 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analytical Update Rule for General Policy Optimization
Dec 03, 2021
We present an analytical policy update rule that is independent of parameterized function approximators. The update rule is suitable for general stochastic policies with monotonic improvement guarantee. The update rule is derived from a closed-form trust-region solution using calculus of variation, following a new theoretical result that tightens existing bounds for policy search using trust-region methods. An explanation building a connection between the policy update rule and value-function methods is provided. Based on a recursive form of the update rule, an off-policy algorithm is derived naturally, and the monotonic improvement guarantee remains. Furthermore, the update rule extends immediately to multi-agent systems when updates are performed by one agent at a time.
Multi-Agent Trust Region Policy Optimization
Oct 18, 2020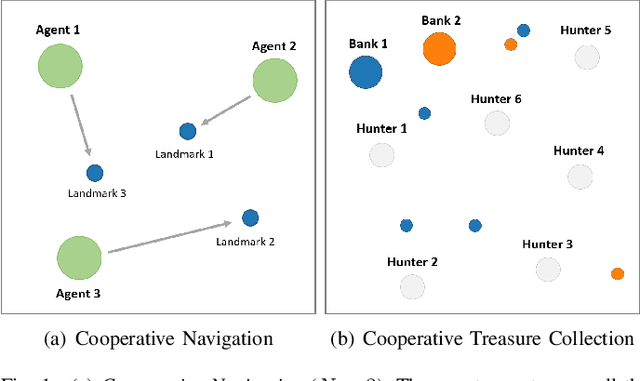
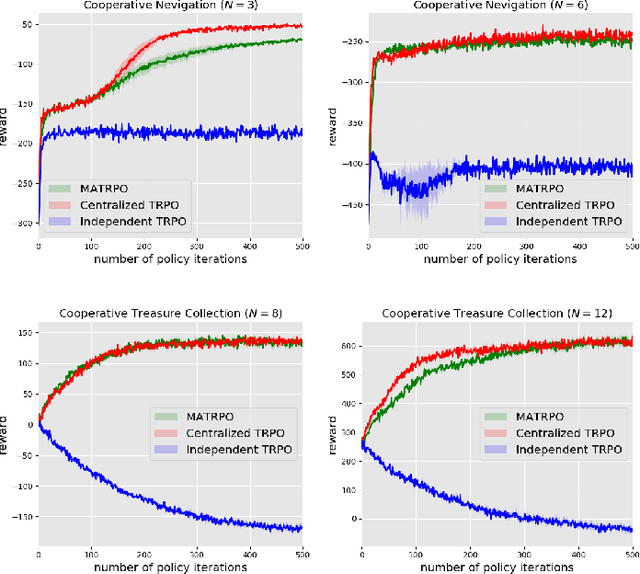

We extend trust region policy optimization (TRPO) to multi-agent reinforcement learning (MARL) problems. We show that the policy update of TRPO can be transformed into a distributed consensus optimization problem for multi-agent cases. By making a series of approximations to the consensus optimization model, we propose a decentralized MARL algorithm, which we call multi-agent TRPO (MATRPO). This algorithm can optimize distributed policies based on local observations and private rewards. The agents do not need to know observations, rewards, policies or value/action-value functions of other agents. The agents only share a likelihood ratio with their neighbors during the training process. The algorithm is fully decentralized and privacy-preserving. Our experiments on two cooperative games demonstrate its robust performance on complicated MARL tasks.
