 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoing beyond Free Viewpoint: Creating Animatable Volumetric Video of Human Performances
Sep 02, 2020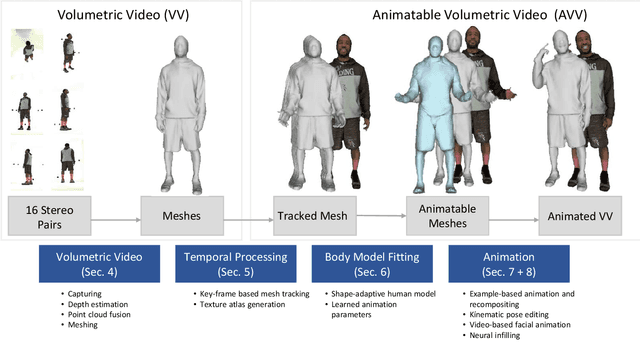

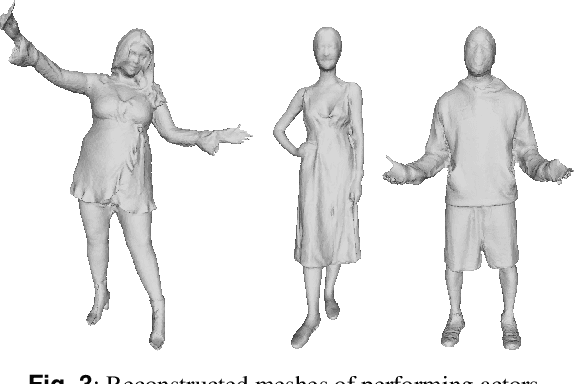
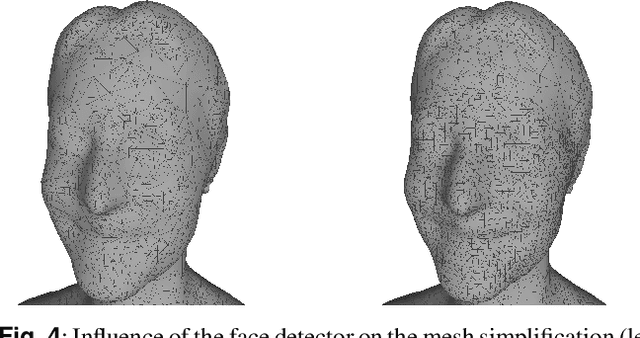
In this paper, we present an end-to-end pipeline for the creation of high-quality animatable volumetric video content of human performances. Going beyond the application of free-viewpoint volumetric video, we allow re-animation and alteration of an actor's performance through (i) the enrichment of the captured data with semantics and animation properties and (ii) applying hybrid geometry- and video-based animation methods that allow a direct animation of the high-quality data itself instead of creating an animatable model that resembles the captured data. Semantic enrichment and geometric animation ability are achieved by establishing temporal consistency in the 3D data, followed by an automatic rigging of each frame using a parametric shape-adaptive full human body model. Our hybrid geometry- and video-based animation approaches combine the flexibility of classical CG animation with the realism of real captured data. For pose editing, we exploit the captured data as much as possible and kinematically deform the captured frames to fit a desired pose. Further, we treat the face differently from the body in a hybrid geometry- and video-based animation approach where coarse movements and poses are modeled in the geometry only, while very fine and subtle details in the face, often lacking in purely geometric methods, are captured in video-based textures. These are processed to be interactively combined to form new facial expressions. On top of that, we learn the appearance of regions that are challenging to synthesize, such as the teeth or the eyes, and fill in missing regions realistically in an autoencoder-based approach. This paper covers the full pipeline from capturing and producing high-quality video content, over the enrichment with semantics and deformation properties for re-animation and processing of the data for the final hybrid animation.