 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalk, Evaluate, Diagnose: User-aware Agent Evaluation with Automated Error Analysis
Mar 16, 2026Agent applications are increasingly adopted to automate workflows across diverse tasks. However, due to the heterogeneous domains they operate in, it is challenging to create a scalable evaluation framework. Prior works each employ their own methods to determine task success, such as database lookups, regex match, etc., adding complexity to the development of a unified agent evaluation approach. Moreover, they do not systematically account for the user's role nor expertise in the interaction, providing incomplete insights into the agent's performance. We argue that effective agent evaluation goes beyond correctness alone, incorporating conversation quality, efficiency and systematic diagnosis of agent errors. To address this, we introduce the TED framework (Talk, Evaluate, Diagnose). (1) Talk: We leverage reusable, generic expert and non-expert user persona templates for user-agent interaction. (2) Evaluate: We adapt existing datasets by representing subgoals-such as tool signatures, and responses-as natural language grading notes, evaluated automatically with LLM-as-a-judge. We propose new metrics that capture both turn efficiency and intermediate progress of the agent complementing the user-aware setup. (3) Diagnose: We introduce an automated error analysis tool that analyzes the inconsistencies of the judge and agents, uncovering common errors, and providing actionable feedback for agent improvement. We show that our TED framework reveals new insights regarding agent performance across models and user expertise levels. We also demonstrate potential gains in agent performance with peaks of 8-10% on our proposed metrics after incorporating the identified error remedies into the agent's design.
Efficiently Distilling LLMs for Edge Applications
Apr 01, 2024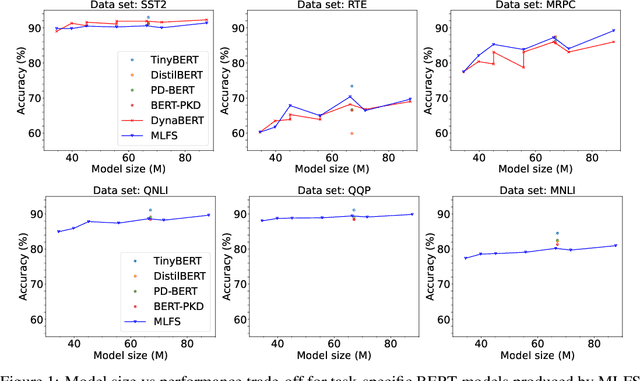
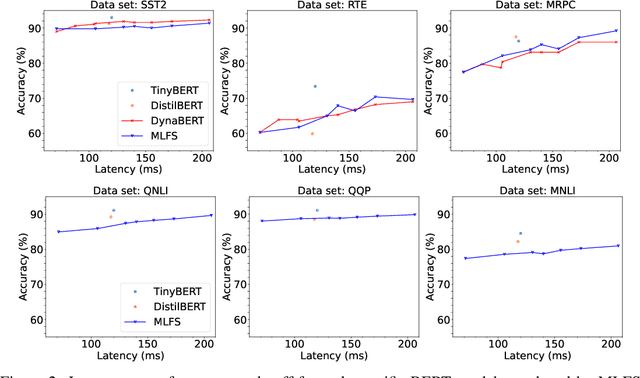
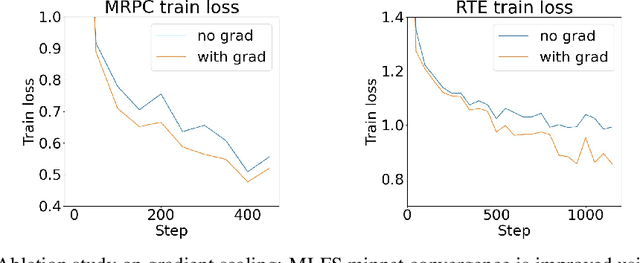
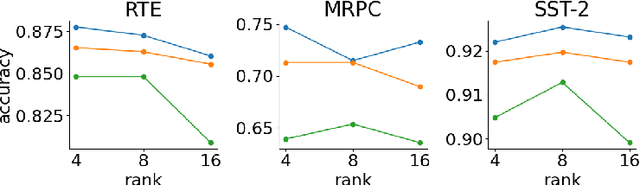
Supernet training of LLMs is of great interest in industrial applications as it confers the ability to produce a palette of smaller models at constant cost, regardless of the number of models (of different size / latency) produced. We propose a new method called Multistage Low-rank Fine-tuning of Super-transformers (MLFS) for parameter-efficient supernet training. We show that it is possible to obtain high-quality encoder models that are suitable for commercial edge applications, and that while decoder-only models are resistant to a comparable degree of compression, decoders can be effectively sliced for a significant reduction in training time.
