 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreadboarding the European Moon Rover System: discussion and results of the analogue field test campaign
Nov 21, 2024



This document compiles results obtained from the test campaign of the European Moon Rover System (EMRS) project. The test campaign, conducted at the Planetary Exploration Lab of DLR in Wessling, aimed to understand the scope of the EMRS breadboard design, its strengths, and the benefits of the modular design. The discussion of test results is based on rover traversal analyses, robustness assessments, wheel deflection analyses, and the overall transportation cost of the rover. This not only enables the comparison of locomotion modes on lunar regolith but also facilitates critical decision-making in the design of future lunar missions.
* 6 pages, 5 figures, conference International Conference on Space Robotics
Modularity for lunar exploration: European Moon Rover System Pre-Phase A Design and Field Test Campaign Results
Nov 06, 2023The European Moon Rover System (EMRS) Pre-Phase A activity is part of the European Exploration Envelope Programme (E3P) that seeks to develop a versatile surface mobility solution for future lunar missions. These missions include: the Polar Explorer (PE), In-Situ Resource Utilization (ISRU), and Astrophysics Lunar Observatory (ALO) and Lunar Geological Exploration Mission (LGEM). Therefore, designing a multipurpose rover that can serve these missions is crucial. The rover needs to be compatible with three different mission scenarios, each with an independent payload, making flexibility the key driver. This study focuses on modularity in the rover's locomotion solution and autonomous on-board system. Moreover, the proposed EMRS solution has been tested at an analogue facility to prove the modular mobility concept. The tests involved the rover's mobility in a lunar soil simulant testbed and different locomotion modes in a rocky and uneven terrain, as well as robustness against obstacles and excavation of lunar regolith. As a result, the EMRS project has developed a multipurpose modular rover concept, with power, thermal control, insulation, and dust protection systems designed for further phases. This paper highlights the potential of the EMRS system for lunar exploration and the importance of modularity in rover design.
The European Moon Rover System: a modular multipurpose rover for future complex lunar missions
Nov 06, 2023This document presents the study conducted during the European Moon Rover System Pre-Phase A project, in which we have developed a lunar rover system, with a modular approach, capable of carrying out different missions with different objectives. This includes excavating and transporting over 200kg of regolith, building an astrophysical observatory on the far side of the Moon, placing scientific instrumentation at the lunar south pole, or studying the volcanic history of our satellite. To achieve this, a modular approach has been adopted for the design of the platform in terms of locomotion and mobility, which includes onboard autonomy, of course. A modular platform allows for accommodating different payloads and allocating them in the most advantageous positions for the mission they are going to undertake (for example, having direct access to the lunar surface for the payloads that require it), while also allowing for the relocation of payloads and reconfiguring the rover design itself to perform completely different tasks.
On Bayesian Exponentially Embedded Family for Model Order Selection
Mar 30, 2017In this paper, we derive a Bayesian model order selection rule by using the exponentially embedded family method, termed Bayesian EEF. Unlike many other Bayesian model selection methods, the Bayesian EEF can use vague proper priors and improper noninformative priors to be objective in the elicitation of parameter priors. Moreover, the penalty term of the rule is shown to be the sum of half of the parameter dimension and the estimated mutual information between parameter and observed data. This helps to reveal the EEF mechanism in selecting model orders and may provide new insights into the open problems of choosing an optimal penalty term for model order selection and choosing a good prior from information theoretic viewpoints. The important example of linear model order selection is given to illustrate the algorithms and arguments. Lastly, the Bayesian EEF that uses Jeffreys prior coincides with the EEF rule derived by frequentist strategies. This shows another interesting relationship between the frequentist and Bayesian philosophies for model selection.
