 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProjected Belief Networks With Discriminative Alignment for Acoustic Event Classification: Rivaling State of the Art CNNs
Jan 20, 2024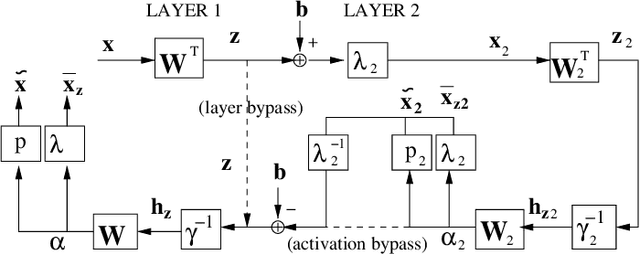
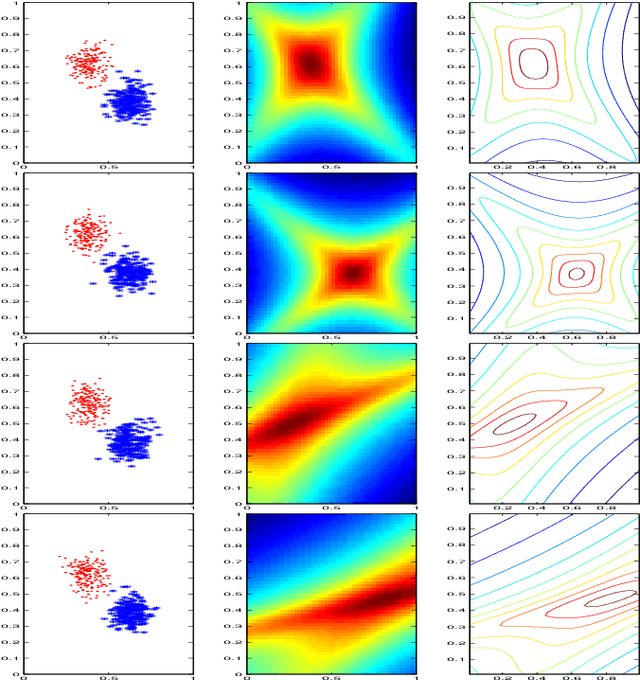
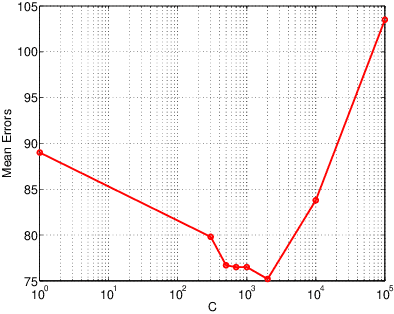
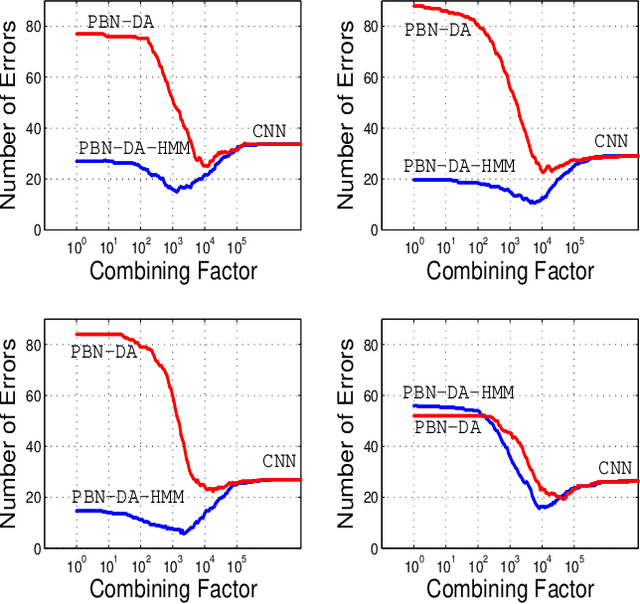
The projected belief network (PBN) is a generative stochastic network with tractable likelihood function based on a feed-forward neural network (FFNN). The generative function operates by "backing up" through the FFNN. The PBN is two networks in one, a FFNN that operates in the forward direction, and a generative network that operates in the backward direction. Both networks co-exist based on the same parameter set, have their own cost functions, and can be separately or jointly trained. The PBN therefore has the potential to possess the best qualities of both discriminative and generative classifiers. To realize this potential, a separate PBN is trained on each class, maximizing the generative likelihood function for the given class, while minimizing the discriminative cost for the FFNN against "all other classes". This technique, called discriminative alignment (PBN-DA), aligns the contours of the likelihood function to the decision boundaries and attains vastly improved classification performance, rivaling that of state of the art discriminative networks. The method may be further improved using a hidden Markov model (HMM) as a component of the PBN, called PBN-DA-HMM. This paper provides a comprehensive treatment of PBN, PBN-DA, and PBN-DA-HMM. In addition, the results of two new classification experiments are provided. The first experiment uses air-acoustic events, and the second uses underwater acoustic data consisting of marine mammal calls. In both experiments, PBN-DA-HMM attains comparable or better performance as a state of the art CNN, and attain a factor of two error reduction when combined with the CNN.
A Comparison of PDF Projection with Normalizing Flows and SurVAE
Nov 27, 2023Normalizing flows (NF) recently gained attention as a way to construct generative networks with exact likelihood calculation out of composable layers. However, NF is restricted to dimension-preserving transformations. Surjection VAE (SurVAE) has been proposed to extend NF to dimension-altering transformations. Such networks are desirable because they are expressive and can be precisely trained. We show that the approaches are a re-invention of PDF projection, which appeared over twenty years earlier and is much further developed.
