 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Training Efficiency Using Packing with Flash Attention
Jul 12, 2024



Padding is often used in tuning LLM models by adding special tokens to shorter training examples to match the length of the longest sequence in each batch. While this ensures uniformity for batch processing, it introduces inefficiencies by including irrelevant padding tokens in the computation and wastes GPU resources. On the other hand, the Hugging Face SFT trainer offers the option to use packing to combine multiple training examples up to the maximum sequence length. This allows for maximal utilization of GPU resources. However, without proper masking of each packed training example, attention will not be computed correctly when using SFT trainer. We enable and then analyse packing and Flash Attention with proper attention masking of each example and show the benefits of this training paradigm.
Efficiently Distilling LLMs for Edge Applications
Apr 01, 2024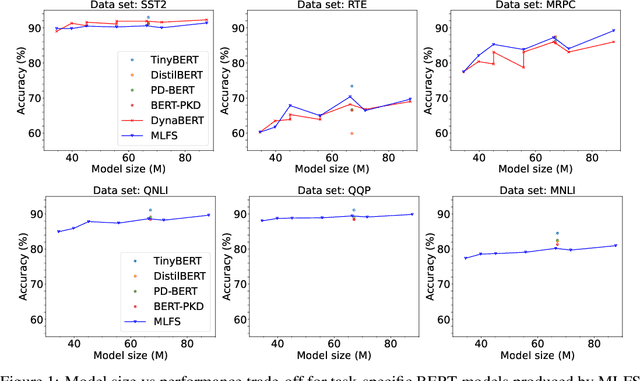
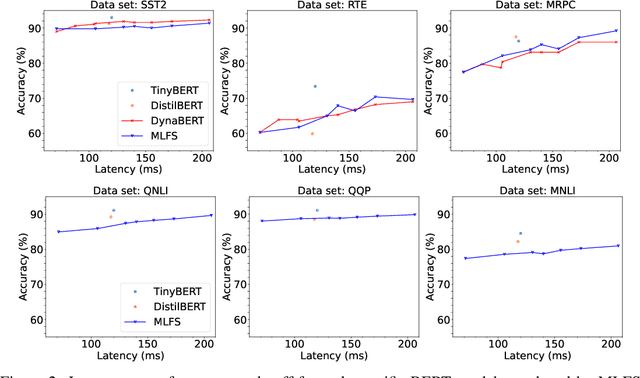
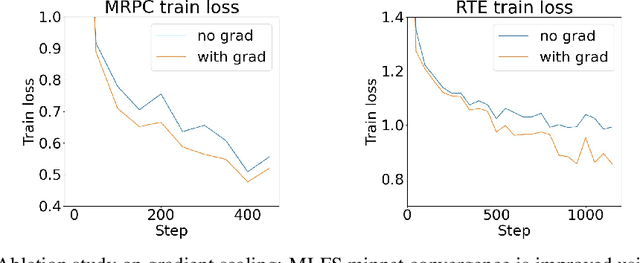
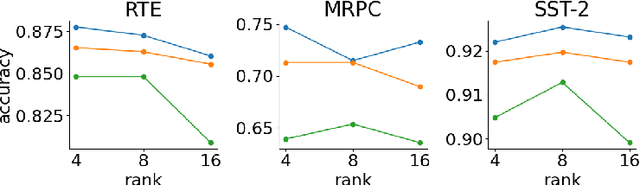
Supernet training of LLMs is of great interest in industrial applications as it confers the ability to produce a palette of smaller models at constant cost, regardless of the number of models (of different size / latency) produced. We propose a new method called Multistage Low-rank Fine-tuning of Super-transformers (MLFS) for parameter-efficient supernet training. We show that it is possible to obtain high-quality encoder models that are suitable for commercial edge applications, and that while decoder-only models are resistant to a comparable degree of compression, decoders can be effectively sliced for a significant reduction in training time.
TOFA: Transfer-Once-for-All
Mar 27, 2023



Weight-sharing neural architecture search aims to optimize a configurable neural network model (supernet) for a variety of deployment scenarios across many devices with different resource constraints. Existing approaches use evolutionary search to extract a number of models from a supernet trained on a very large data set, and then fine-tune the extracted models on the typically small, real-world data set of interest. The computational cost of training thus grows linearly with the number of different model deployment scenarios. Hence, we propose Transfer-Once-For-All (TOFA) for supernet-style training on small data sets with constant computational training cost over any number of edge deployment scenarios. Given a task, TOFA obtains custom neural networks, both the topology and the weights, optimized for any number of edge deployment scenarios. To overcome the challenges arising from small data, TOFA utilizes a unified semi-supervised training loss to simultaneously train all subnets within the supernet, coupled with on-the-fly architecture selection at deployment time.