EEF: Exponentially Embedded Families with Class-Specific Features for Classification
May 27, 2016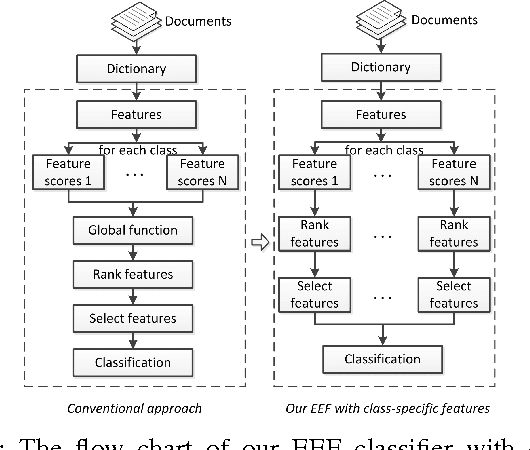
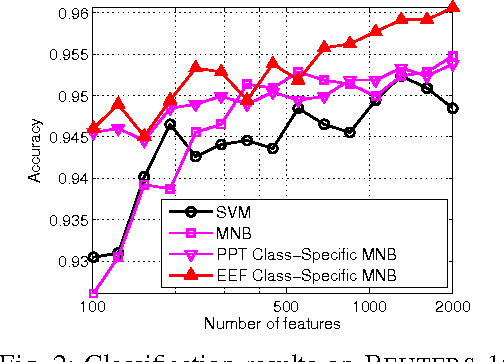
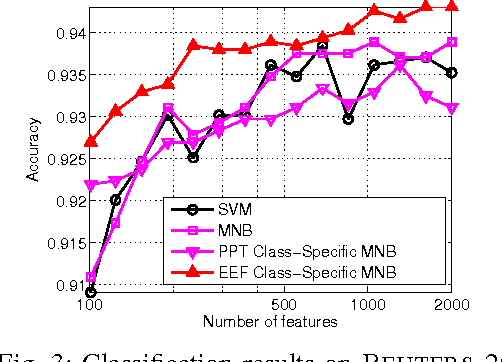
In this letter, we present a novel exponentially embedded families (EEF) based classification method, in which the probability density function (PDF) on raw data is estimated from the PDF on features. With the PDF construction, we show that class-specific features can be used in the proposed classification method, instead of a common feature subset for all classes as used in conventional approaches. We apply the proposed EEF classifier for text categorization as a case study and derive an optimal Bayesian classification rule with class-specific feature selection based on the Information Gain (IG) score. The promising performance on real-life data sets demonstrates the effectiveness of the proposed approach and indicates its wide potential applications.
Toward Optimal Feature Selection in Naive Bayes for Text Categorization
Feb 09, 2016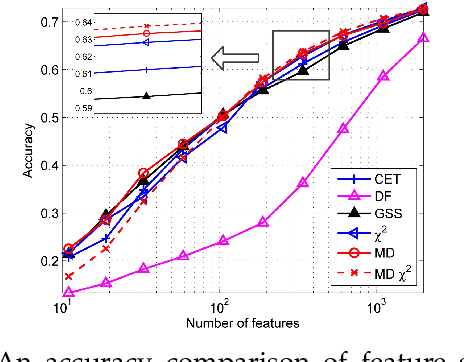
