 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Pooling Strategies for Training-Free Anomalous Sound Detection with Self-Supervised Audio Embeddings
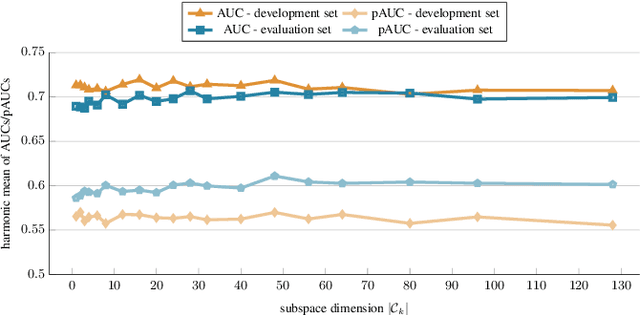
Mar 04, 2026Training-free anomalous sound detection (ASD) based on pre-trained audio embedding models has recently garnered significant attention, as it enables the detection of anomalous sounds using only normal reference data while offering improved robustness under domain shifts. However, existing embedding-based approaches almost exclusively rely on temporal mean pooling, while alternative pooling strategies have so far only been explored for spectrogram-based representations. Consequently, the role of temporal pooling in training-free ASD with pre-trained embeddings remains insufficiently understood. In this paper, we present a systematic evaluation of temporal pooling strategies across multiple state-of-the-art audio embedding models. We propose relative deviation pooling (RDP), an adaptive pooling method that emphasizes informative temporal deviations, and introduce a hybrid pooling strategy that combines RDP with generalized mean pooling. Experiments on five benchmark datasets demonstrate that the proposed methods consistently outperform mean pooling and achieve state-of-the-art performance for training-free ASD, including results that surpass all previously reported trained systems and ensembles on the DCASE2025 ASD dataset.
How Much Does Machine Identity Matter in Anomalous Sound Detection at Test Time?
Feb 18, 2026Anomalous sound detection (ASD) benchmarks typically assume that the identity of the monitored machine is known at test time and that recordings are evaluated in a machine-wise manner. However, in realistic monitoring scenarios with multiple known machines operating concurrently, test recordings may not be reliably attributable to a specific machine, and requiring machine identity imposes deployment constraints such as dedicated sensors per machine. To reveal performance degradations and method-specific differences in robustness that are hidden under standard machine-wise evaluation, we consider a minimal modification of the ASD evaluation protocol in which test recordings from multiple machines are merged and evaluated jointly without access to machine identity at inference time. Training data and evaluation metrics remain unchanged, and machine identity labels are used only for post hoc evaluation. Experiments with representative ASD methods show that relaxing this assumption reveals performance degradations and method-specific differences in robustness that are hidden under standard machine-wise evaluation, and that these degradations are strongly related to implicit machine identification accuracy.
DSpAST: Disentangled Representations for Spatial Audio Reasoning with Large Language Models
Sep 17, 2025Reasoning about spatial audio with large language models requires a spatial audio encoder as an acoustic front-end to obtain audio embeddings for further processing. Such an encoder needs to capture all information required to detect the type of sound events, as well as the direction and distance of their corresponding sources. Accomplishing this with a single audio encoder is demanding as the information required for each of these tasks is mostly independent of each other. As a result, the performance obtained with a single encoder is often worse than when using task-specific audio encoders. In this work, we present DSpAST, a novel audio encoder based on SpatialAST that learns disentangled representations of spatial audio while having only 0.2% additional parameters. Experiments on SpatialSoundQA with the spatial audio reasoning system BAT demonstrate that DSpAST significantly outperforms SpatialAST.
