 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Self-Organizing Clustering System for Unsupervised Distribution Shift Detection
Apr 25, 2024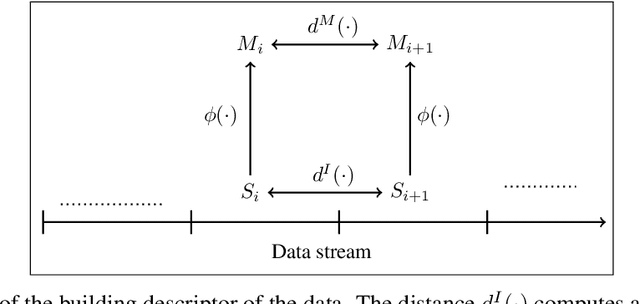

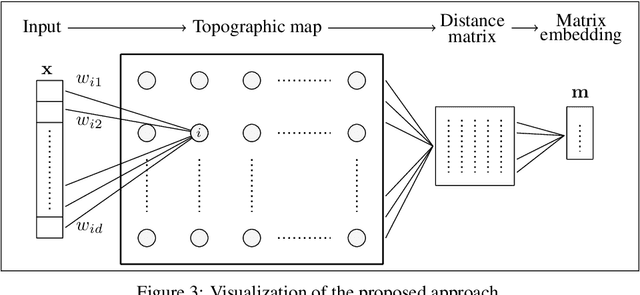

Modeling non-stationary data is a challenging problem in the field of continual learning, and data distribution shifts may result in negative consequences on the performance of a machine learning model. Classic learning tools are often vulnerable to perturbations of the input covariates, and are sensitive to outliers and noise, and some tools are based on rigid algebraic assumptions. Distribution shifts are frequently occurring due to changes in raw materials for production, seasonality, a different user base, or even adversarial attacks. Therefore, there is a need for more effective distribution shift detection techniques. In this work, we propose a continual learning framework for monitoring and detecting distribution changes. We explore the problem in a latent space generated by a bio-inspired self-organizing clustering and statistical aspects of the latent space. In particular, we investigate the projections made by two topology-preserving maps: the Self-Organizing Map and the Scale Invariant Map. Our method can be applied in both a supervised and an unsupervised context. We construct the assessment of changes in the data distribution as a comparison of Gaussian signals, making the proposed method fast and robust. We compare it to other unsupervised techniques, specifically Principal Component Analysis (PCA) and Kernel-PCA. Our comparison involves conducting experiments using sequences of images (based on MNIST and injected shifts with adversarial samples), chemical sensor measurements, and the environmental variable related to ozone levels. The empirical study reveals the potential of the proposed approach.
Re-visiting Reservoir Computing architectures optimized by Evolutionary Algorithms
Nov 11, 2022


For many years, Evolutionary Algorithms (EAs) have been applied to improve Neural Networks (NNs) architectures. They have been used for solving different problems, such as training the networks (adjusting the weights), designing network topology, optimizing global parameters, and selecting features. Here, we provide a systematic brief survey about applications of the EAs on the specific domain of the recurrent NNs named Reservoir Computing (RC). At the beginning of the 2000s, the RC paradigm appeared as a good option for employing recurrent NNs without dealing with the inconveniences of the training algorithms. RC models use a nonlinear dynamic system, with fixed recurrent neural network named the \textit{reservoir}, and learning process is restricted to adjusting a linear parametric function. %so the performance of learning is fast and precise. However, an RC model has several hyper-parameters, therefore EAs are helpful tools to figure out optimal RC architectures. We provide an overview of the results on the area, discuss novel advances, and we present our vision regarding the new trends and still open questions.
