 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepCopy: Grounded Response Generation with Hierarchical Pointer Networks
Aug 28, 2019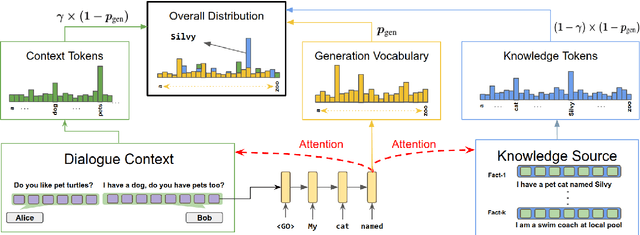
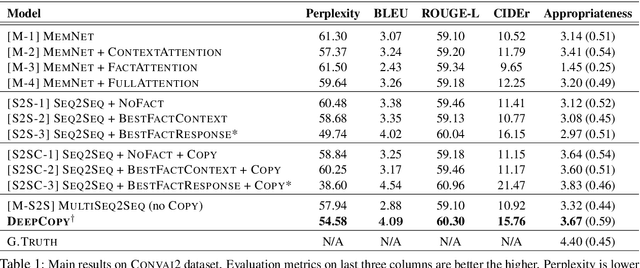
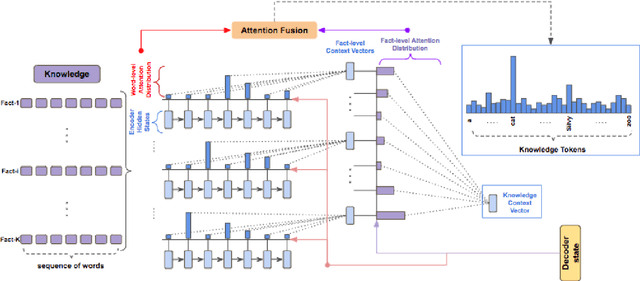
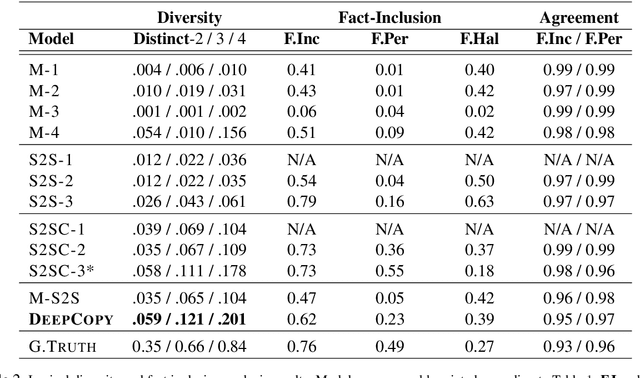
Recent advances in neural sequence-to-sequence models have led to promising results for several language generation-based tasks, including dialogue response generation, summarization, and machine translation. However, these models are known to have several problems, especially in the context of chit-chat based dialogue systems: they tend to generate short and dull responses that are often too generic. Furthermore, these models do not ground conversational responses on knowledge and facts, resulting in turns that are not accurate, informative and engaging for the users. In this paper, we propose and experiment with a series of response generation models that aim to serve in the general scenario where in addition to the dialogue context, relevant unstructured external knowledge in the form of text is also assumed to be available for models to harness. Our proposed approach extends pointer-generator networks (See et al., 2017) by allowing the decoder to hierarchically attend and copy from external knowledge in addition to the dialogue context. We empirically show the effectiveness of the proposed model compared to several baselines including (Ghazvininejad et al., 2018; Zhang et al., 2018) through both automatic evaluation metrics and human evaluation on CONVAI2 dataset.