Nucleus Neural Network: A Data-driven Self-organized Architecture
May 14, 2019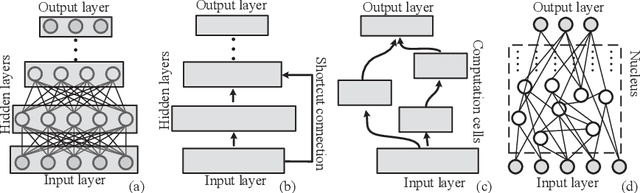
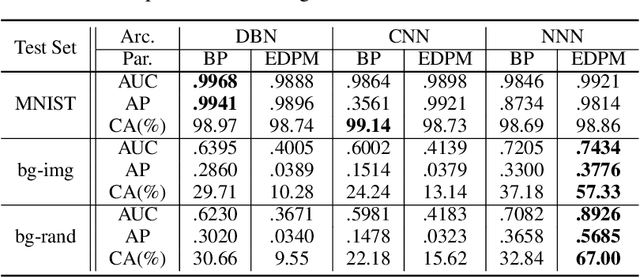
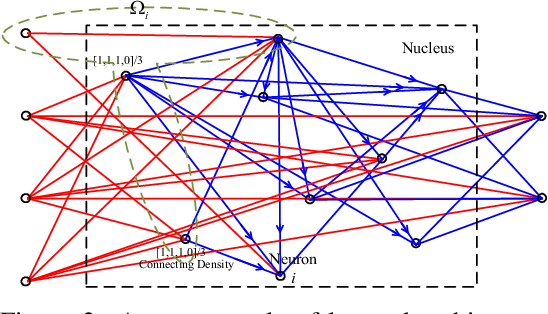
Artificial neural networks which are inspired from the learning mechanism of brain have achieved great successes in many problems, especially those with deep layers. In this paper, we propose a nucleus neural network (NNN) and corresponding connecting architecture learning method. In a nucleus, there are no regular layers, i.e., a neuron may connect to all the neurons in the nucleus. This type of architecture gets rid of layer limitation and may lead to more powerful learning capability. It is crucial to determine the connections between them given numerous neurons. Based on the principle that more relevant input and output neuron pair deserves higher connecting density, we propose an efficient architecture learning model for the nucleus. Moreover, we improve the learning method for connecting weights and biases given the optimized architecture. We find that this novel architecture is robust to irrelevant components in test data. So we reconstruct a new dataset based on the MNIST dataset where the types of digital backgrounds in training and test sets are different. Experiments demonstrate that the proposed learner achieves significant improvement over traditional learners on the reconstructed data set.
Dimensionality Reduction of Hyperspectral Imagery Based on Spatial-spectral Manifold Learning
Dec 22, 2018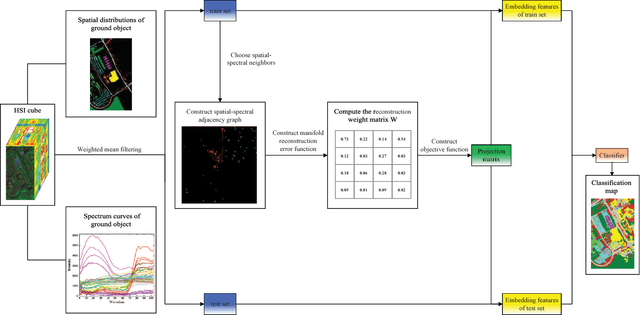
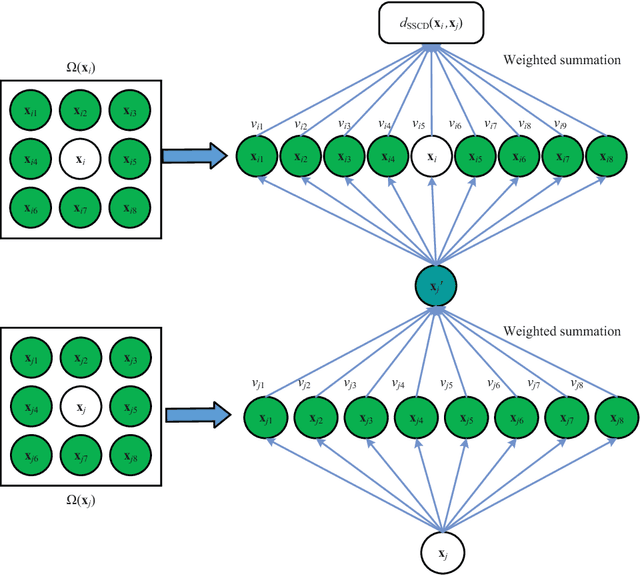


The graph embedding (GE) methods have been widely applied for dimensionality reduction of hyperspectral imagery (HSI). However, a major challenge of GE is how to choose proper neighbors for graph construction and explore the spatial information of HSI data. In this paper, we proposed an unsupervised dimensionality reduction algorithm termed spatial-spectral manifold reconstruction preserving embedding (SSMRPE) for HSI classification. At first, a weighted mean filter (WMF) is employed to preprocess the image, which aims to reduce the influence of background noise. According to the spatial consistency property of HSI, the SSMRPE method utilizes a new spatial-spectral combined distance (SSCD) to fuse the spatial structure and spectral information for selecting effective spatial-spectral neighbors of HSI pixels. Then, it explores the spatial relationship between each point and its neighbors to adjusts the reconstruction weights for improving the efficiency of manifold reconstruction. As a result, the proposed method can extract the discriminant features and subsequently improve the classification performance of HSI. The experimental results on PaviaU and Salinas hyperspectral datasets indicate that SSMRPE can achieve better classification accuracies in comparison with some state-of-the-art methods.