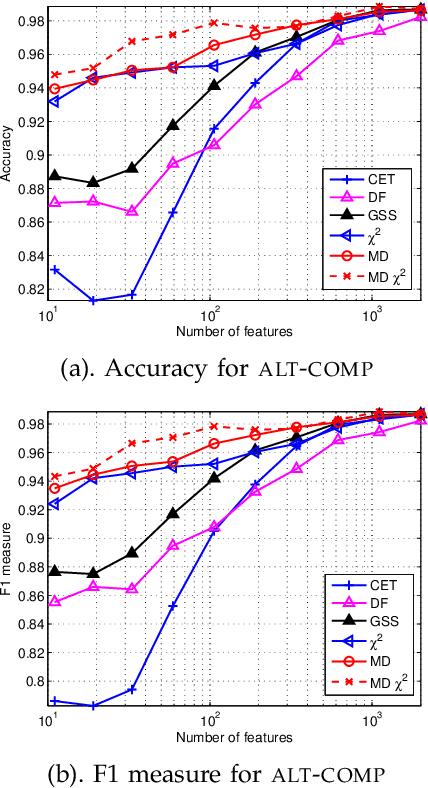
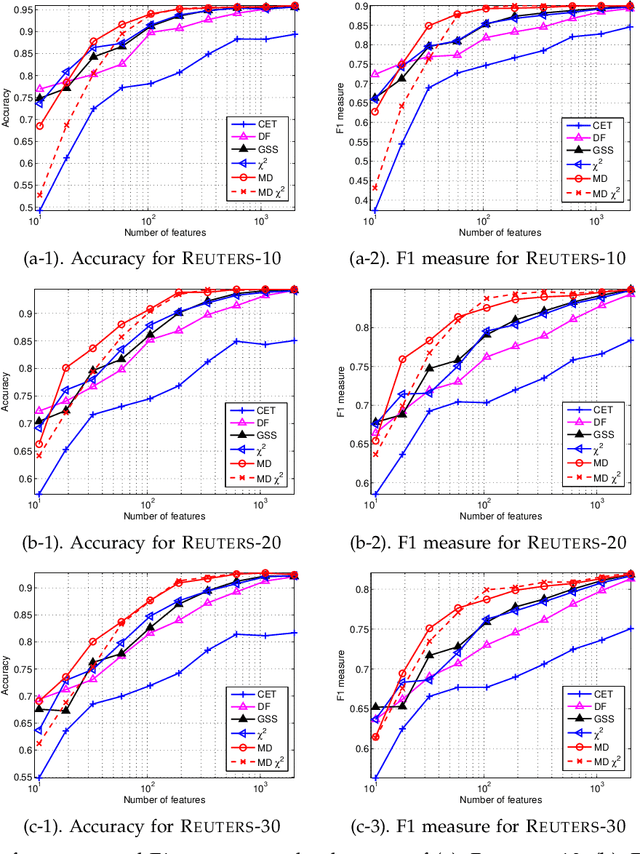
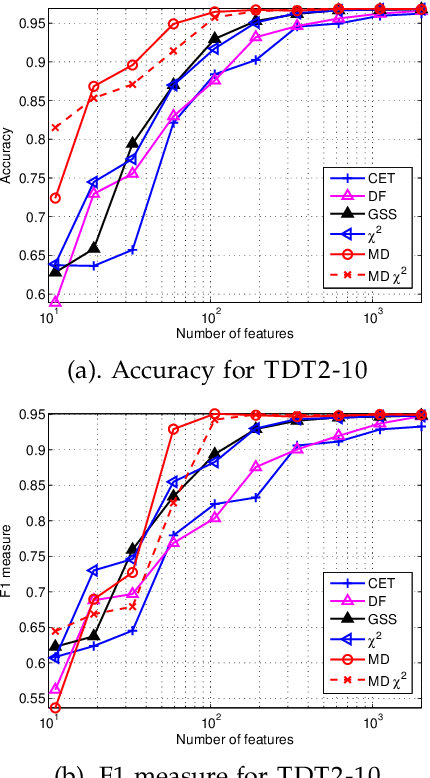
Automated feature selection is important for text categorization to reduce the feature size and to speed up the learning process of classifiers. In this paper, we present a novel and efficient feature selection framework based on the Information Theory, which aims to rank the features with their discriminative capacity for classification. We first revisit two information measures: Kullback-Leibler divergence and Jeffreys divergence for binary hypothesis testing, and analyze their asymptotic properties relating to type I and type II errors of a Bayesian classifier. We then introduce a new divergence measure, called Jeffreys-Multi-Hypothesis (JMH) divergence, to measure multi-distribution divergence for multi-class classification. Based on the JMH-divergence, we develop two efficient feature selection methods, termed maximum discrimination ($MD$) and $MD-\chi^2$ methods, for text categorization. The promising results of extensive experiments demonstrate the effectiveness of the proposed approaches.