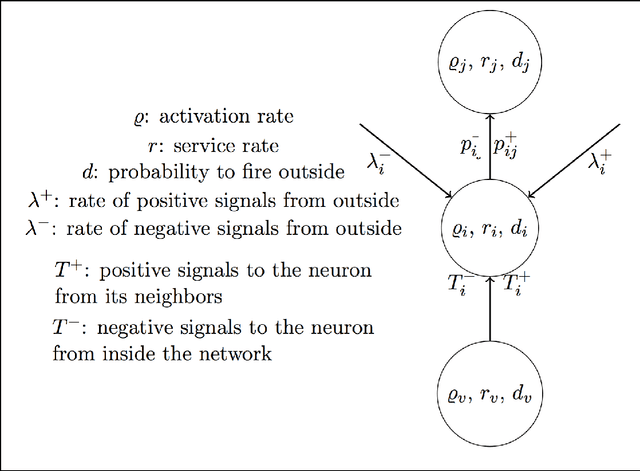

Random Neural Networks (RNNs) are a class of Neural Networks (NNs) that can also be seen as a specific type of queuing network. They have been successfully used in several domains during the last 25 years, as queuing networks to analyze the performance of resource sharing in many engineering areas, as learning tools and in combinatorial optimization, where they are seen as neural systems, and also as models of neurological aspects of living beings. In this article we focus on their learning capabilities, and more specifically, we present a practical guide for using the RNN to solve supervised learning problems. We give a general description of these models using almost indistinctly the terminology of Queuing Theory and the neural one. We present the standard learning procedures used by RNNs, adapted from similar well-established improvements in the standard NN field. We describe in particular a set of learning algorithms covering techniques based on the use of first order and, then, of second order derivatives. We also discuss some issues related to these objects and present new perspectives about their use in supervised learning problems. The tutorial describes their most relevant applications, and also provides a large bibliography.
* This paper is a draft of an article to be published in Neural Network World
Echo State Queueing Network: a new reservoir computing learning tool
Dec 26, 2012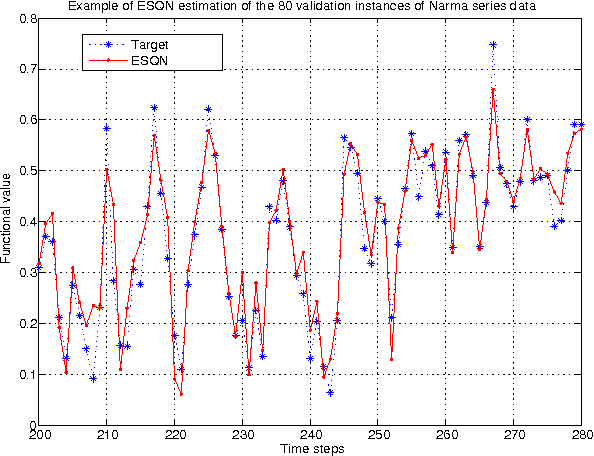
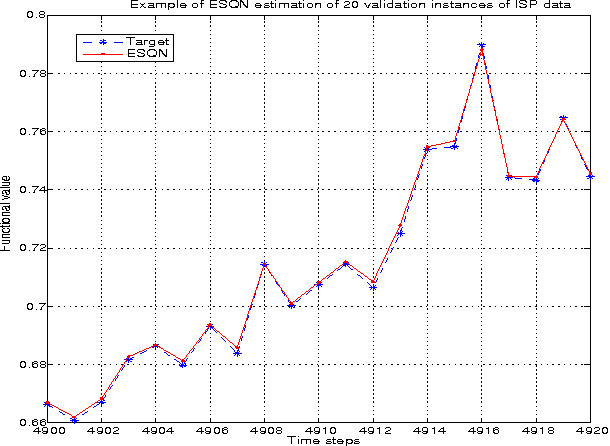


In the last decade, a new computational paradigm was introduced in the field of Machine Learning, under the name of Reservoir Computing (RC). RC models are neural networks which a recurrent part (the reservoir) that does not participate in the learning process, and the rest of the system where no recurrence (no neural circuit) occurs. This approach has grown rapidly due to its success in solving learning tasks and other computational applications. Some success was also observed with another recently proposed neural network designed using Queueing Theory, the Random Neural Network (RandNN). Both approaches have good properties and identified drawbacks. In this paper, we propose a new RC model called Echo State Queueing Network (ESQN), where we use ideas coming from RandNNs for the design of the reservoir. ESQNs consist in ESNs where the reservoir has a new dynamics inspired by recurrent RandNNs. The paper positions ESQNs in the global Machine Learning area, and provides examples of their use and performances. We show on largely used benchmarks that ESQNs are very accurate tools, and we illustrate how they compare with standard ESNs.