Distributive Dynamic Spectrum Access through Deep Reinforcement Learning: A Reservoir Computing Based Approach
Oct 28, 2018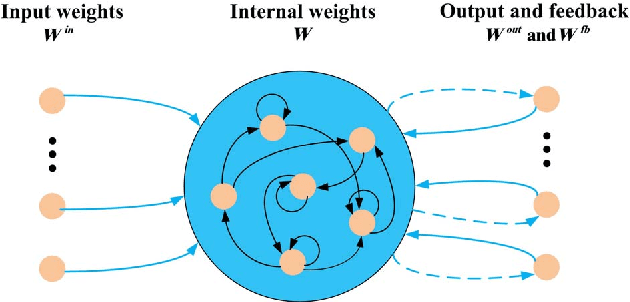
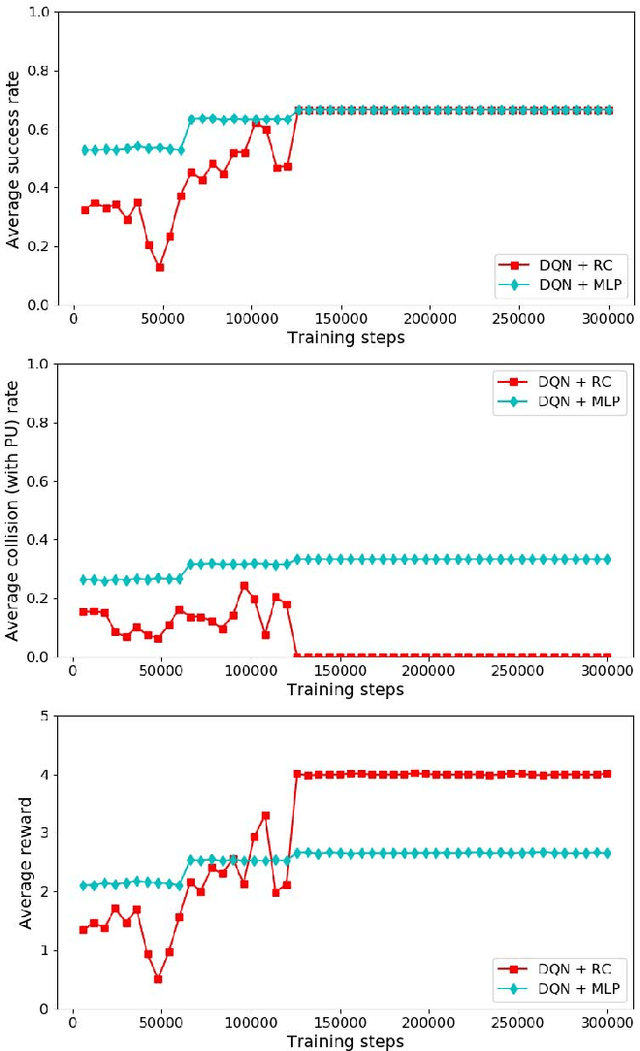

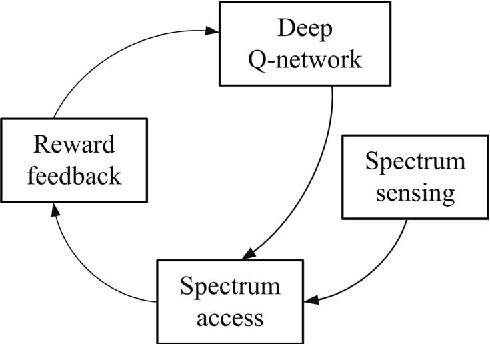
Dynamic spectrum access (DSA) is regarded as an effective and efficient technology to share radio spectrum among different networks. As a secondary user (SU), a DSA device will face two critical problems: avoiding causing harmful interference to primary users (PUs), and conducting effective interference coordination with other secondary users. These two problems become even more challenging for a distributed DSA network where there is no centralized controllers for SUs. In this paper, we investigate communication strategies of a distributive DSA network under the presence of spectrum sensing errors. To be specific, we apply the powerful machine learning tool, deep reinforcement learning (DRL), for SUs to learn "appropriate" spectrum access strategies in a distributed fashion assuming NO knowledge of the underlying system statistics. Furthermore, a special type of recurrent neural network (RNN), called the reservoir computing (RC), is utilized to realize DRL by taking advantage of the underlying temporal correlation of the DSA network. Using the introduced machine learning-based strategy, SUs could make spectrum access decisions distributedly relying only on their