Handling Domain Shifts for Anomalous Sound Detection: A Review of DCASE-Related Work
Mar 13, 2025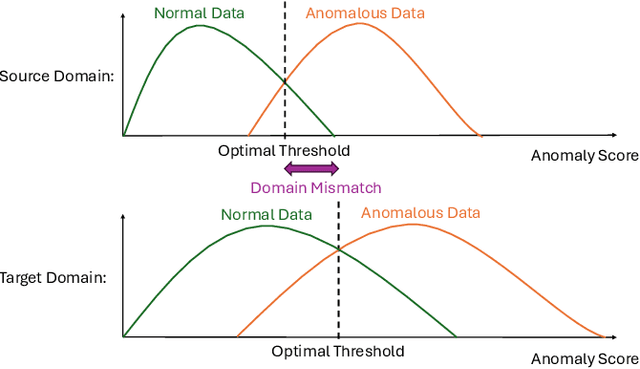
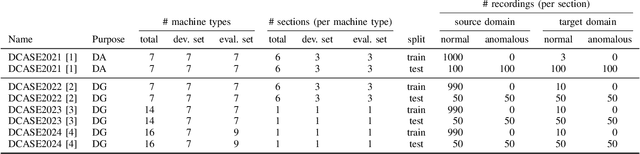
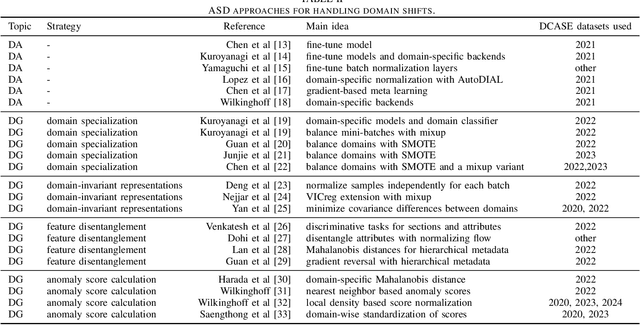
When detecting anomalous sounds in complex environments, one of the main difficulties is that trained models must be sensitive to subtle differences in monitored target signals, while many practical applications also require them to be insensitive to changes in acoustic domains. Examples of such domain shifts include changing the type of microphone or the location of acoustic sensors, which can have a much stronger impact on the acoustic signal than subtle anomalies themselves. Moreover, users typically aim to train a model only on source domain data, which they may have a relatively large collection of, and they hope that such a trained model will be able to generalize well to an unseen target domain by providing only a minimal number of samples to characterize the acoustic signals in that domain. In this work, we review and discuss recent publications focusing on this domain generalization problem for anomalous sound detection in the context of the DCASE challenges on acoustic machine condition monitoring.
Multi-Sample Dynamic Time Warping for Few-Shot Keyword Spotting
Apr 23, 2024In multi-sample keyword spotting, each keyword class is represented by multiple spoken instances, called samples. A na\"ive approach to detect keywords in a target sequence consists of querying all samples of all classes using sub-sequence dynamic time warping. However, the resulting processing time increases linearly with respect to the number of samples belonging to each class. Alternatively, only a single Fr\'echet mean can be queried for each class, resulting in reduced processing time but usually also in worse detection performance as the variability of the query samples is not captured sufficiently well. In this work, multi-sample dynamic time warping is proposed to compute class-specific cost-tensors that include the variability of all query samples. To significantly reduce the computational complexity during inference, these cost tensors are converted to cost matrices before applying dynamic time warping. In experimental evaluations for few-shot keyword spotting, it is shown that this method yields a very similar performance as using all individual query samples as templates while having a runtime that is only slightly slower than when using Fr\'echet means.
AdaProj: Adaptively Scaled Angular Margin Subspace Projections for Anomalous Sound Detection with Auxiliary Classification Tasks
Mar 21, 2024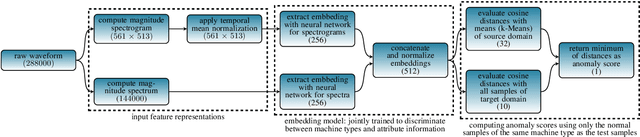

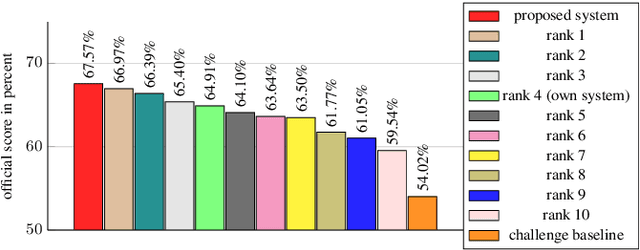
The state-of-the-art approach for semi-supervised anomalous sound detection is to first learn an embedding space by using auxiliary classification tasks based on meta information or self-supervised learning and then estimate the distribution of normal data. In this work, AdaProj a novel loss function is presented. In contrast to commonly used angular margin losses, which project data of each class as close as possible to their corresponding class centers, AdaProj learns to project data onto class-specific subspaces. By doing so, the resulting distributions of embeddings belonging to normal data are not required to be as restrictive as other loss functions allowing a more detailed view on the data. In experiments conducted on the DCASE2022 and DCASE2023 datasets, it is shown that using AdaProj to learn an embedding space significantly outperforms other commonly used loss functions and results in a state-of-the-art performance on the DCASE2023 dataset.
