 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFSMJ: Feature Selection with Maximum Jensen-Shannon Divergence for Text Categorization
Paper and Code
Jun 20, 2016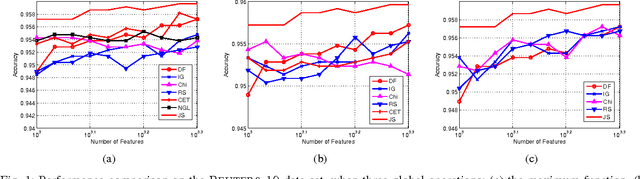
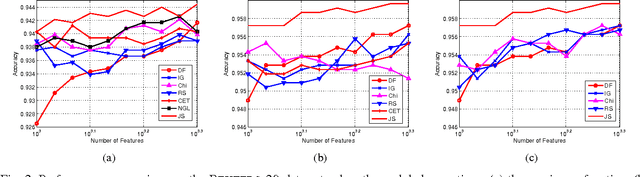
In this paper, we present a new wrapper feature selection approach based on Jensen-Shannon (JS) divergence, termed feature selection with maximum JS-divergence (FSMJ), for text categorization. Unlike most existing feature selection approaches, the proposed FSMJ approach is based on real-valued features which provide more information for discrimination than binary-valued features used in conventional approaches. We show that the FSMJ is a greedy approach and the JS-divergence monotonically increases when more features are selected. We conduct several experiments on real-life data sets, compared with the state-of-the-art feature selection approaches for text categorization. The superior performance of the proposed FSMJ approach demonstrates its effectiveness and further indicates its wide potential applications on data mining.