 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards A Conceptually Simple Defensive Approach for Few-shot classifiers Against Adversarial Support Samples
Oct 24, 2021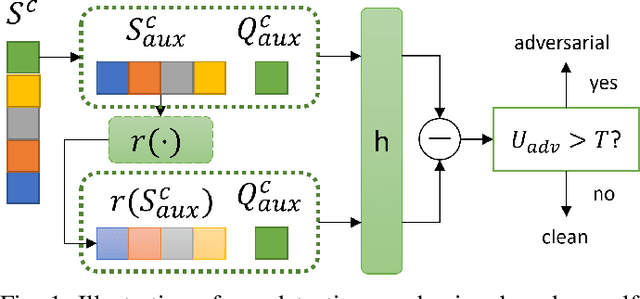
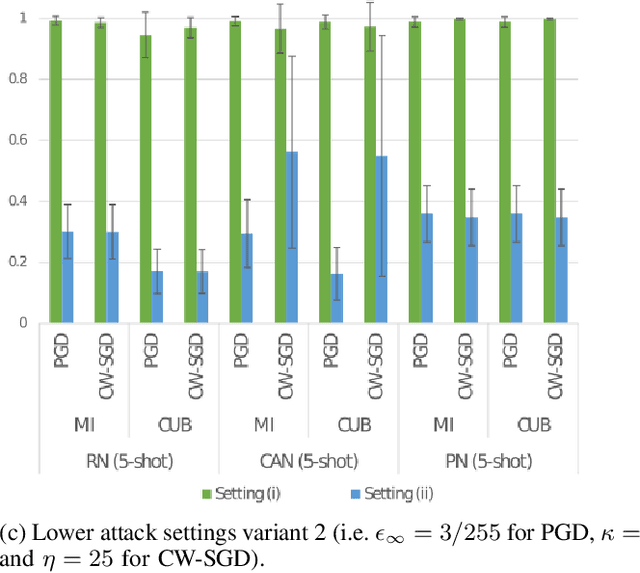
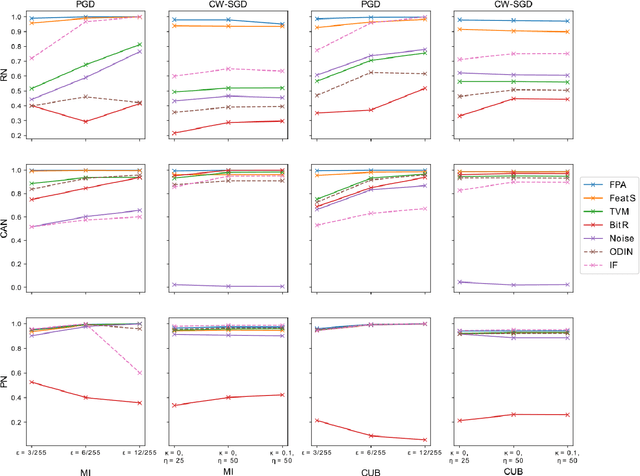
Few-shot classifiers have been shown to exhibit promising results in use cases where user-provided labels are scarce. These models are able to learn to predict novel classes simply by training on a non-overlapping set of classes. This can be largely attributed to the differences in their mechanisms as compared to conventional deep networks. However, this also offers new opportunities for novel attackers to induce integrity attacks against such models, which are not present in other machine learning setups. In this work, we aim to close this gap by studying a conceptually simple approach to defend few-shot classifiers against adversarial attacks. More specifically, we propose a simple attack-agnostic detection method, using the concept of self-similarity and filtering, to flag out adversarial support sets which destroy the understanding of a victim classifier for a certain class. Our extended evaluation on the miniImagenet (MI) and CUB datasets exhibit good attack detection performance, across three different few-shot classifiers and across different attack strengths, beating baselines. Our observed results allow our approach to establishing itself as a strong detection method for support set poisoning attacks. We also show that our approach constitutes a generalizable concept, as it can be paired with other filtering functions. Finally, we provide an analysis of our results when we vary two components found in our detection approach.
