 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Explaining: Opportunities and Challenges of XAI-Based Model Improvement
Paper and Code
Mar 15, 2022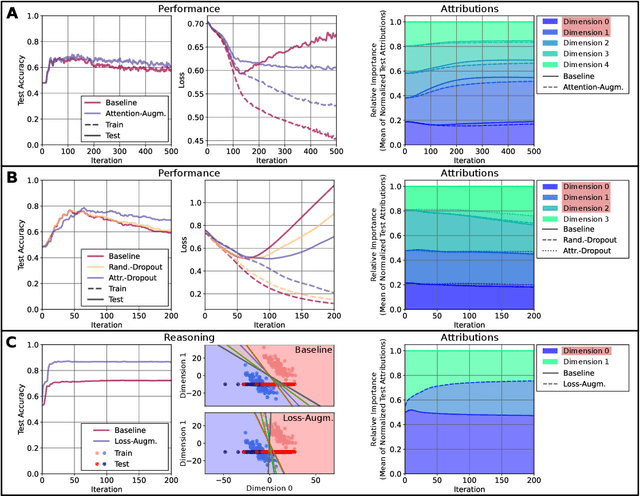

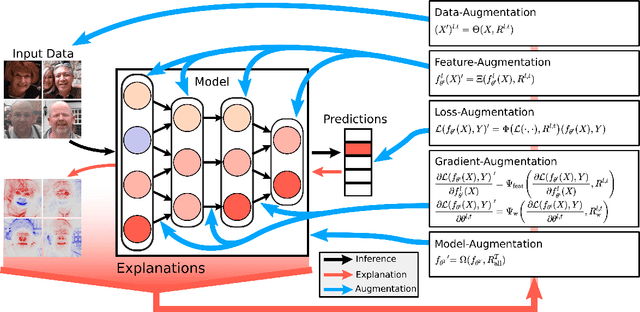

Explainable Artificial Intelligence (XAI) is an emerging research field bringing transparency to highly complex and opaque machine learning (ML) models. Despite the development of a multitude of methods to explain the decisions of black-box classifiers in recent years, these tools are seldomly used beyond visualization purposes. Only recently, researchers have started to employ explanations in practice to actually improve models. This paper offers a comprehensive overview over techniques that apply XAI practically for improving various properties of ML models, and systematically categorizes these approaches, comparing their respective strengths and weaknesses. We provide a theoretical perspective on these methods, and show empirically through experiments on toy and realistic settings how explanations can help improve properties such as model generalization ability or reasoning, among others. We further discuss potential caveats and drawbacks of these methods. We conclude that while model improvement based on XAI can have significant beneficial effects even on complex and not easily quantifyable model properties, these methods need to be applied carefully, since their success can vary depending on a multitude of factors, such as the model and dataset used, or the employed explanation method.