own current and past spectrum sensing outcomes. Through extensive experiments, our results suggest that the RC-based spectrum access strategy can help the SU to significantly reduce the chances of collision with PUs and other SUs. We also show that our scheme outperforms the myopic method which assumes the knowledge of system statistics, and converges faster than the Q-learning method when the number of channels is large.
A Local Density-Based Approach for Local Outlier Detection
Jun 28, 2016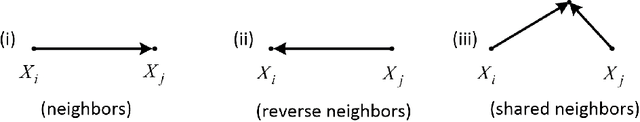

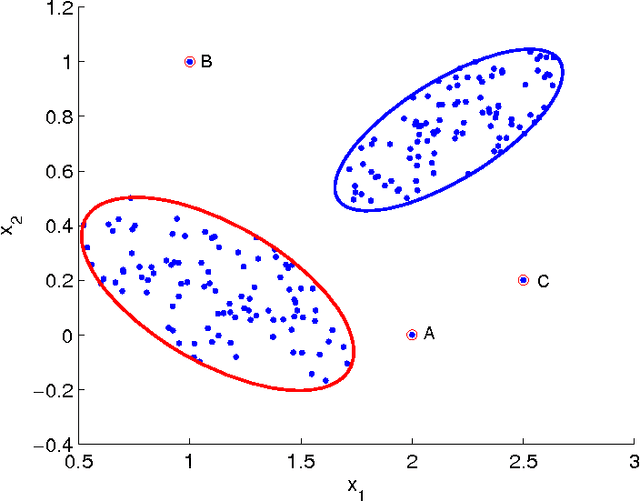

This paper presents a simple but effective density-based outlier detection approach with the local kernel density estimation (KDE). A Relative Density-based Outlier Score (RDOS) is introduced to measure the local outlierness of objects, in which the density distribution at the location of an object is estimated with a local KDE method based on extended nearest neighbors of the object. Instead of using only $k$ nearest neighbors, we further consider reverse nearest neighbors and shared nearest neighbors of an object for density distribution estimation. Some theoretical properties of the proposed RDOS including its expected value and false alarm probability are derived. A comprehensive experimental study on both synthetic and real-life data sets demonstrates that our approach is more effective than state-of-the-art outlier detection methods.