Detection of Adversarial Supports in Few-shot Classifiers Using Feature Preserving Autoencoders and Self-Similarity
Dec 09, 2020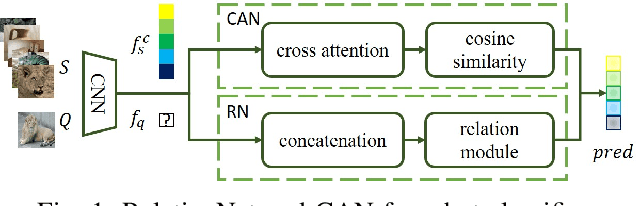
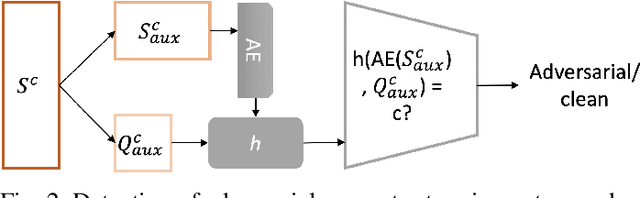
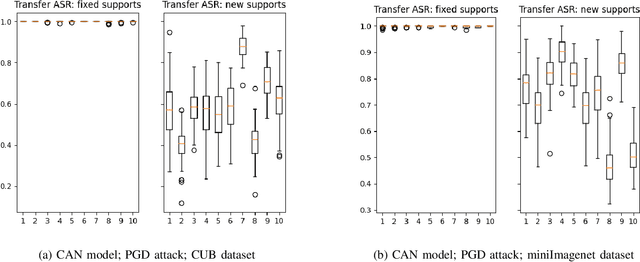
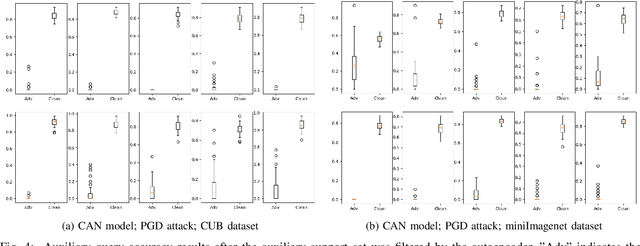
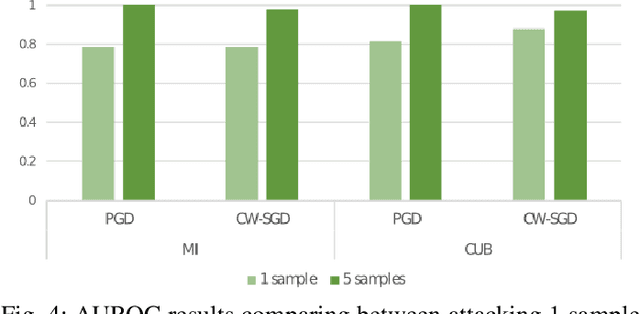
Few-shot classifiers excel under limited training samples, making it useful in real world applications. However, the advent of adversarial samples threatens the efficacy of such classifiers. For them to remain reliable, defences against such attacks must be explored. However, closer examination to prior literature reveals a big gap in this domain. Hence, in this work, we propose a detection strategy to highlight adversarial support sets, aiming to destroy a few-shot classifier's understanding of a certain class of objects. We make use of feature preserving autoencoder filtering and also the concept of self-similarity of a support set to perform this detection. As such, our method is attack-agnostic and also the first to explore detection for few-shot classifiers to the best of our knowledge. Our evaluation on the miniImagenet and CUB datasets exhibit optimism when employing our proposed approach, showing high AUROC scores for detection in general.
Exploring the Back Alleys: Analysing The Robustness of Alternative Neural Network Architectures against Adversarial Attacks
Jan 07, 2020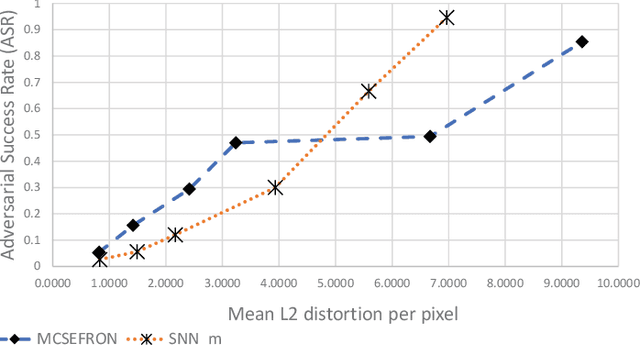


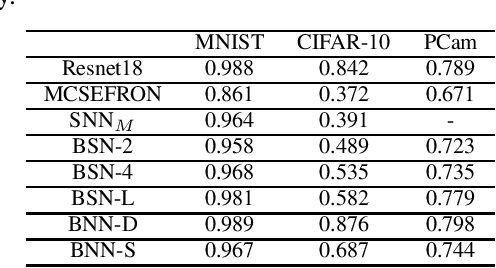
Recent discoveries in the field of adversarial machine learning have shown that Artificial Neural Networks (ANNs) are susceptible to adversarial attacks. These attacks cause misclassification of specially crafted adversarial samples. In light of this phenomenon, it is worth investigating whether other types of neural networks are less susceptible to adversarial attacks. In this work, we applied standard attack methods originally aimed at conventional ANNs, towards stochastic ANNs and also towards Spiking Neural Networks (SNNs), across three different datasets namely MNIST, CIFAR-10 and Patch Camelyon. We analysed their adversarial robustness against attacks performed in the raw image space of the different model variants. We employ a variety of attacks namely Basic Iterative Method (BIM), Carlini & Wagner L2 attack (CWL2) and Boundary attack. Our results suggests that SNNs and stochastic ANNs exhibit some degree of adversarial robustness as compared to their ANN counterparts under certain attack methods. Namely, we found that the Boundary and the state-of-the-art CWL2 attacks are largely ineffective against stochastic ANNs. Following this observation, we proposed a modified version of the CWL2 attack and analysed the impact of this attack on the models' adversarial robustness. Our results suggest that with this modified CWL2 attack, many models are more easily fooled as compared to the vanilla CWL2 attack, albeit observing an increase in L2 norms of adversarial perturbations. Lastly, we also investigate the resilience of alternative neural networks against adversarial samples transferred from ResNet18. We show that the modified CWL2 attack provides an improved cross-architecture transferability compared to other attacks.
