 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHard Sample Matters a Lot in Zero-Shot Quantization
Mar 24, 2023



Zero-shot quantization (ZSQ) is promising for compressing and accelerating deep neural networks when the data for training full-precision models are inaccessible. In ZSQ, network quantization is performed using synthetic samples, thus, the performance of quantized models depends heavily on the quality of synthetic samples. Nonetheless, we find that the synthetic samples constructed in existing ZSQ methods can be easily fitted by models. Accordingly, quantized models obtained by these methods suffer from significant performance degradation on hard samples. To address this issue, we propose HArd sample Synthesizing and Training (HAST). Specifically, HAST pays more attention to hard samples when synthesizing samples and makes synthetic samples hard to fit when training quantized models. HAST aligns features extracted by full-precision and quantized models to ensure the similarity between features extracted by these two models. Extensive experiments show that HAST significantly outperforms existing ZSQ methods, achieving performance comparable to models that are quantized with real data.
ASCNet: Self-supervised Video Representation Learning with Appearance-Speed Consistency
Jun 04, 2021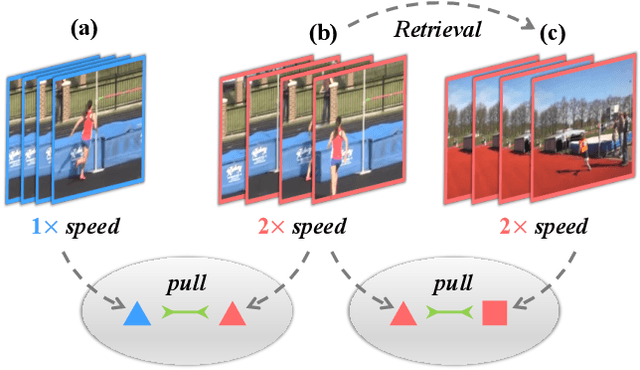

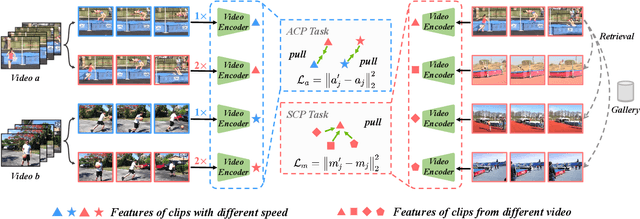

We study self-supervised video representation learning, which is a challenging task due to 1) a lack of labels for explicit supervision and 2) unstructured and noisy visual information. Existing methods mainly use contrastive loss with video clips as the instances and learn visual representation by discriminating instances from each other, but they require careful treatment of negative pairs by relying on large batch sizes, memory banks, extra modalities, or customized mining strategies, inevitably including noisy data. In this paper, we observe that the consistency between positive samples is the key to learn robust video representations. Specifically, we propose two tasks to learn the appearance and speed consistency, separately. The appearance consistency task aims to maximize the similarity between two clips of the same video with different playback speeds. The speed consistency task aims to maximize the similarity between two clips with the same playback speed but different appearance information. We show that joint optimization of the two tasks consistently improves the performance on downstream tasks, e.g., action recognition and video retrieval. Remarkably, for action recognition on the UCF-101 dataset, we achieve 90.8% accuracy without using any additional modalities or negative pairs for unsupervised pretraining, outperforming the ImageNet supervised pre-trained model. Codes and models will be available.