Towards A Conceptually Simple Defensive Approach for Few-shot classifiers Against Adversarial Support Samples
Oct 24, 2021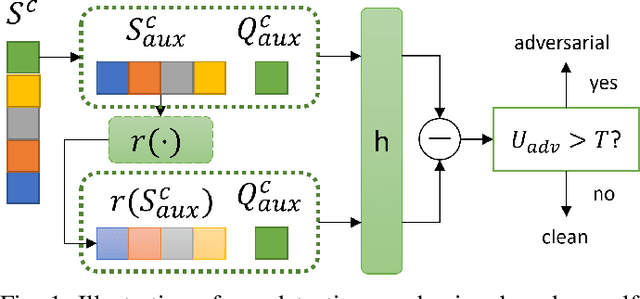
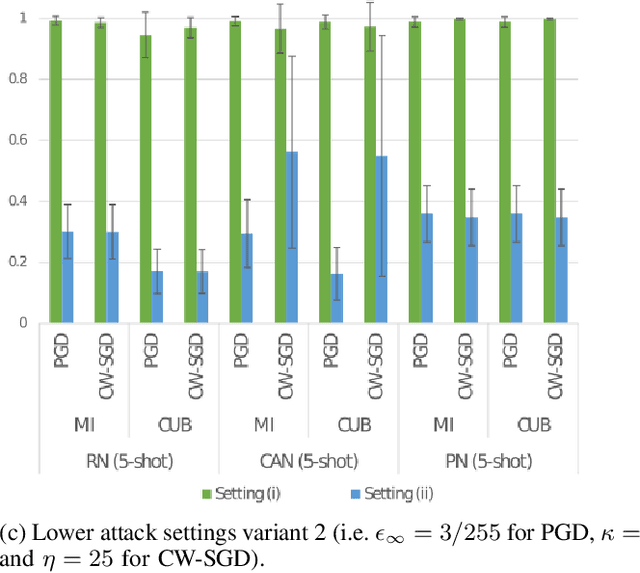
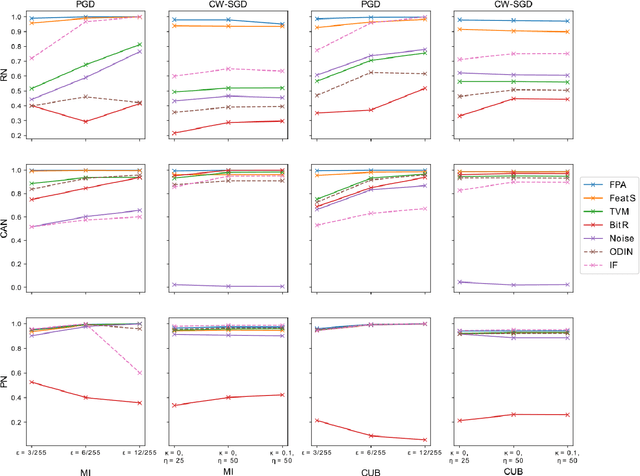
Few-shot classifiers have been shown to exhibit promising results in use cases where user-provided labels are scarce. These models are able to learn to predict novel classes simply by training on a non-overlapping set of classes. This can be largely attributed to the differences in their mechanisms as compared to conventional deep networks. However, this also offers new opportunities for novel attackers to induce integrity attacks against such models, which are not present in other machine learning setups. In this work, we aim to close this gap by studying a conceptually simple approach to defend few-shot classifiers against adversarial attacks. More specifically, we propose a simple attack-agnostic detection method, using the concept of self-similarity and filtering, to flag out adversarial support sets which destroy the understanding of a victim classifier for a certain class. Our extended evaluation on the miniImagenet (MI) and CUB datasets exhibit good attack detection performance, across three different few-shot classifiers and across different attack strengths, beating baselines. Our observed results allow our approach to establishing itself as a strong detection method for support set poisoning attacks. We also show that our approach constitutes a generalizable concept, as it can be paired with other filtering functions. Finally, we provide an analysis of our results when we vary two components found in our detection approach.
