 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Transfer from Simple to Complex: A Safe and Efficient Reinforcement Learning Framework for Autonomous Driving Decision-Making
Oct 21, 2024



A safe and efficient decision-making system is crucial for autonomous vehicles. However, the complexity and variability of driving environments limit the effectiveness of many rule-based and machine learning-based decision-making approaches. Reinforcement Learning in autonomous driving offers a promising solution to these challenges. Nevertheless, concerns regarding safety and efficiency during training remain major obstacles to its widespread application. To address these concerns, we propose a novel RL framework named Simple to Complex Collaborative Decision. First, we rapidly train the teacher model using the Proximal Policy Optimization algorithm in a lightweight simulation environment. In the more intricate simulation environment, the teacher model intervenes when the student agent exhibits suboptimal behavior by assessing the value of actions to avert dangerous situations. We also introduce an innovative RL algorithm called Adaptive Clipping PPO, which is trained using a combination of samples generated by both teacher and student policies, and employs dynamic clipping strategies based on sample importance. Additionally, we employ the KL divergence as a constraint on policy optimization, transforming it into an unconstrained problem to accelerate the student's learning of the teacher's policy. Finally, a gradual weaning strategy is employed to ensure that, over time, the student agent learns to explore independently. Simulation experiments in highway lane-change scenarios demonstrate that the S2CD framework enhances learning efficiency, reduces training costs, and significantly improves safety during training when compared with state-of-the-art baseline algorithms. This approach also ensures effective knowledge transfer between teacher and student models, and even when the teacher model is suboptimal.
A Delay Compensation Framework Based on Eye-Movement for Teleoperated Ground Vehicles
Sep 14, 2023



An eye-movement-based predicted trajectory guidance control (ePTGC) is proposed to mitigate the maneuverability degradation of a teleoperated ground vehicle caused by communication delays. Human sensitivity to delays is the main reason for the performance degradation of a ground vehicle teleoperation system. The proposed framework extracts human intention from eye-movement. Then, it combines it with contextual constraints to generate an intention-compliant guidance trajectory, which is then employed to control the vehicle directly. The advantage of this approach is that the teleoperator is removed from the direct control loop by using the generated trajectories to guide vehicle, thus reducing the adverse sensitivity to delay. The delay can be compensated as long as the prediction horizon exceeds the delay. A human-in-loop simulation platform is designed to evaluate the teleoperation performance of the proposed method at different delay levels. The results are analyzed by repeated measures ANOVA, which shows that the proposed method significantly improves maneuverability and cognitive burden at large delay levels (>200 ms). The overall performance is also much better than the PTGC which does not employ the eye-movement feature.
S4OD: Semi-Supervised learning for Single-Stage Object Detection
Apr 09, 2022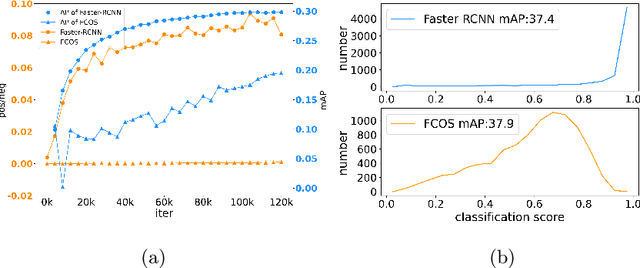
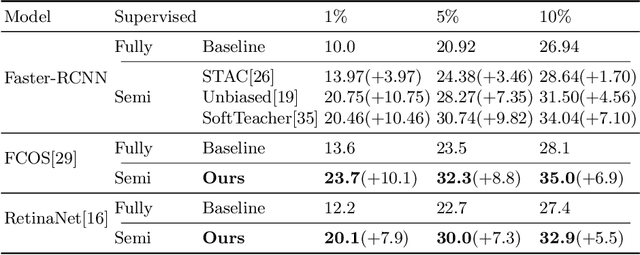
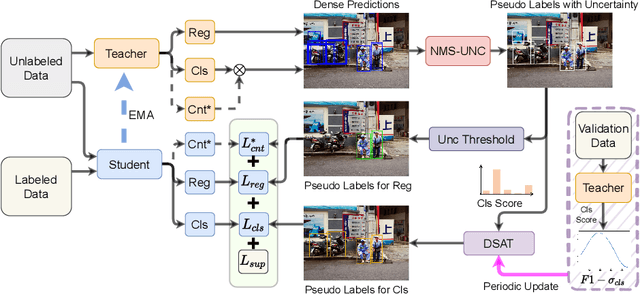

