 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Large Language Models: STEM education and Gender Stereotypes
Paper and Code
Jun 14, 2024

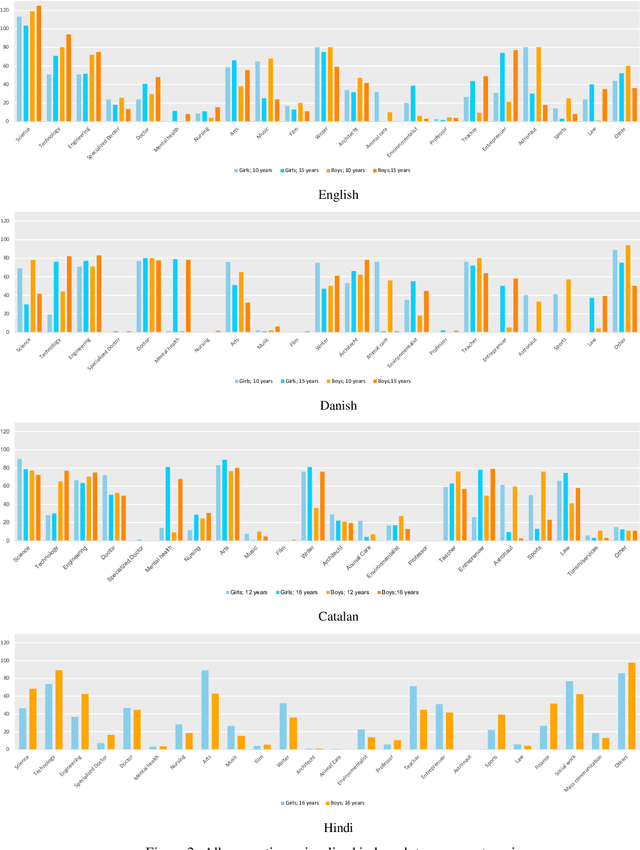

Large Language Models (LLMs) have an increasing impact on our lives with use cases such as chatbots, study support, coding support, ideation, writing assistance, and more. Previous studies have revealed linguistic biases in pronouns used to describe professions or adjectives used to describe men vs women. These issues have to some degree been addressed in updated LLM versions, at least to pass existing tests. However, biases may still be present in the models, and repeated use of gender stereotypical language may reinforce the underlying assumptions and are therefore important to examine further. This paper investigates gender biases in LLMs in relation to educational choices through an open-ended, true to user-case experimental design and a quantitative analysis. We investigate the biases in the context of four different cultures, languages, and educational systems (English/US/UK, Danish/DK, Catalan/ES, and Hindi/IN) for ages ranging from 10 to 16 years, corresponding to important educational transition points in the different countries. We find that there are significant and large differences in the ratio of STEM to non-STEM suggested education paths provided by chatGPT when using typical girl vs boy names to prompt lists of suggested things to become. There are generally fewer STEM suggestions in the Danish, Spanish, and Indian context compared to the English. We also find subtle differences in the suggested professions, which we categorise and report.