Kernel-based Generative Learning in Distortion Feature Space
Jun 21, 2016

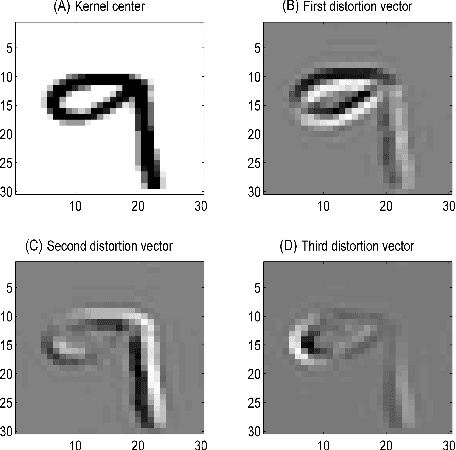
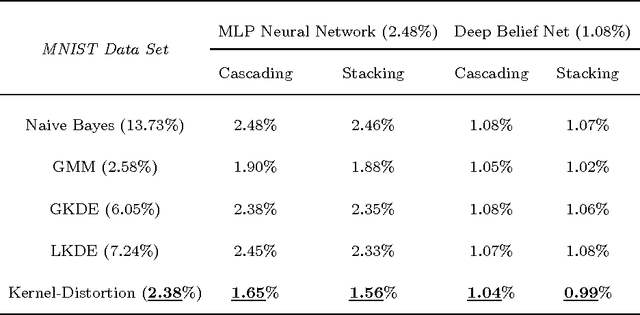
This paper presents a novel kernel-based generative classifier which is defined in a distortion subspace using polynomial series expansion, named Kernel-Distortion (KD) classifier. An iterative kernel selection algorithm is developed to steadily improve classification performance by repeatedly removing and adding kernels. The experimental results on character recognition application not only show that the proposed generative classifier performs better than many existing classifiers, but also illustrate that it has different recognition capability compared to the state-of-the-art discriminative classifier - deep belief network. The recognition diversity indicates that a hybrid combination of the proposed generative classifier and the discriminative classifier could further improve the classification performance. Two hybrid combination methods, cascading and stacking, have been implemented to verify the diversity and the improvement of the proposed classifier.
FSMJ: Feature Selection with Maximum Jensen-Shannon Divergence for Text Categorization
Jun 20, 2016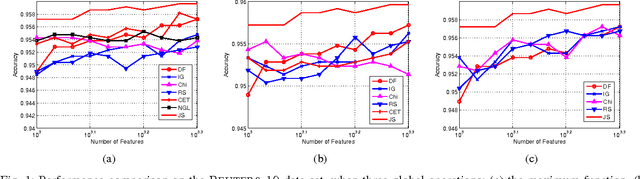
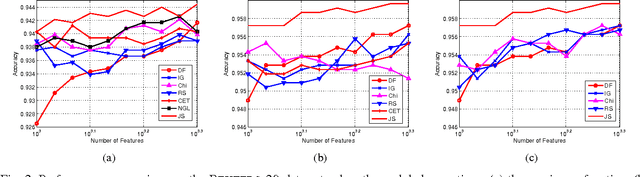
In this paper, we present a new wrapper feature selection approach based on Jensen-Shannon (JS) divergence, termed feature selection with maximum JS-divergence (FSMJ), for text categorization. Unlike most existing feature selection approaches, the proposed FSMJ approach is based on real-valued features which provide more information for discrimination than binary-valued features used in conventional approaches. We show that the FSMJ is a greedy approach and the JS-divergence monotonically increases when more features are selected. We conduct several experiments on real-life data sets, compared with the state-of-the-art feature selection approaches for text categorization. The superior performance of the proposed FSMJ approach demonstrates its effectiveness and further indicates its wide potential applications on data mining.