Tracking changes using Kullback-Leibler divergence for the continual learning
Oct 10, 2022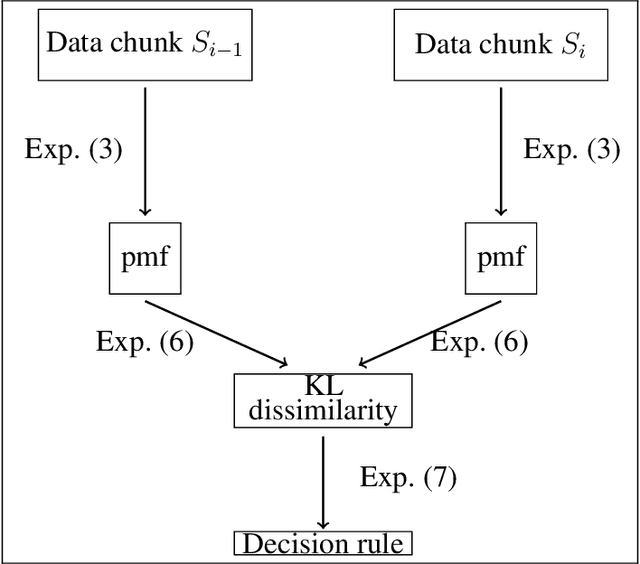
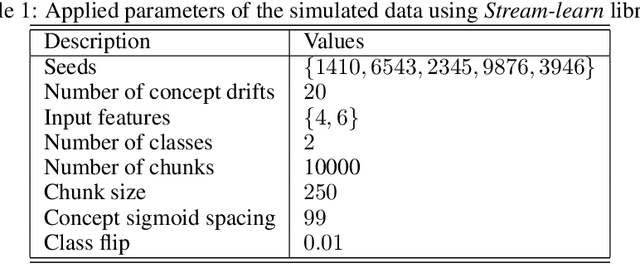
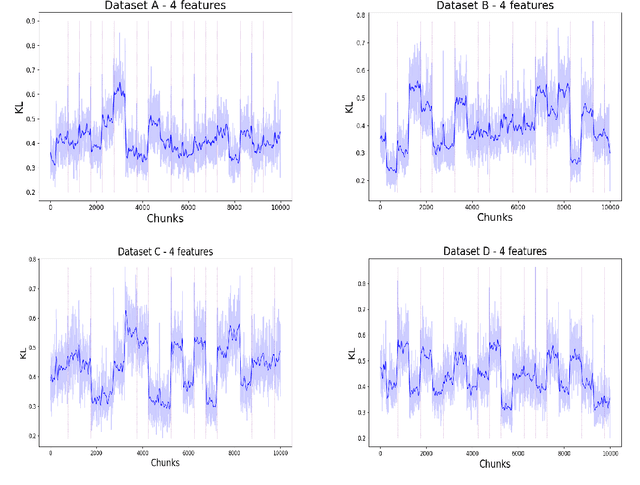
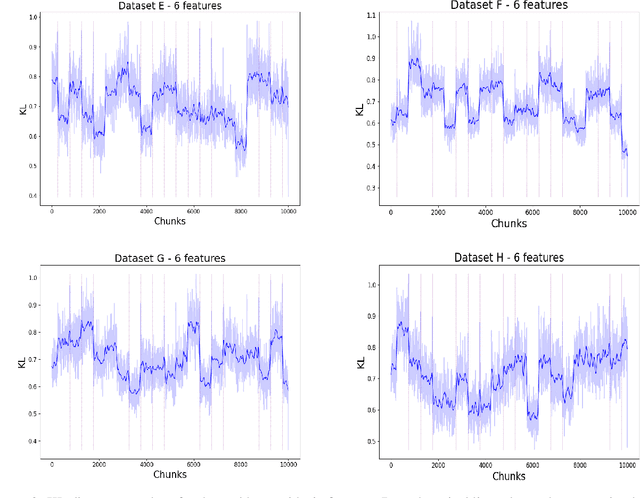
Recently, continual learning has received a lot of attention. One of the significant problems is the occurrence of \emph{concept drift}, which consists of changing probabilistic characteristics of the incoming data. In the case of the classification task, this phenomenon destabilizes the model's performance and negatively affects the achieved prediction quality. Most current methods apply statistical learning and similarity analysis over the raw data. However, similarity analysis in streaming data remains a complex problem due to time limitation, non-precise values, fast decision speed, scalability, etc. This article introduces a novel method for monitoring changes in the probabilistic distribution of multi-dimensional data streams. As a measure of the rapidity of changes, we analyze the popular Kullback-Leibler divergence. During the experimental study, we show how to use this metric to predict the concept drift occurrence and understand its nature. The obtained results encourage further work on the proposed methods and its application in the real tasks where the prediction of the future appearance of concept drift plays a crucial role, such as predictive maintenance.
