 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Attentional Network for Semantic Segmentation
Paper and Code
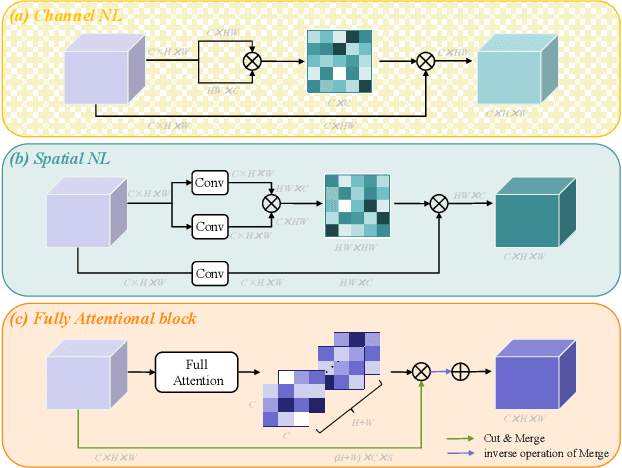



Recent non-local self-attention methods have proven to be effective in capturing long-range dependencies for semantic segmentation. These methods usually form a similarity map of RC*C (by compressing spatial dimensions) or RHW*HW (by compressing channels) to describe the feature relations along either channel or spatial dimensions, where C is the number of channels, H and W are the spatial dimensions of the input feature map. However, such practices tend to condense feature dependencies along the other dimensions,hence causing attention missing, which might lead to inferior results for small/thin categories or inconsistent segmentation inside large objects. To address this problem, we propose anew approach, namely Fully Attentional Network (FLANet),to encode both spatial and channel attentions in a single similarity map while maintaining high computational efficiency. Specifically, for each channel map, our FLANet can harvest feature responses from all other channel maps, and the associated spatial positions as well, through a novel fully attentional module. Our new method has achieved state-of-the-art performance on three challenging semantic segmentation datasets,i.e., 83.6%, 46.99%, and 88.5% on the Cityscapes test set,the ADE20K validation set, and the PASCAL VOC test set,respectively.