 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEditYourself: Audio-Driven Generation and Manipulation of Talking Head Videos with Diffusion Transformers
Jan 29, 2026Current generative video models excel at producing novel content from text and image prompts, but leave a critical gap in editing existing pre-recorded videos, where minor alterations to the spoken script require preserving motion, temporal coherence, speaker identity, and accurate lip synchronization. We introduce EditYourself, a DiT-based framework for audio-driven video-to-video (V2V) editing that enables transcript-based modification of talking head videos, including the seamless addition, removal, and retiming of visually spoken content. Building on a general-purpose video diffusion model, EditYourself augments its V2V capabilities with audio conditioning and region-aware, edit-focused training extensions. This enables precise lip synchronization and temporally coherent restructuring of existing performances via spatiotemporal inpainting, including the synthesis of realistic human motion in newly added segments, while maintaining visual fidelity and identity consistency over long durations. This work represents a foundational step toward generative video models as practical tools for professional video post-production.
Video-Driven Animation of Neural Head Avatars
Mar 07, 2024



We present a new approach for video-driven animation of high-quality neural 3D head models, addressing the challenge of person-independent animation from video input. Typically, high-quality generative models are learned for specific individuals from multi-view video footage, resulting in person-specific latent representations that drive the generation process. In order to achieve person-independent animation from video input, we introduce an LSTM-based animation network capable of translating person-independent expression features into personalized animation parameters of person-specific 3D head models. Our approach combines the advantages of personalized head models (high quality and realism) with the convenience of video-driven animation employing multi-person facial performance capture. We demonstrate the effectiveness of our approach on synthesized animations with high quality based on different source videos as well as an ablation study.
Unsupervised Learning of Style-Aware Facial Animation from Real Acting Performances
Jun 16, 2023



This paper presents a novel approach for text/speech-driven animation of a photo-realistic head model based on blend-shape geometry, dynamic textures, and neural rendering. Training a VAE for geometry and texture yields a parametric model for accurate capturing and realistic synthesis of facial expressions from a latent feature vector. Our animation method is based on a conditional CNN that transforms text or speech into a sequence of animation parameters. In contrast to previous approaches, our animation model learns disentangling/synthesizing different acting-styles in an unsupervised manner, requiring only phonetic labels that describe the content of training sequences. For realistic real-time rendering, we train a U-Net that refines rasterization-based renderings by computing improved pixel colors and a foreground matte. We compare our framework qualitatively/quantitatively against recent methods for head modeling as well as facial animation and evaluate the perceived rendering/animation quality in a user-study, which indicates large improvements compared to state-of-the-art approaches
Neural Face Models for Example-Based Visual Speech Synthesis
Sep 22, 2020