Prediction of Facebook Post Metrics using Machine Learning
May 15, 2018
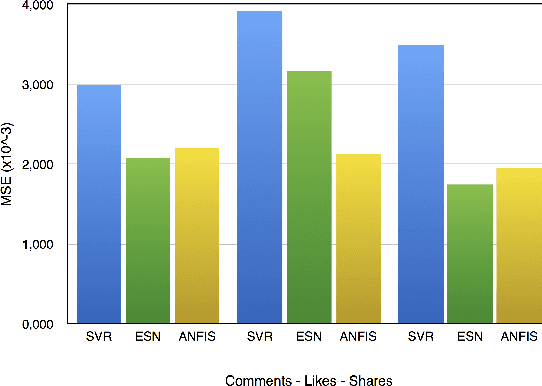
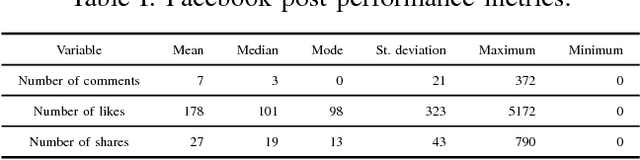
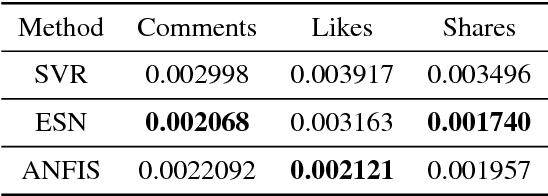
In this short paper, we evaluate the performance of three well-known Machine Learning techniques for predicting the impact of a post in Facebook. Social medias have a huge influence in the social behaviour. Therefore to develop an automatic model for predicting the impact of posts in social medias can be useful to the society. In this article, we analyze the efficiency for predicting the post impact of three popular techniques: Support Vector Regression (SVR), Echo State Network (ESN) and Adaptive Network Fuzzy Inject System (ANFIS). The evaluation was done over a public and well-known benchmark dataset.
Empirical Analysis of the Necessary and Sufficient Conditions of the Echo State Property
Mar 20, 2017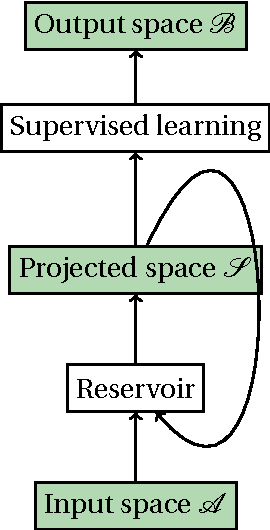

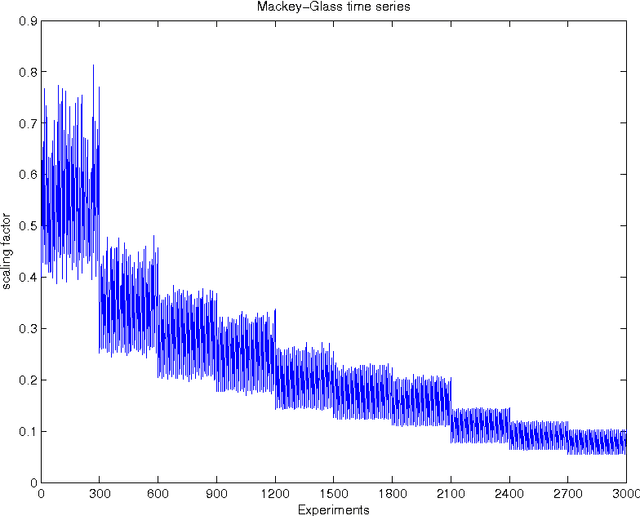
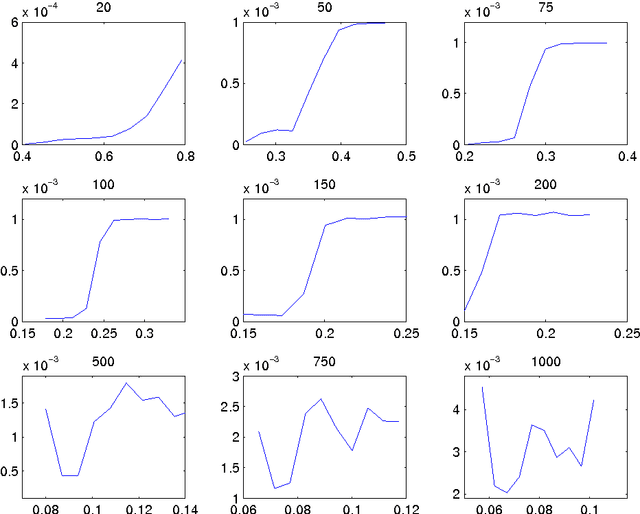
The Echo State Network (ESN) is a specific recurrent network, which has gained popularity during the last years. The model has a recurrent network named reservoir, that is fixed during the learning process. The reservoir is used for transforming the input space in a larger space. A fundamental property that provokes an impact on the model accuracy is the Echo State Property (ESP). There are two main theoretical results related to the ESP. First, a sufficient condition for the ESP existence that involves the singular values of the reservoir matrix. Second, a necessary condition for the ESP. The ESP can be violated according to the spectral radius value of the reservoir matrix. There is a theoretical gap between these necessary and sufficient conditions. This article presents an empirical