Learning Question-Guided Video Representation for Multi-Turn Video Question Answering
Jul 31, 2019
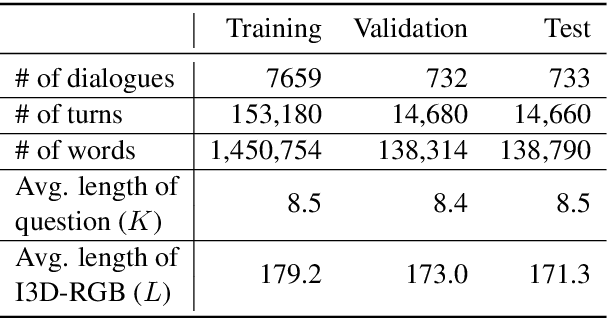
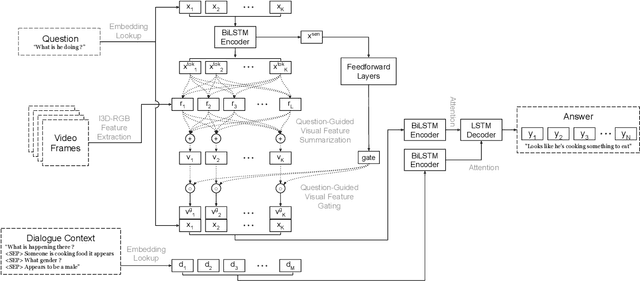
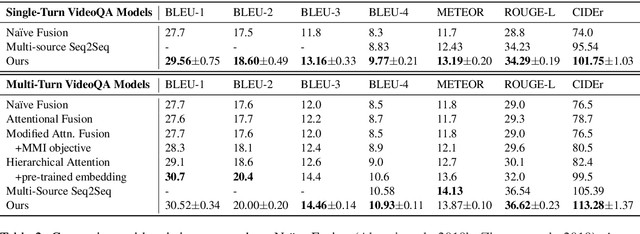
Understanding and conversing about dynamic scenes is one of the key capabilities of AI agents that navigate the environment and convey useful information to humans. Video question answering is a specific scenario of such AI-human interaction where an agent generates a natural language response to a question regarding the video of a dynamic scene. Incorporating features from multiple modalities, which often provide supplementary information, is one of the challenging aspects of video question answering. Furthermore, a question often concerns only a small segment of the video, hence encoding the entire video sequence using a recurrent neural network is not computationally efficient. Our proposed question-guided video representation module efficiently generates the token-level video summary guided by each word in the question. The learned representations are then fused with the question to generate the answer. Through empirical evaluation on the Audio Visual Scene-aware Dialog (AVSD) dataset, our proposed models in single-turn and multi-turn question answering achieve state-of-the-art performance on several automatic natural language generation evaluation metrics.
BERT-DST: Scalable End-to-End Dialogue State Tracking with Bidirectional Encoder Representations from Transformer
Jul 05, 2019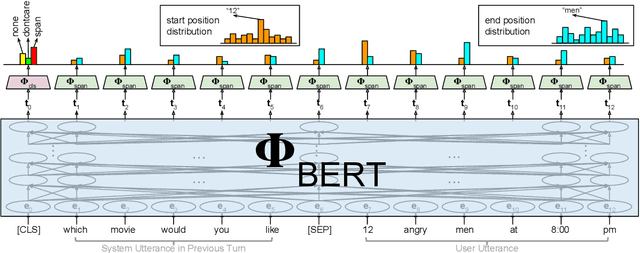

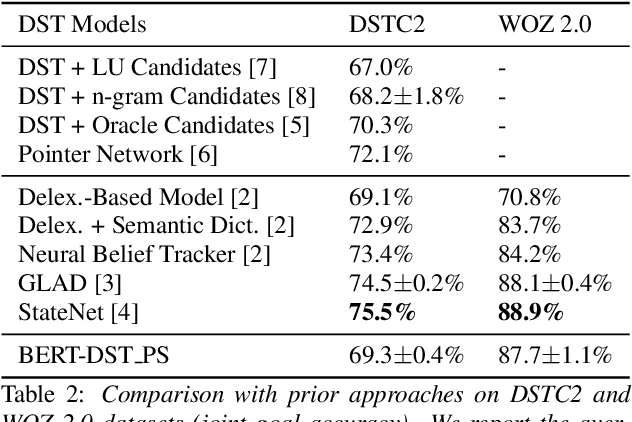
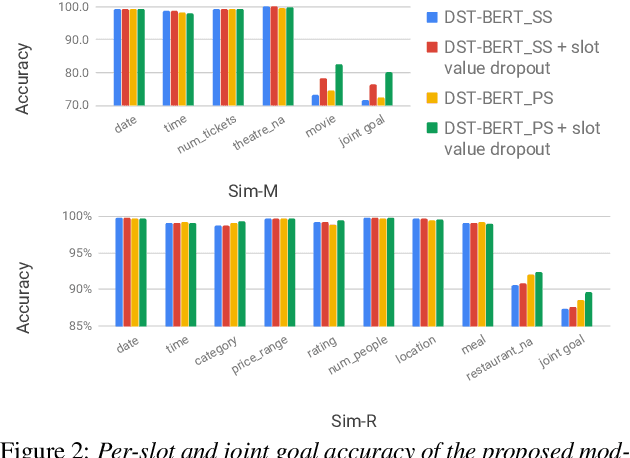
An important yet rarely tackled problem in dialogue state tracking (DST) is scalability for dynamic ontology (e.g., movie, restaurant) and unseen slot values. We focus on a specific condition, where the ontology is unknown to the state tracker, but the target slot value (except for none and dontcare), possibly unseen during training, can be found as word segment in the dialogue context. Prior approaches often rely on candidate generation from n-gram enumeration or slot tagger outputs, which can be inefficient or suffer from error