Detection of Adversarial Supports in Few-shot Classifiers Using Feature Preserving Autoencoders and Self-Similarity
Dec 09, 2020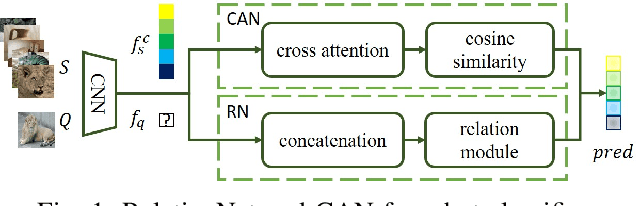
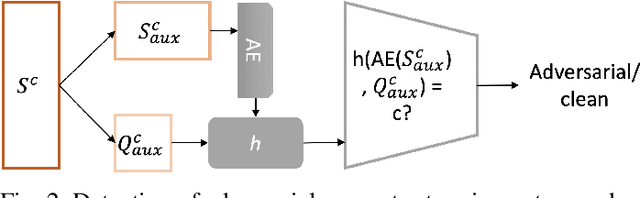
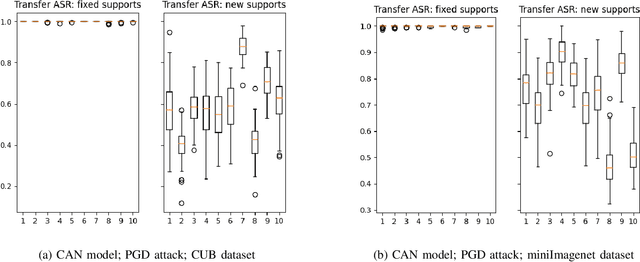
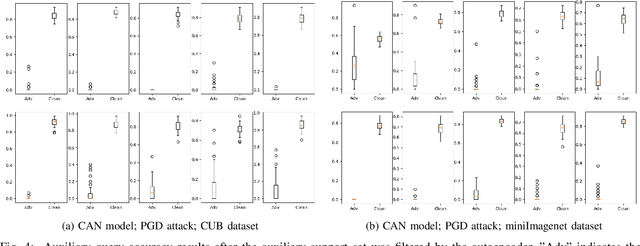
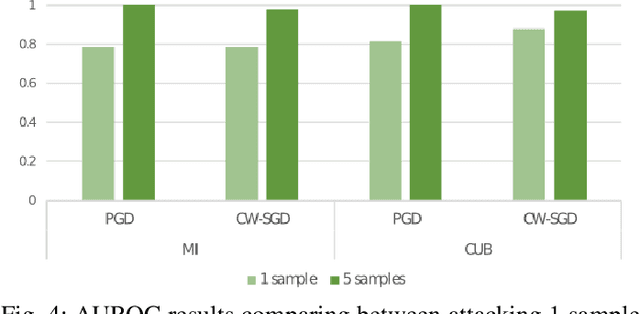
Few-shot classifiers excel under limited training samples, making it useful in real world applications. However, the advent of adversarial samples threatens the efficacy of such classifiers. For them to remain reliable, defences against such attacks must be explored. However, closer examination to prior literature reveals a big gap in this domain. Hence, in this work, we propose a detection strategy to highlight adversarial support sets, aiming to destroy a few-shot classifier's understanding of a certain class of objects. We make use of feature preserving autoencoder filtering and also the concept of self-similarity of a support set to perform this detection. As such, our method is attack-agnostic and also the first to explore detection for few-shot classifiers to the best of our knowledge. Our evaluation on the miniImagenet and CUB datasets exhibit optimism when employing our proposed approach, showing high AUROC scores for detection in general.
Deja vu from the SVM Era: Example-based Explanations with Outlier Detection
Nov 11, 2020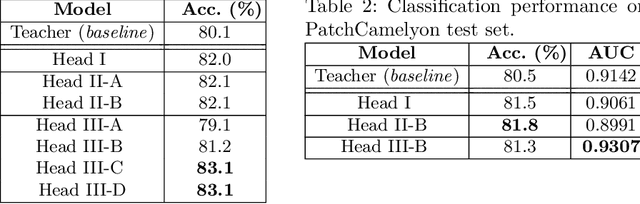
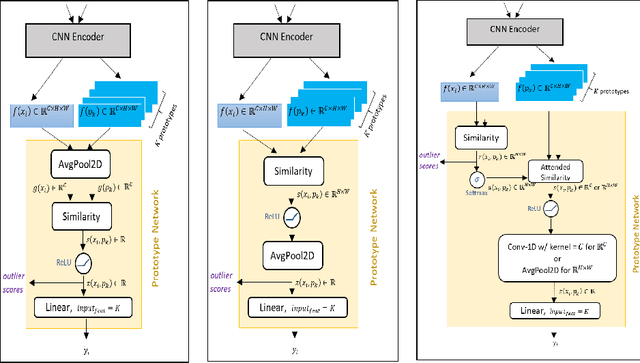
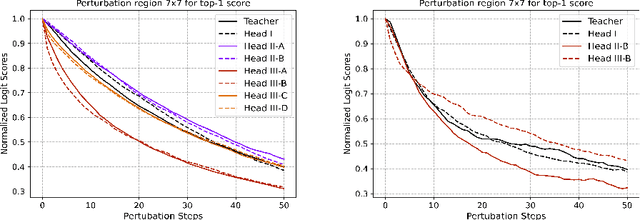
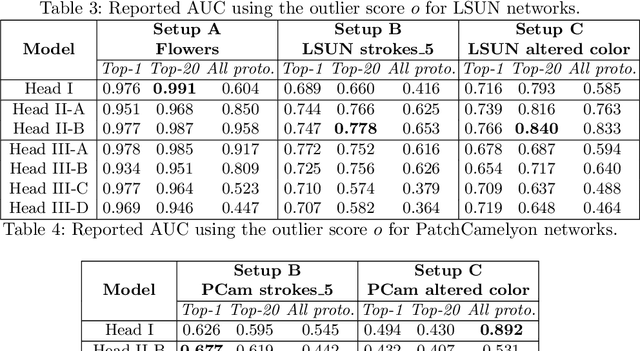
Understanding the features that contributed to a prediction is important for high-stake tasks. In this work, we revisit the idea of a student network to provide an example-based explanation for its prediction in two forms: i) identify top-k most relevant prototype examples and ii) show evidence of similarity between the prediction sample and each of the top-k prototypes. We compare the prediction performance and the explanation performance for the second type of explanation with the teacher network. In addition, we evaluate the outlier detection performance of the network. We show that using prototype-based students beyond similarity kernels deliver meaningful explanations and promising outlier detection results, without compromising on classification accuracy.