analysis of the accuracy and the projections of reservoirs that satisfy this theoretical gap. It gives some insights about the generation of the reservoir matrix. From previous works, it is already known that the optimal accuracy is obtained near to the border of stability control of the dynamics. Then, according to our empirical results, we can see that this border seems to be closer to the sufficient conditions than to the necessary conditions of the ESP.
A Tutorial about Random Neural Networks in Supervised Learning
Sep 15, 2016

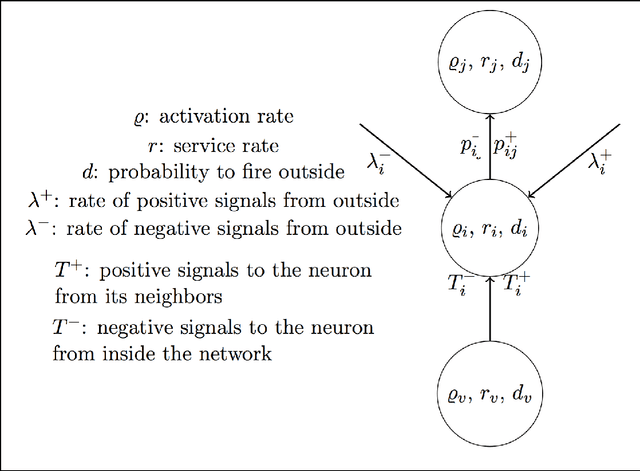

Random Neural Networks (RNNs) are a class of Neural Networks (NNs) that can also be seen as a specific type of queuing network. They have been successfully used in several domains during the last 25 years, as queuing networks to analyze the performance of resource sharing in many engineering areas, as learning tools and in combinatorial optimization, where they are seen as neural systems, and also as models of neurological aspects of living beings. In this article we focus on their learning capabilities, and more specifically, we present a practical guide for using the RNN to solve supervised learning problems. We give a general description of these models using almost indistinctly the terminology of Queuing Theory and the neural one. We present the standard learning procedures used by RNNs, adapted from similar well-established improvements in the standard NN field. We describe in particular a set of learning algorithms covering techniques based on the use of first order and, then, of second order derivatives. We also discuss some issues related to these objects and present new perspectives about their use in supervised learning problems. The tutorial describes their most relevant applications, and also provides a large bibliography.
