 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse View Distractor-Free Gaussian Splatting
Mar 02, 20263D Gaussian Splatting (3DGS) enables efficient training and fast novel view synthesis in static environments. To address challenges posed by transient objects, distractor-free 3DGS methods have emerged and shown promising results when dense image captures are available. However, their performance degrades significantly under sparse input conditions. This limitation primarily stems from the reliance on the color residual heuristics to guide the training, which becomes unreliable with limited observations. In this work, we propose a framework to enhance distractor-free 3DGS under sparse-view conditions by incorporating rich prior information. Specifically, we first adopt the geometry foundation model VGGT to estimate camera parameters and generate a dense set of initial 3D points. Then, we harness the attention maps from VGGT for efficient and accurate semantic entity matching. Additionally, we utilize Vision-Language Models (VLMs) to further identify and preserve the large static regions in the scene. We also demonstrate how these priors can be seamlessly integrated into existing distractor-free 3DGS methods. Extensive experiments confirm the effectiveness and robustness of our approach in mitigating transient distractors for sparse-view 3DGS training.
Sharpening Your Density Fields: Spiking Neuron Aided Fast Geometry Learning
Dec 13, 2024



Neural Radiance Fields (NeRF) have achieved remarkable progress in neural rendering. Extracting geometry from NeRF typically relies on the Marching Cubes algorithm, which uses a hand-crafted threshold to define the level set. However, this threshold-based approach requires laborious and scenario-specific tuning, limiting its practicality for real-world applications. In this work, we seek to enhance the efficiency of this method during the training time. To this end, we introduce a spiking neuron mechanism that dynamically adjusts the threshold, eliminating the need for manual selection. Despite its promise, directly training with the spiking neuron often results in model collapse and noisy outputs. To overcome these challenges, we propose a round-robin strategy that stabilizes the training process and enables the geometry network to achieve a sharper and more precise density distribution with minimal computational overhead. We validate our approach through extensive experiments on both synthetic and real-world datasets. The results show that our method significantly improves the performance of threshold-based techniques, offering a more robust and efficient solution for NeRF geometry extraction.
Robust SG-NeRF: Robust Scene Graph Aided Neural Surface Reconstruction
Nov 20, 2024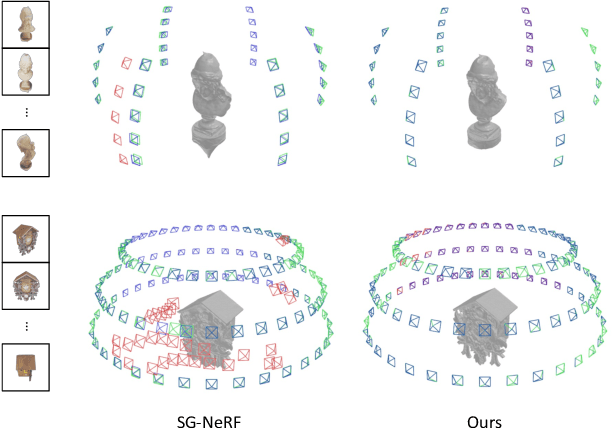
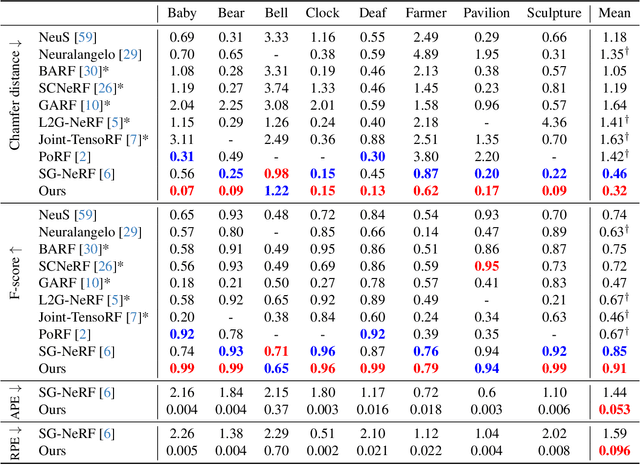
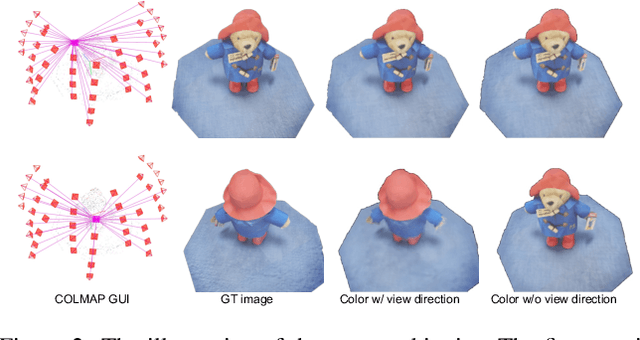

Neural surface reconstruction relies heavily on accurate camera poses as input. Despite utilizing advanced pose estimators like COLMAP or ARKit, camera poses can still be noisy. Existing pose-NeRF joint optimization methods handle poses with small noise (inliers) effectively but struggle with large noise (outliers), such as mirrored poses. In this work, we focus on mitigating the impact of outlier poses. Our method integrates an inlier-outlier confidence estimation scheme, leveraging scene graph information gathered during the data preparation phase. Unlike previous works directly using rendering metrics as the reference, we employ a detached color network that omits the viewing direction as input to minimize the impact caused by shape-radiance ambiguities. This enhanced confidence updating strategy effectively differentiates between inlier and outlier poses, allowing us to sample more rays from inlier poses to construct more reliable radiance fields. Additionally, we introduce a re-projection loss based on the current Signed Distance Function (SDF) and pose estimations, strengthening the constraints between matching image pairs. For outlier poses, we adopt a Monte Carlo re-localization method to find better solutions. We also devise a scene graph updating strategy to provide more accurate information throughout the training process. We validate our approach on the SG-NeRF and DTU datasets. Experimental results on various datasets demonstrate that our methods can consistently improve the reconstruction qualities and pose accuracies.