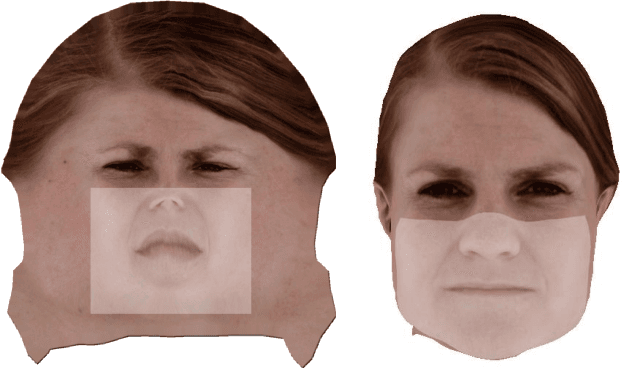

Creating realistic animations of human faces with computer graphic models is still a challenging task. It is often solved either with tedious manual work or motion capture based techniques that require specialised and costly hardware. Example based animation approaches circumvent these problems by re-using captured data of real people. This data is split into short motion samples that can be looped or concatenated in order to create novel motion sequences. The obvious advantages of this approach are the simplicity of use and the high realism, since the data exhibits only real deformations. Rather than tuning weights of a complex face rig, the animation task is performed on a higher level by arranging typical motion samples in a way such that the desired facial performance is achieved. Two difficulties with example based approaches, however, are high memory requirements as well as the creation of artefact-free and realistic transitions between motion samples. We solve these problems by combining the realism and simplicity of example-based animations with the advantages of neural face models. Our neural face model is capable of synthesising high quality 3D face geometry and texture according to a compact latent parameter vector. This latent representation reduces memory requirements by a factor of 100 and helps creating seamless transitions between concatenated motion samples. In this paper, we present a marker-less approach for facial motion capture based on multi-view video. Based on the captured data, we learn a neural representation of facial expressions, which is used to seamlessly concatenate facial performances during the animation procedure. We demonstrate the effectiveness of our approach by synthesising mouthings for Swiss-German sign language based on viseme query sequences.
Going beyond Free Viewpoint: Creating Animatable Volumetric Video of Human Performances
Sep 02, 2020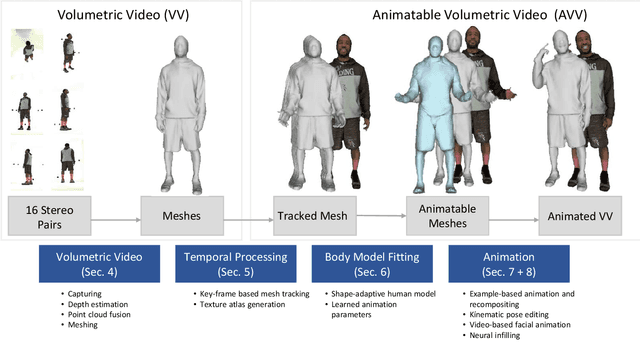

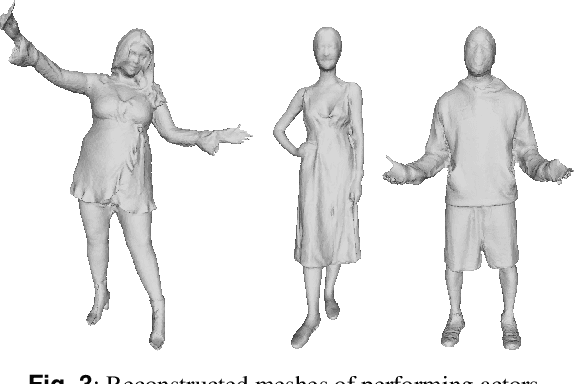
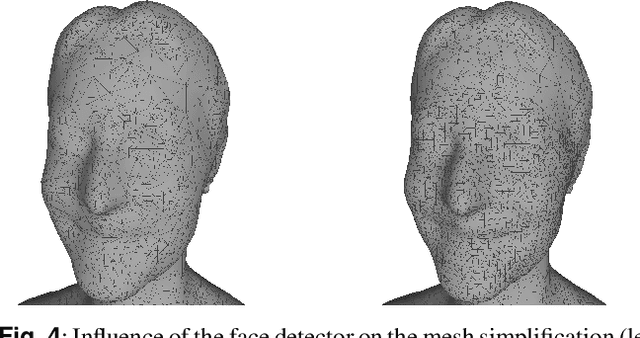
In this paper, we present an end-to-end pipeline for the creation of high-quality animatable volumetric video content of human performances. Going beyond the application of free-viewpoint volumetric video, we allow re-animation and alteration of an actor's performance through (i) the enrichment of the captured data with semantics and animation properties and (ii) applying hybrid geometry- and video-based animation methods that allow a direct animation of the high-quality data itself instead of creating an animatable model that resembles the captured data. Semantic enrichment and geometric animation ability are achieved by establishing temporal consistency in the 3D data, followed by an automatic rigging of each frame using a parametric shape-adaptive full human body model. Our hybrid geometry- and video-based animation approaches combine the flexibility of classical CG animation with the realism of real captured data. For pose editing, we exploit the captured data as much as possible and kinematically deform the captured frames to fit a desired pose. Further, we treat the face differently from the body in a hybrid geometry- and video-based animation approach where coarse movements and poses are modeled in the geometry only, while very fine and subtle details in the face, often lacking in purely geometric methods, are captured in video-based textures. These are processed to be interactively combined to form new facial expressions. On top of that, we learn the appearance of regions that are challenging to synthesize, such as the teeth or the eyes, and fill in missing regions realistically in an autoencoder-based approach. This paper covers the full pipeline from capturing and producing high-quality video content, over the enrichment with semantics and deformation properties for re-animation and processing of the data for the final hybrid animation.