Projected Belief Networks With Discriminative Alignment for Acoustic Event Classification: Rivaling State of the Art CNNs
Jan 20, 2024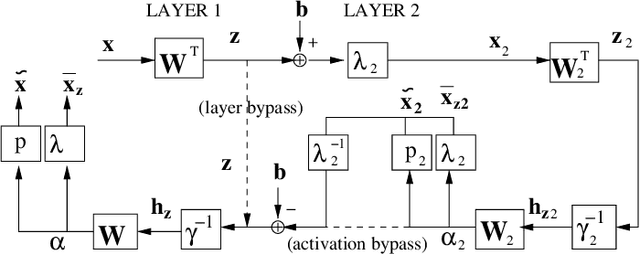
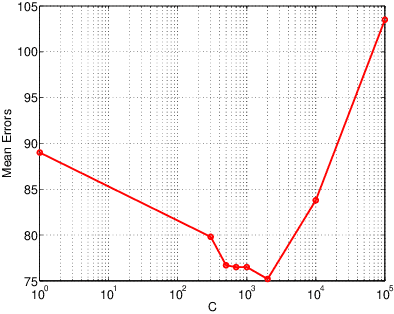
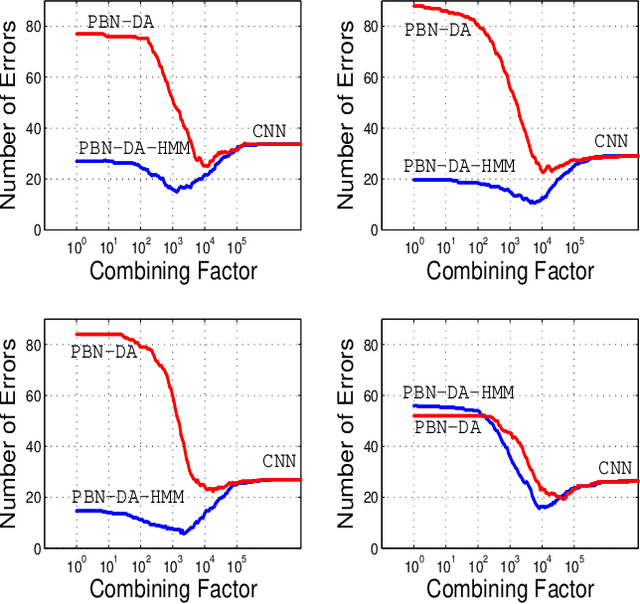
The projected belief network (PBN) is a generative stochastic network with tractable likelihood function based on a feed-forward neural network (FFNN). The generative function operates by "backing up" through the FFNN. The PBN is two networks in one, a FFNN that operates in the forward direction, and a generative network that operates in the backward direction. Both networks co-exist based on the same parameter set, have their own cost functions, and can be separately or jointly trained. The PBN therefore has the potential to possess the best qualities of both discriminative and generative classifiers. To realize this potential, a separate PBN is trained on each class, maximizing the generative likelihood function for the given class, while minimizing the discriminative cost for the FFNN against "all other classes". This technique, called discriminative alignment (PBN-DA), aligns the contours of the likelihood function to the decision boundaries and attains vastly improved classification performance, rivaling that of state of the art discriminative networks. The method may be further improved using a hidden Markov model (HMM) as a component of the PBN, called PBN-DA-HMM. This paper provides a comprehensive treatment of PBN, PBN-DA, and PBN-DA-HMM. In addition, the results of two new classification experiments are provided. The first experiment uses air-acoustic events, and the second uses underwater acoustic data consisting of marine mammal calls. In both experiments, PBN-DA-HMM attains comparable or better performance as a state of the art CNN, and attain a factor of two error reduction when combined with the CNN.