* This paper is a draft of an article to be published in Neural Network World
Hidden Markov Models for Gene Sequence Classification: Classifying the VSG genes in the Trypanosoma brucei Genome
Oct 21, 2015

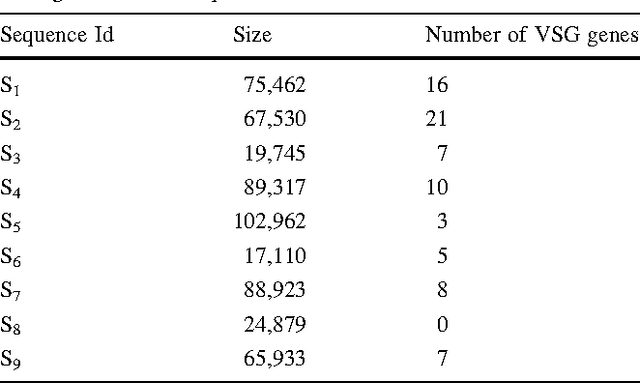
The article presents an application of Hidden Markov Models (HMMs) for pattern recognition on genome sequences. We apply HMM for identifying genes encoding the Variant Surface Glycoprotein (VSG) in the genomes of Trypanosoma brucei (T. brucei) and other African trypanosomes. These are parasitic protozoa causative agents of sleeping sickness and several diseases in domestic and wild animals. These parasites have a peculiar strategy to evade the host's immune system that consists in periodically changing their predominant cellular surface protein (VSG). The motivation for using patterns recognition methods to identify these genes, instead of traditional homology based ones, is that the levels of sequence identity (amino acid and DNA sequence) amongst these genes is often below of what is considered reliable in these methods. Among pattern recognition approaches, HMM are particularly suitable to tackle this problem because they can handle more naturally the determination of gene edges. We evaluate the performance of the model using different number of states in the Markov model, as well as several performance metrics. The model is applied using public genomic data. Our empirical results show that the VSG genes on T. brucei can be safely identified (high sensitivity and low rate of false positives) using HMM.
An Empirical Study of the L2-Boost technique with Echo State Networks
Jan 02, 2015
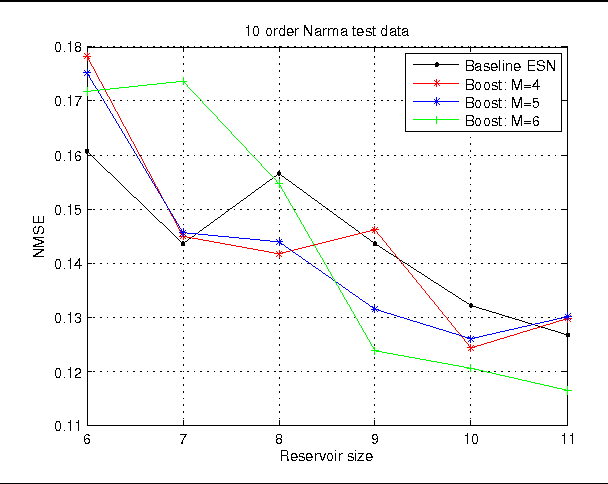

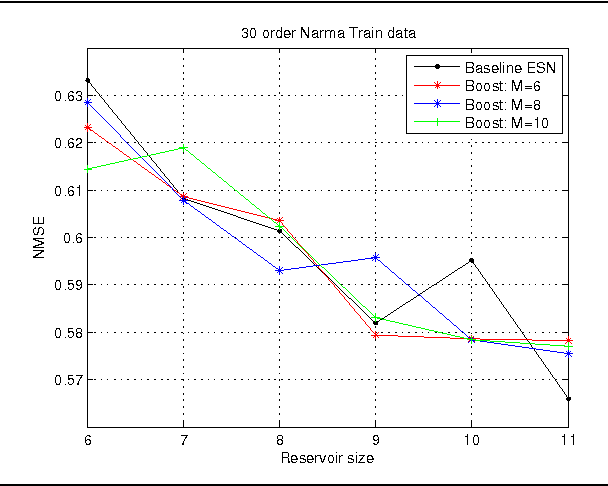
A particular case of Recurrent Neural Network (RNN) was introduced at the beginning of the 2000s under the name of Echo State Networks (ESNs). The ESN model overcomes the limitations during the training of the RNNs while introducing no significant disadvantages. Although the model presents some well-identified drawbacks when the parameters are not well initialised. The performance of an ESN is highly dependent on its internal parameters and pattern of connectivity of the hidden-hidden weights Often, the tuning of the network parameters can be hard and can impact in the accuracy of the models. In this work, we investigate the performance of a specific boosting technique (called L2-Boost) with ESNs as single predictors. The L2-Boost technique has been shown to be an effective tool to combine "weak" predictors in regression problems. In this study, we use an ensemble of random initialized ESNs (without control their parameters) as "weak" predictors of the boosting procedure. We evaluate our approach on five well-know time-series benchmark problems. Additionally, we compare this technique with a baseline approach that consists of averaging the prediction of an ensemble of ESNs.