propagation. We propose BERT-DST, an end-to-end dialogue state tracker which directly extracts slot values from the dialogue context. We use BERT as dialogue context encoder whose contextualized language representations are suitable for scalable DST to identify slot values from their semantic context. Furthermore, we employ encoder parameter sharing across all slots with two advantages: (1) Number of parameters does not grow linearly with the ontology. (2) Language representation knowledge can be transferred among slots. Empirical evaluation shows BERT-DST with cross-slot parameter sharing outperforms prior work on the benchmark scalable DST datasets Sim-M and Sim-R, and achieves competitive performance on the standard DSTC2 and WOZ 2.0 datasets.
Speaker-Targeted Audio-Visual Models for Speech Recognition in Cocktail-Party Environments
Jun 13, 2019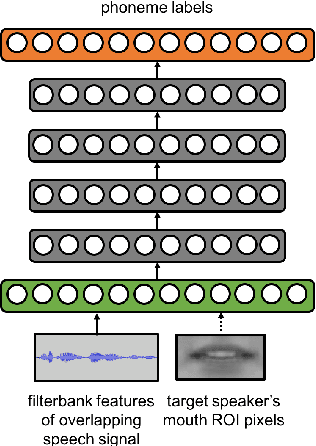
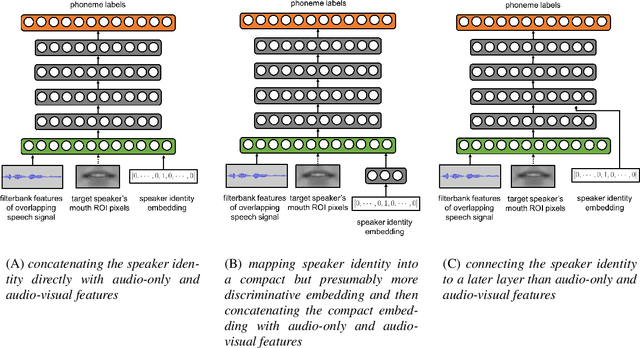
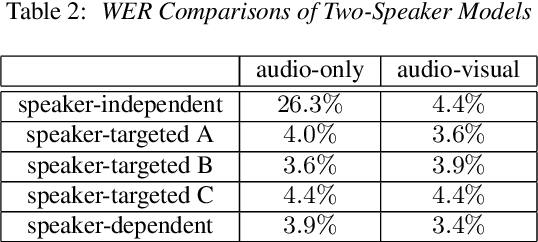
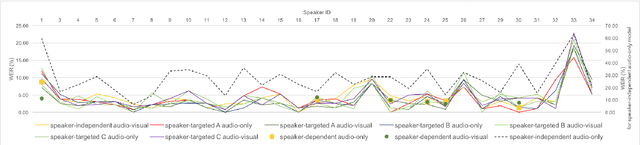
Speech recognition in cocktail-party environments remains a significant challenge for state-of-the-art speech recognition systems, as it is extremely difficult to extract an acoustic signal of an individual speaker from a background of overlapping speech with similar frequency and temporal characteristics. We propose the use of speaker-targeted acoustic and audio-visual models for this task. We complement the acoustic features in a hybrid DNN-HMM model with information of the target speaker's identity as well as visual features from the mouth region of the target speaker. Experimentation was performed using simulated cocktail-party data generated from the GRID audio-visual corpus by overlapping two speakers's speech on a single acoustic channel. Our audio-only baseline achieved a WER of 26.3%. The audio-visual model improved the WER to 4.4%. Introducing speaker identity information had an even more pronounced effect, improving the WER to 3.6%. Combining both approaches, however, did not significantly improve performance further. Our work demonstrates that speaker-targeted models can significantly improve the speech recognition in cocktail party environments.