EEF: Exponentially Embedded Families with Class-Specific Features for Classification
May 27, 2016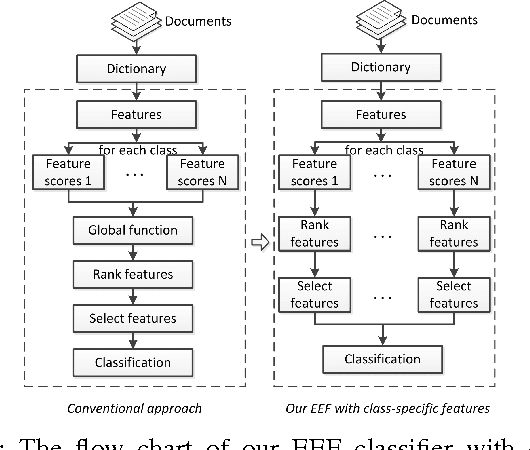
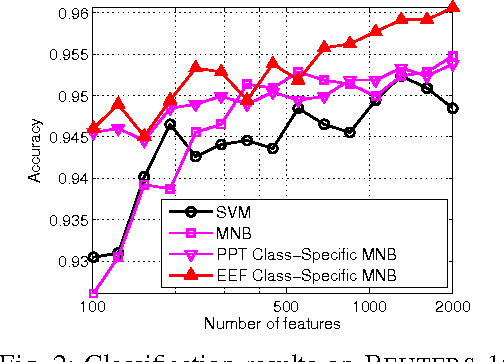
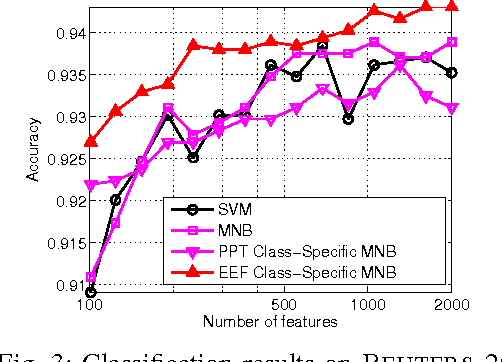
In this letter, we present a novel exponentially embedded families (EEF) based classification method, in which the probability density function (PDF) on raw data is estimated from the PDF on features. With the PDF construction, we show that class-specific features can be used in the proposed classification method, instead of a common feature subset for all classes as used in conventional approaches. We apply the proposed EEF classifier for text categorization as a case study and derive an optimal Bayesian classification rule with class-specific feature selection based on the Information Gain (IG) score. The promising performance on real-life data sets demonstrates the effectiveness of the proposed approach and indicates its wide potential applications.
Toward Optimal Feature Selection in Naive Bayes for Text Categorization
Feb 09, 2016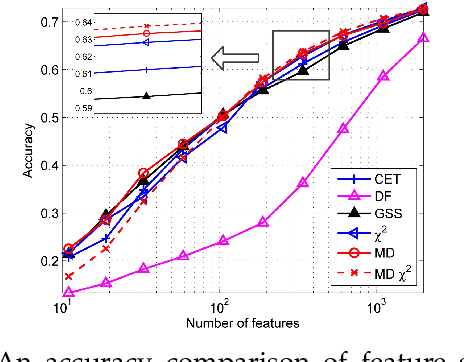
