 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Security of AI-Based Code Synthesis with GitHub Copilot via Cheap and Efficient Prompt-Engineering
Mar 19, 2024



AI assistants for coding are on the rise. However one of the reasons developers and companies avoid harnessing their full potential is the questionable security of the generated code. This paper first reviews the current state-of-the-art and identifies areas for improvement on this issue. Then, we propose a systematic approach based on prompt-altering methods to achieve better code security of (even proprietary black-box) AI-based code generators such as GitHub Copilot, while minimizing the complexity of the application from the user point-of-view, the computational resources, and operational costs. In sum, we propose and evaluate three prompt altering methods: (1) scenario-specific, (2) iterative, and (3) general clause, while we discuss their combination. Contrary to the audit of code security, the latter two of the proposed methods require no expert knowledge from the user. We assess the effectiveness of the proposed methods on the GitHub Copilot using the OpenVPN project in realistic scenarios, and we demonstrate that the proposed methods reduce the number of insecure generated code samples by up to 16\% and increase the number of secure code by up to 8\%. Since our approach does not require access to the internals of the AI models, it can be in general applied to any AI-based code synthesizer, not only GitHub Copilot.
ASNM Datasets: A Collection of Network Traffic Features for Testing of Adversarial Classifiers and Network Intrusion Detectors
Oct 23, 2019



In this paper, we present three datasets that have been built from network traffic traces using ASNM features, designed in our previous work. The first dataset was built using a state-of-the-art dataset called CDX 2009, while the remaining two datasets were collected by us in 2015 and 2018, respectively. These two datasets contain several adversarial obfuscation techniques that were applied onto malicious as well as legitimate traffic samples during the execution of particular TCP network connections. Adversarial obfuscation techniques were used for evading machine learning-based network intrusion detection classifiers. Further, we showed that the performance of such classifiers can be improved when partially augmenting their training data by samples obtained from obfuscation techniques. In detail, we utilized tunneling obfuscation in HTTP(S) protocol and non-payload-based obfuscations modifying various properties of network traffic by, e.g., TCP segmentation, re-transmissions, corrupting and reordering of packets, etc. To the best of our knowledge, this is the first collection of network traffic metadata that contains adversarial techniques and is intended for non-payload-based network intrusion detection and adversarial classification. Provided datasets enable testing of the evasion resistance of arbitrary classifier that is using ASNM features.
Adversarial Attacks on Remote User Authentication Using Behavioural Mouse Dynamics
May 28, 2019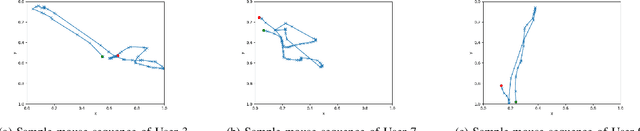
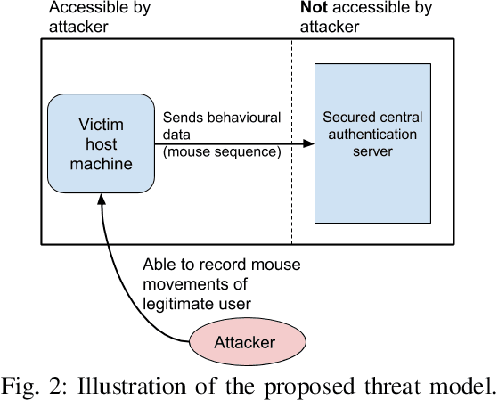
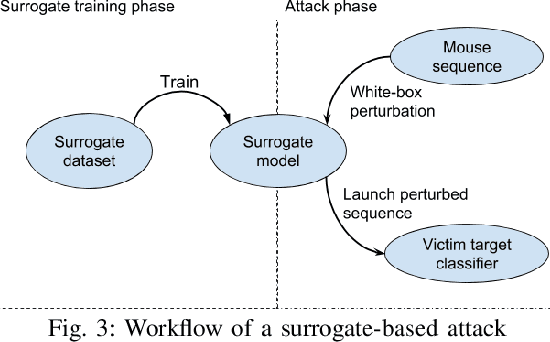
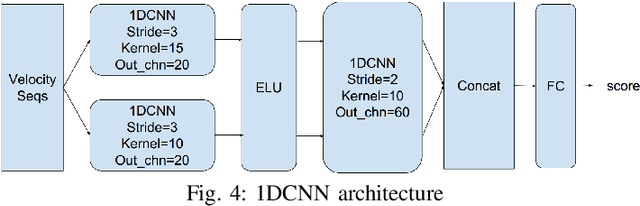
Mouse dynamics is a potential means of authenticating users. Typically, the authentication process is based on classical machine learning techniques, but recently, deep learning techniques have been introduced for this purpose. Although prior research has demonstrated how machine learning and deep learning algorithms can be bypassed by carefully crafted adversarial samples, there has been very little research performed on the topic of behavioural biometrics in the adversarial domain. In an attempt to address this gap, we built a set of attacks, which are applications of several generative approaches, to construct adversarial mouse trajectories that bypass authentication models. These generated mouse sequences will serve as the adversarial samples in the context of our experiments. We also present an analysis of the attack approaches we explored, explaining their limitations. In contrast to previous work, we consider the attacks in a more realistic and challenging setting in which an attacker has access to recorded user data but does not have access to the authentication model or its outputs. We explore three different attack strategies: 1) statistics-based, 2) imitation-based, and 3) surrogate-based; we show that they are able to evade the functionality of the authentication models, thereby impacting their robustness adversely. We show that imitation-based attacks often perform better than surrogate-based attacks, unless, however, the attacker can guess the architecture of the authentication model. In such cases, we propose a potential detection mechanism against surrogate-based attacks.