 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Emergent Machina Sapiens Urge Rethinking Multi-Agent Paradigms
Feb 05, 2025Artificially intelligent (AI) agents that are capable of autonomous learning and independent decision-making hold great promise for addressing complex challenges across domains like transportation, energy systems, and manufacturing. However, the surge in AI systems' design and deployment driven by various stakeholders with distinct and unaligned objectives introduces a crucial challenge: how can uncoordinated AI systems coexist and evolve harmoniously in shared environments without creating chaos? To address this, we advocate for a fundamental rethinking of existing multi-agent frameworks, such as multi-agent systems and game theory, which are largely limited to predefined rules and static objective structures. We posit that AI agents should be empowered to dynamically adjust their objectives, make compromises, form coalitions, and safely compete or cooperate through evolving relationships and social feedback. Through this paper, we call for a shift toward the emergent, self-organizing, and context-aware nature of these systems.
Knowledge Transfer from Simple to Complex: A Safe and Efficient Reinforcement Learning Framework for Autonomous Driving Decision-Making
Oct 21, 2024



A safe and efficient decision-making system is crucial for autonomous vehicles. However, the complexity and variability of driving environments limit the effectiveness of many rule-based and machine learning-based decision-making approaches. Reinforcement Learning in autonomous driving offers a promising solution to these challenges. Nevertheless, concerns regarding safety and efficiency during training remain major obstacles to its widespread application. To address these concerns, we propose a novel RL framework named Simple to Complex Collaborative Decision. First, we rapidly train the teacher model using the Proximal Policy Optimization algorithm in a lightweight simulation environment. In the more intricate simulation environment, the teacher model intervenes when the student agent exhibits suboptimal behavior by assessing the value of actions to avert dangerous situations. We also introduce an innovative RL algorithm called Adaptive Clipping PPO, which is trained using a combination of samples generated by both teacher and student policies, and employs dynamic clipping strategies based on sample importance. Additionally, we employ the KL divergence as a constraint on policy optimization, transforming it into an unconstrained problem to accelerate the student's learning of the teacher's policy. Finally, a gradual weaning strategy is employed to ensure that, over time, the student agent learns to explore independently. Simulation experiments in highway lane-change scenarios demonstrate that the S2CD framework enhances learning efficiency, reduces training costs, and significantly improves safety during training when compared with state-of-the-art baseline algorithms. This approach also ensures effective knowledge transfer between teacher and student models, and even when the teacher model is suboptimal.
An Analytical Update Rule for General Policy Optimization
Dec 03, 2021
We present an analytical policy update rule that is independent of parameterized function approximators. The update rule is suitable for general stochastic policies with monotonic improvement guarantee. The update rule is derived from a closed-form trust-region solution using calculus of variation, following a new theoretical result that tightens existing bounds for policy search using trust-region methods. An explanation building a connection between the policy update rule and value-function methods is provided. Based on a recursive form of the update rule, an off-policy algorithm is derived naturally, and the monotonic improvement guarantee remains. Furthermore, the update rule extends immediately to multi-agent systems when updates are performed by one agent at a time.
Multi-Agent Trust Region Policy Optimization
Oct 18, 2020
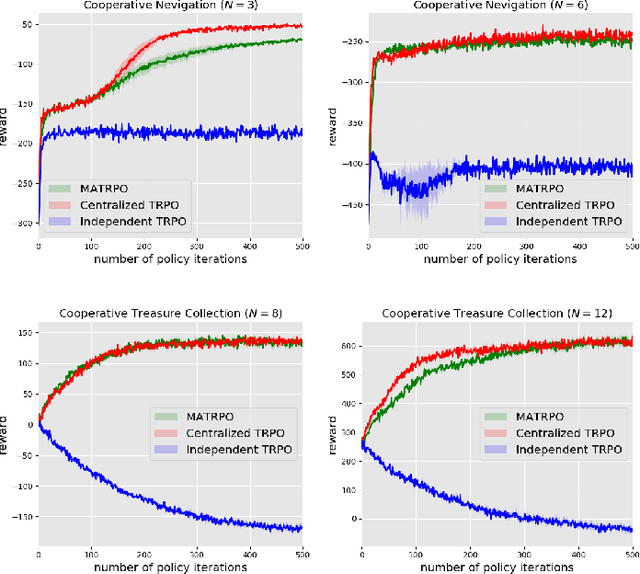

We extend trust region policy optimization (TRPO) to multi-agent reinforcement learning (MARL) problems. We show that the policy update of TRPO can be transformed into a distributed consensus optimization problem for multi-agent cases. By making a series of approximations to the consensus optimization model, we propose a decentralized MARL algorithm, which we call multi-agent TRPO (MATRPO). This algorithm can optimize distributed policies based on local observations and private rewards. The agents do not need to know observations, rewards, policies or value/action-value functions of other agents. The agents only share a likelihood ratio with their neighbors during the training process. The algorithm is fully decentralized and privacy-preserving. Our experiments on two cooperative games demonstrate its robust performance on complicated MARL tasks.