Adversarial Attacks on Remote User Authentication Using Behavioural Mouse Dynamics
May 28, 2019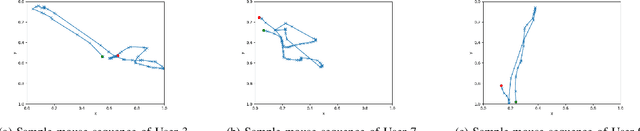
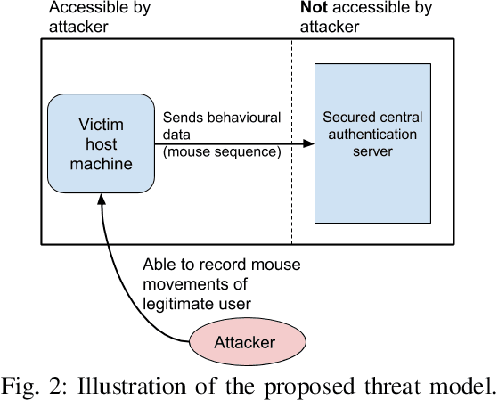
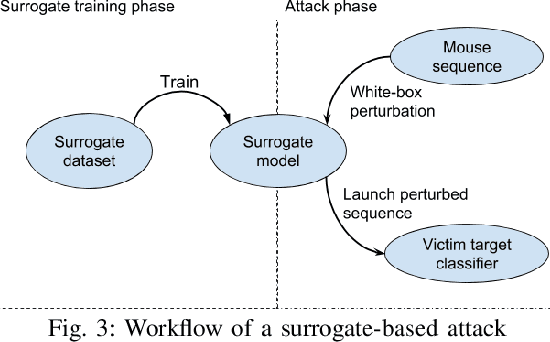
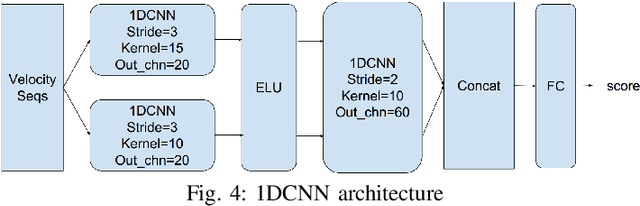
Mouse dynamics is a potential means of authenticating users. Typically, the authentication process is based on classical machine learning techniques, but recently, deep learning techniques have been introduced for this purpose. Although prior research has demonstrated how machine learning and deep learning algorithms can be bypassed by carefully crafted adversarial samples, there has been very little research performed on the topic of behavioural biometrics in the adversarial domain. In an attempt to address this gap, we built a set of attacks, which are applications of several generative approaches, to construct adversarial mouse trajectories that bypass authentication models. These generated mouse sequences will serve as the adversarial samples in the context of our experiments. We also present an analysis of the attack approaches we explored, explaining their limitations. In contrast to previous work, we consider the attacks in a more realistic and challenging setting in which an attacker has access to recorded user data but does not have access to the authentication model or its outputs. We explore three different attack strategies: 1) statistics-based, 2) imitation-based, and 3) surrogate-based; we show that they are able to evade the functionality of the authentication models, thereby impacting their robustness adversely. We show that imitation-based attacks often perform better than surrogate-based attacks, unless, however, the attacker can guess the architecture of the authentication model. In such cases, we propose a potential detection mechanism against surrogate-based attacks.