Self-Supervised Learning for Anomalous Sound Detection
Dec 15, 2023State-of-the-art anomalous sound detection (ASD) systems are often trained by using an auxiliary classification task to learn an embedding space. Doing so enables the system to learn embeddings that are robust to noise and are ignoring non-target sound events but requires manually annotated meta information to be used as class labels. However, the less difficult the classification task becomes, the less informative are the embeddings and the worse is the resulting ASD performance. A solution to this problem is to utilize self-supervised learning (SSL). In this work, feature exchange (FeatEx), a simple yet effective SSL approach for ASD, is proposed. In addition, FeatEx is compared to and combined with existing SSL approaches. As the main result, a new state-of-the-art performance for the DCASE2023 ASD dataset is obtained that outperforms all other published results on this dataset by a large margin.
F1-EV Score: Measuring the Likelihood of Estimating a Good Decision Threshold for Semi-Supervised Anomaly Detection
Dec 14, 2023Anomalous sound detection (ASD) systems are usually compared by using threshold-independent performance measures such as AUC-ROC. However, for practical applications a decision threshold is needed to decide whether a given test sample is normal or anomalous. Estimating such a threshold is highly non-trivial in a semi-supervised setting where only normal training samples are available. In this work, F1-EV a novel threshold-independent performance measure for ASD systems that also includes the likelihood of estimating a good decision threshold is proposed and motivated using specific toy examples. In experimental evaluations, multiple performance measures are evaluated for all systems submitted to the ASD task of the DCASE Challenge 2023. It is shown that F1-EV is strongly correlated with AUC-ROC while having a significantly stronger correlation with the F1-score obtained with estimated and optimal decision thresholds than AUC-ROC.