City-Identification of Flickr Videos Using Semantic Acoustic Features
Jul 12, 2016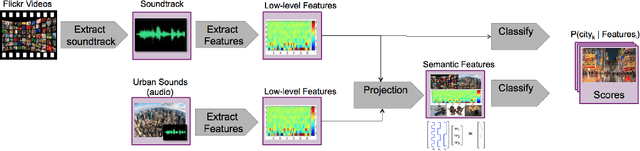
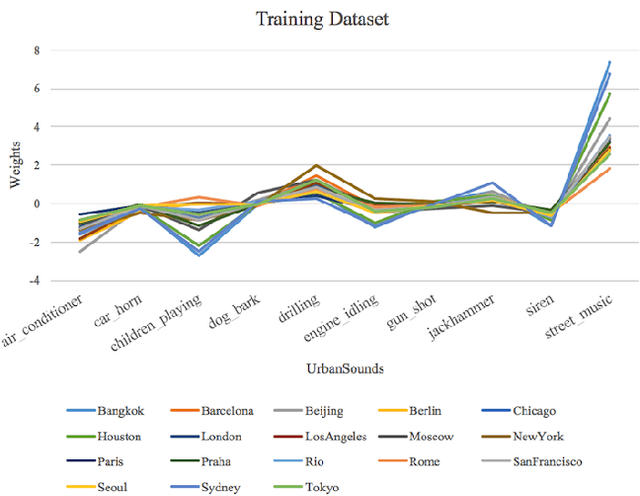
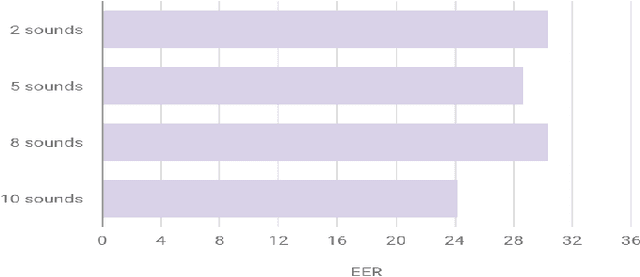
City-identification of videos aims to determine the likelihood of a video belonging to a set of cities. In this paper, we present an approach using only audio, thus we do not use any additional modality such as images, user-tags or geo-tags. In this manner, we show to what extent the city-location of videos correlates to their acoustic information. Success in this task suggests improvements can be made to complement the other modalities. In particular, we present a method to compute and use semantic acoustic features to perform city-identification and the features show semantic evidence of the identification. The semantic evidence is given by a taxonomy of urban sounds and expresses the potential presence of these sounds in the city- soundtracks. We used the MediaEval Placing Task set, which contains Flickr videos labeled by city. In addition, we used the UrbanSound8K set containing audio clips labeled by sound- type. Our method improved the state-of-the-art performance and provides a novel semantic approach to this task