An Experimental Analysis of the Echo State Network Initialization Using the Particle Swarm Optimization
Jan 02, 2015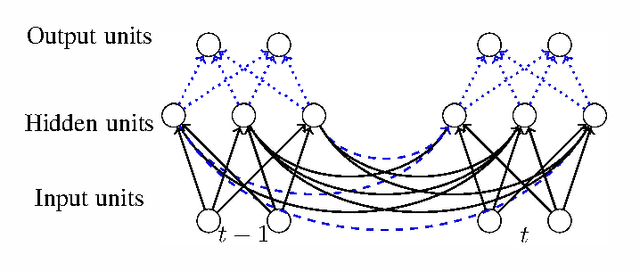


This article introduces a robust hybrid method for solving supervised learning tasks, which uses the Echo State Network (ESN) model and the Particle Swarm Optimization (PSO) algorithm. An ESN is a Recurrent Neural Network with the hidden-hidden weights fixed in the learning process. The recurrent part of the network stores the input information in internal states of the network. Another structure forms a free-memory method used as supervised learning tool. The setting procedure for initializing the recurrent structure of the ESN model can impact on the model performance. On the other hand, the PSO has been shown to be a successful technique for finding optimal points in complex spaces. Here, we present an approach to use the PSO for finding some initial hidden-hidden weights of the ESN model. We present empirical results that compare the canonical ESN model with this hybrid method on a wide range of benchmark problems.
Echo State Queueing Network: a new reservoir computing learning tool
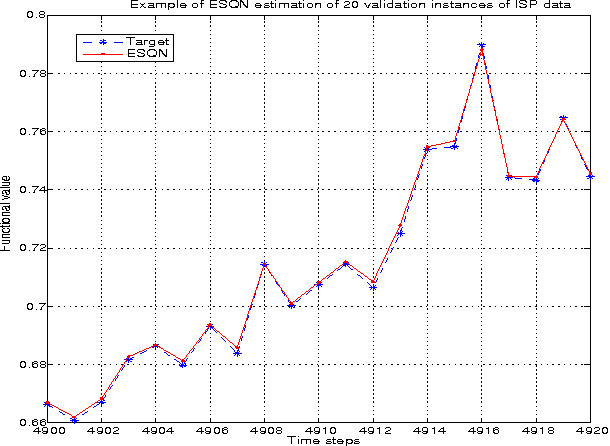
Dec 26, 2012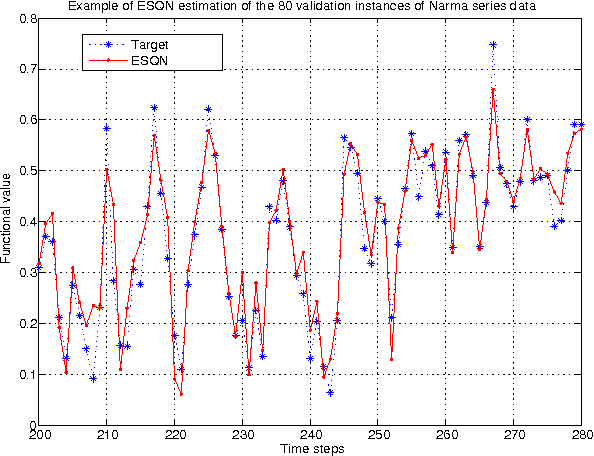


In the last decade, a new computational paradigm was introduced in the field of Machine Learning, under the name of Reservoir Computing (RC). RC models are neural networks which a recurrent part (the reservoir) that does not participate in the learning process, and the rest of the system where no recurrence (no neural circuit) occurs. This approach has grown rapidly due to its success in solving learning tasks and other computational applications. Some success was also observed with another recently proposed neural network designed using Queueing Theory, the Random Neural Network (RandNN). Both approaches have good properties and identified drawbacks. In this paper, we propose a new RC model called Echo State Queueing Network (ESQN), where we use ideas coming from RandNNs for the design of the reservoir. ESQNs consist in ESNs where the reservoir has a new dynamics inspired by recurrent RandNNs. The paper positions ESQNs in the global Machine Learning area, and provides examples of their use and performances. We show on largely used benchmarks that ESQNs are very accurate tools, and we illustrate how they compare with standard ESNs.