Why do Angular Margin Losses work well for Semi-Supervised Anomalous Sound Detection?
Sep 27, 2023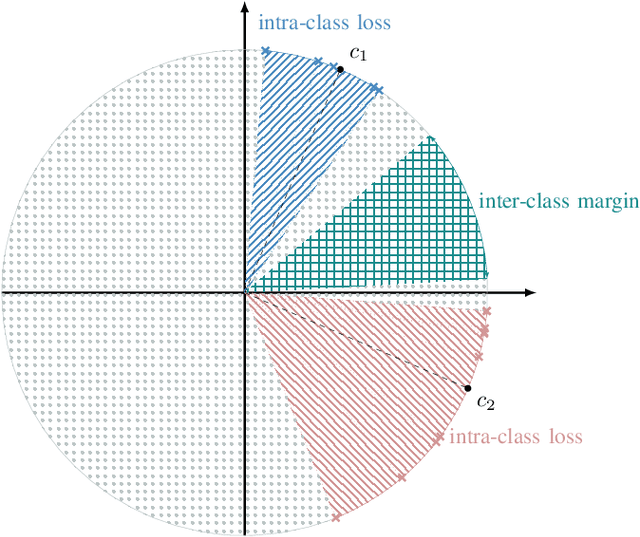
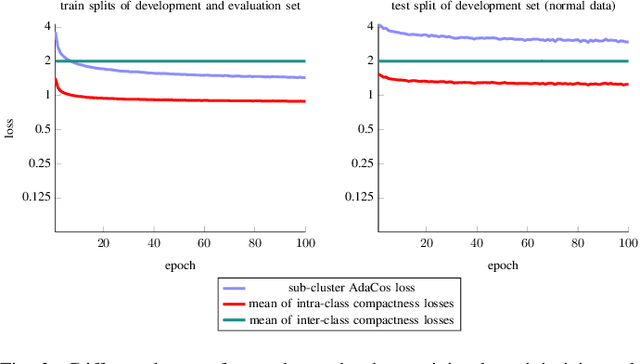
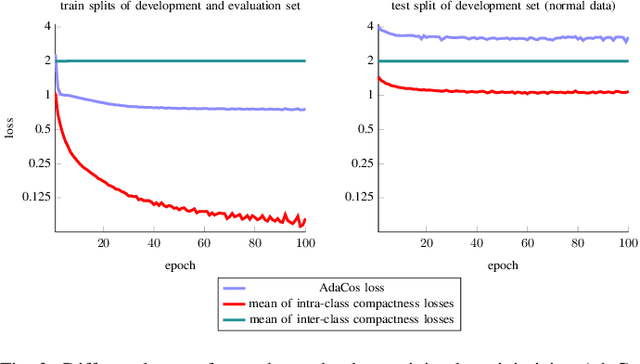
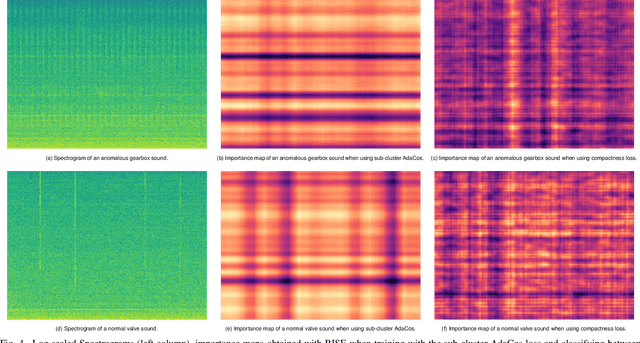
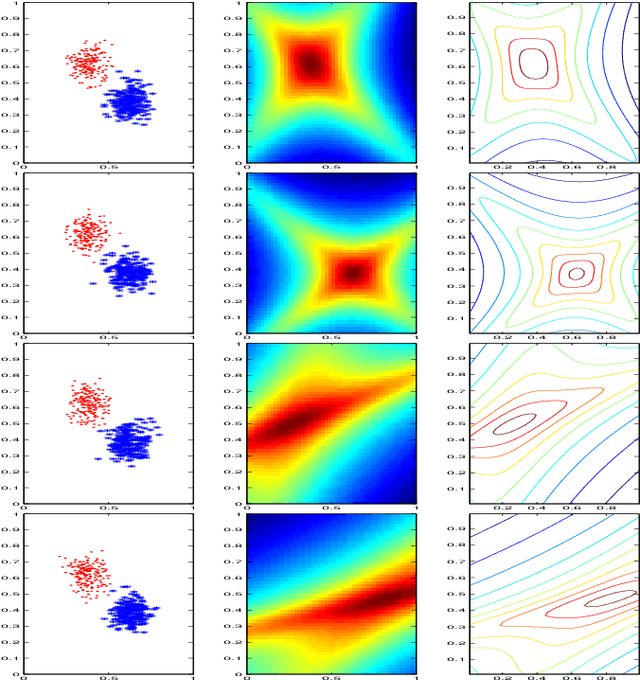
State-of-the-art anomalous sound detection systems often utilize angular margin losses to learn suitable representations of acoustic data using an auxiliary task, which usually is a supervised or self-supervised classification task. The underlying idea is that, in order to solve this auxiliary task, specific information about normal data needs to be captured in the learned representations and that this information is also sufficient to differentiate between normal and anomalous samples. Especially in noisy conditions, discriminative models based on angular margin losses tend to significantly outperform systems based on generative or one-class models. The goal of this work is to investigate why using angular margin losses with auxiliary tasks works well for detecting anomalous sounds. To this end, it is shown, both theoretically and experimentally, that minimizing angular margin losses also minimizes compactness loss while inherently preventing learning trivial solutions. Furthermore, multiple experiments are conducted to show that using a related classification task as an auxiliary task teaches the model to learn representations suitable for detecting anomalous sounds in noisy conditions. Among these experiments are performance evaluations, visualizing the embedding space with t-SNE and visualizing the input representations with respect to the anomaly score using randomized input sampling for explanation.