Trainable Compound Activation Functions for Machine Learning
Apr 25, 2022



Activation functions (AF) are necessary components of neural networks that allow approximation of functions, but AFs in current use are usually simple monotonically increasing functions. In this paper, we propose trainable compound AF (TCA) composed of a sum of shifted and scaled simple AFs. TCAs increase the effectiveness of networks with fewer parameters compared to added layers. TCAs have a special interpretation in generative networks because they effectively estimate the marginal distributions of each dimension of the data using a mixture distribution, reducing modality and making linear dimension reduction more effective. When used in restricted Boltzmann machines (RBMs), they result in a novel type of RBM with mixture-based stochastic units. Improved performance is demonstrated in experiments using RBMs, deep belief networks (DBN), projected belief networks (PBN), and variational auto-encoders (VAE).
Kernel-based Generative Learning in Distortion Feature Space
Jun 21, 2016

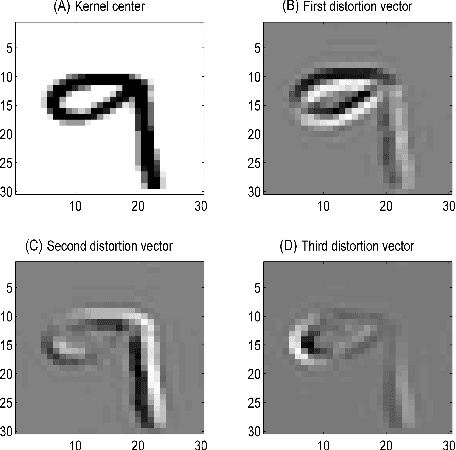
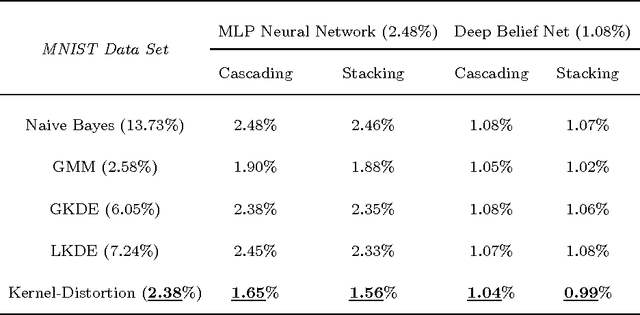
This paper presents a novel kernel-based generative classifier which is defined in a distortion subspace using polynomial series expansion, named Kernel-Distortion (KD) classifier. An iterative kernel selection algorithm is developed to steadily improve classification performance by repeatedly removing and adding kernels. The experimental results on character recognition application not only show that the proposed generative classifier performs better than many existing classifiers, but also illustrate that it has different recognition capability compared to the state-of-the-art discriminative classifier - deep belief network. The recognition diversity indicates that a hybrid combination of the proposed generative classifier and the discriminative classifier could further improve the classification performance. Two hybrid combination methods, cascading and stacking, have been implemented to verify the diversity and the improvement of the proposed classifier.
EEF: Exponentially Embedded Families with Class-Specific Features for Classification
May 27, 2016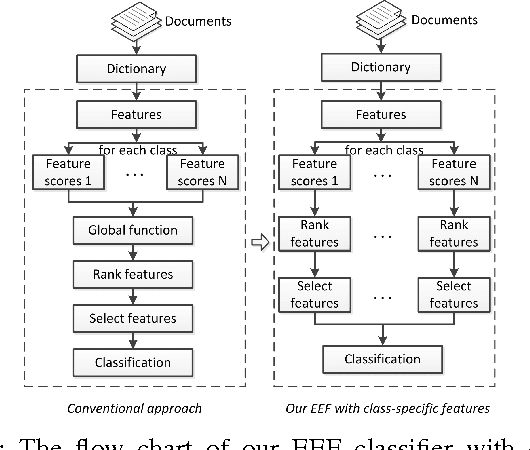
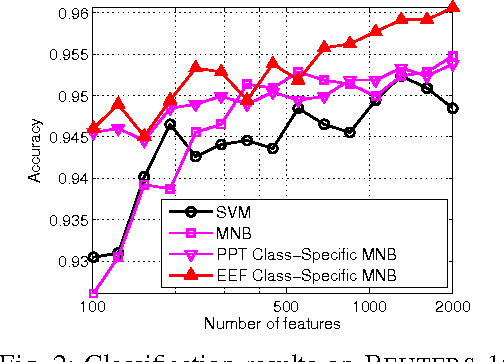
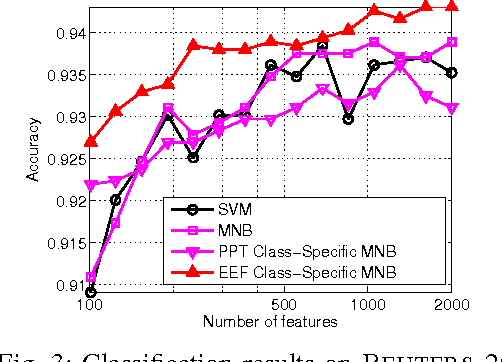
In this letter, we present a novel exponentially embedded families (EEF) based classification method, in which the probability density function (PDF) on raw data is estimated from the PDF on features. With the PDF construction, we show that class-specific features can be used in the proposed classification method, instead of a common feature subset for all classes as used in conventional approaches. We apply the proposed EEF classifier for text categorization as a case study and derive an optimal Bayesian classification rule with class-specific feature selection based on the Information Gain (IG) score. The promising performance on real-life data sets demonstrates the effectiveness of the proposed approach and indicates its wide potential applications.