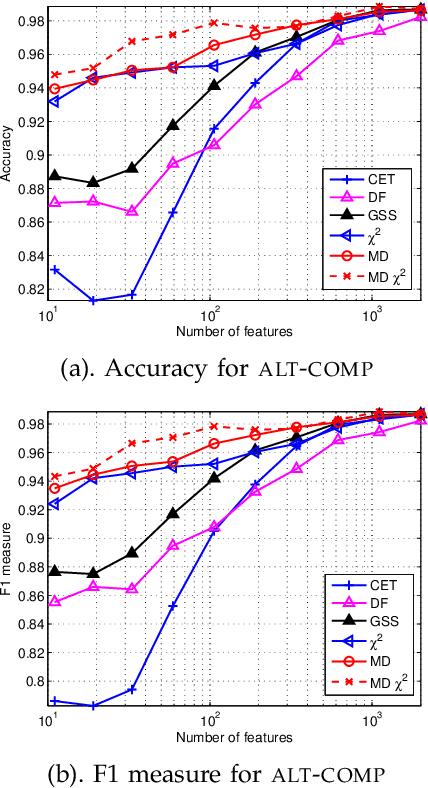
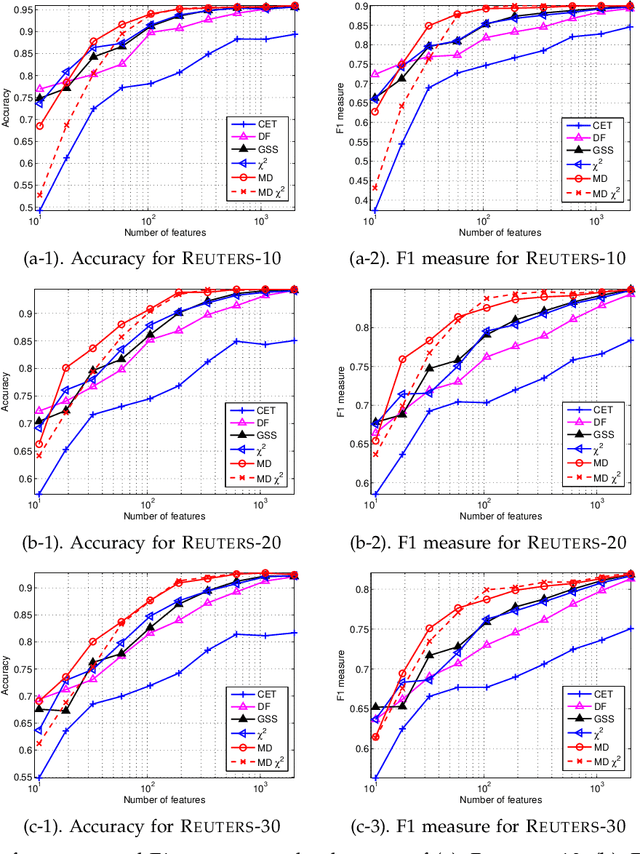
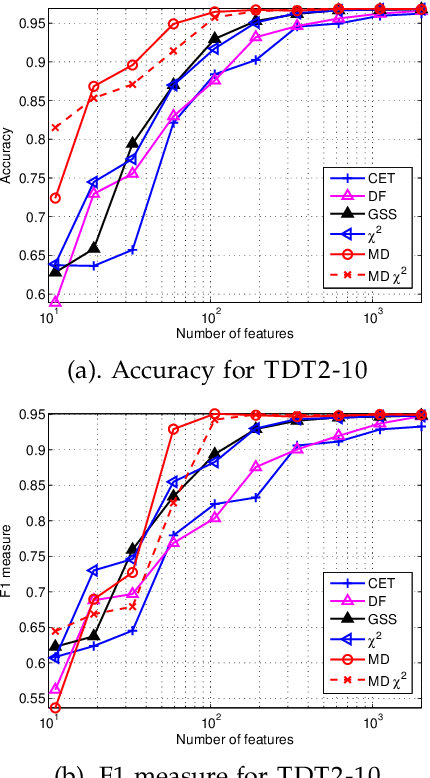
Automated feature selection is important for text categorization to reduce the feature size and to speed up the learning process of classifiers. In this paper, we present a novel and efficient feature selection framework based on the Information Theory, which aims to rank the features with their discriminative capacity for classification. We first revisit two information measures: Kullback-Leibler divergence and Jeffreys divergence for binary hypothesis testing, and analyze their asymptotic properties relating to type I and type II errors of a Bayesian classifier. We then introduce a new divergence measure, called Jeffreys-Multi-Hypothesis (JMH) divergence, to measure multi-distribution divergence for multi-class classification. Based on the JMH-divergence, we develop two efficient feature selection methods, termed maximum discrimination ($MD$) and $MD-\chi^2$ methods, for text categorization. The promising results of extensive experiments demonstrate the effectiveness of the proposed approaches.