Simple and Effective Prevention of Mode Collapse in Deep One-Class Classification
Jan 28, 2020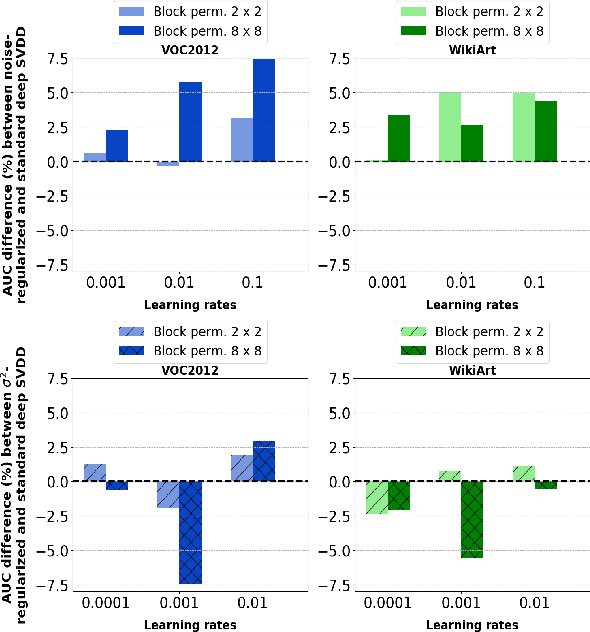
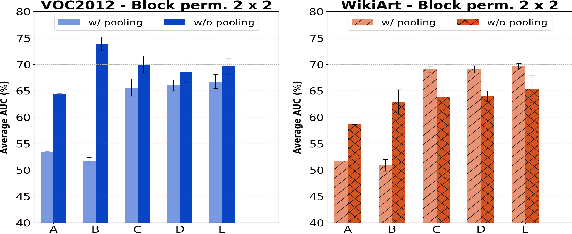
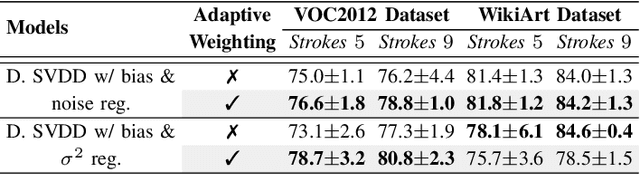

Anomaly detection algorithms find extensive use in various fields. This area of research has recently made great advances thanks to deep learning. A recent method, the deep Support Vector Data Description (deep SVDD), which is inspired by the classic kernel-based Support Vector Data Description (SVDD), is capable of simultaneously learning a feature representation of the data and a data-enclosing hypersphere. The method has shown promising results in both unsupervised and semi-supervised settings. However, deep SVDD suffers from hypersphere collapse---also known as mode collapse---, if the architecture of the model does not comply with certain architectural constraints, e.g. the removal of bias terms. These constraints limit the adaptability of the model and in some cases, may affect the model performance due to learning sub-optimal features. In this work, we consider two regularizers to prevent hypersphere collapse in deep SVDD. The first regularizer is based on injecting random noise via the standard cross-entropy loss. The second regularizer penalizes the minibatch variance when it becomes too small. Moreover, we introduce an adaptive weighting scheme to control the amount of penalization between the SVDD loss and the respective regularizer. Our proposed regularized variants of deep SVDD show encouraging results and outperform a prominent state-of-the-art method on a setup where the anomalies have no apparent geometrical structure.