Single-stage detectors suffer from extreme foreground-background class imbalance, while two-stage detectors do not. Therefore, in semi-supervised object detection, two-stage detectors can deliver remarkable performance by only selecting high-quality pseudo labels based on classification scores. However, directly applying this strategy to single-stage detectors would aggravate the class imbalance with fewer positive samples. Thus, single-stage detectors have to consider both quality and quantity of pseudo labels simultaneously. In this paper, we design a dynamic self-adaptive threshold (DSAT) strategy in classification branch, which can automatically select pseudo labels to achieve an optimal trade-off between quality and quantity. Besides, to assess the regression quality of pseudo labels in single-stage detectors, we propose a module to compute the regression uncertainty of boxes based on Non-Maximum Suppression. By leveraging only 10% labeled data from COCO, our method achieves 35.0% AP on anchor-free detector (FCOS) and 32.9% on anchor-based detector (RetinaNet).
2nd Place Solution for VisDA 2021 Challenge -- Universally Domain Adaptive Image Recognition
Oct 27, 2021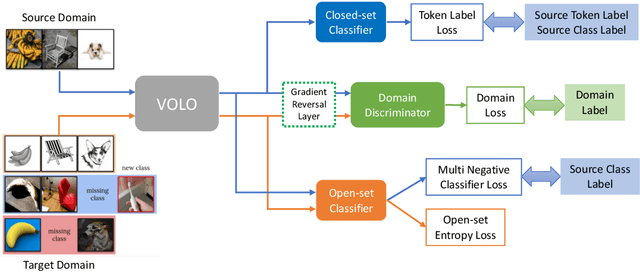
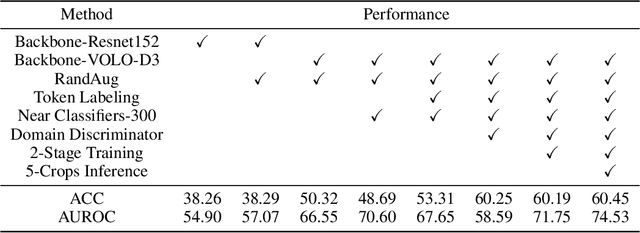
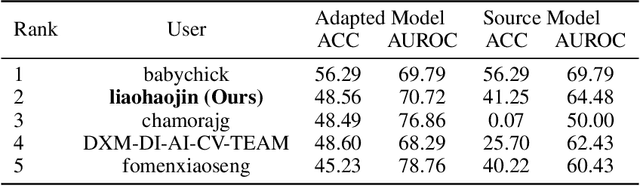
The Visual Domain Adaptation (VisDA) 2021 Challenge calls for unsupervised domain adaptation (UDA) methods that can deal with both input distribution shift and label set variance between the source and target domains. In this report, we introduce a universal domain adaptation (UniDA) method by aggregating several popular feature extraction and domain adaptation schemes. First, we utilize VOLO, a Transformer-based architecture with state-of-the-art performance in several visual tasks, as the backbone to extract effective feature representations. Second, we modify the open-set classifier of OVANet to recognize the unknown class with competitive accuracy and robustness. As shown in the leaderboard, our proposed UniDA method ranks the 2nd place with 48.56% ACC and 70.72% AUROC in the VisDA 2021 Challenge.
2nd Place Solution for Waymo Open Dataset Challenge -- Real-time 2D Object Detection
Jun 16, 2021
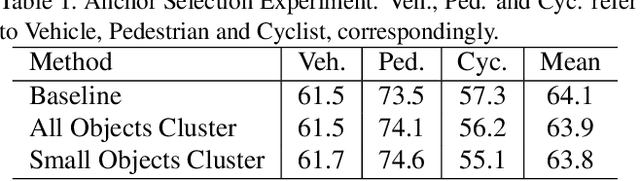
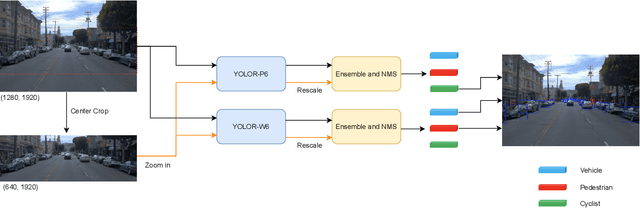
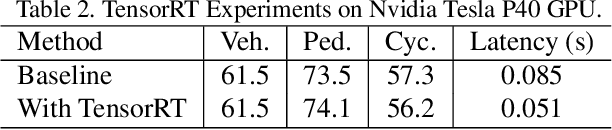
In an autonomous driving system, it is essential to recognize vehicles, pedestrians and cyclists from images. Besides the high accuracy of the prediction, the requirement of real-time running brings new challenges for convolutional network models. In this report, we introduce a real-time method to detect the 2D objects from images. We aggregate several popular one-stage object detectors and train the models of variety input strategies independently, to yield better performance for accurate multi-scale detection of each category, especially for small objects. For model acceleration, we leverage TensorRT to optimize the inference time of our detection pipeline. As shown in the leaderboard, our proposed detection framework ranks the 2nd place with 75.00% L1 mAP and 69.72% L2 mAP in the real-time 2D detection track of the Waymo Open Dataset Challenges, while our framework achieves the latency of 45.8ms/frame on an Nvidia Tesla V100 GPU.
STC-Flow: Spatio-temporal Context-aware Optical Flow Estimation
Mar 01, 2020

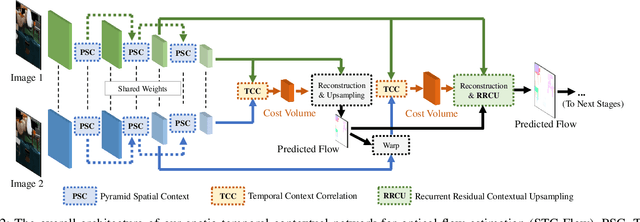
In this paper, we propose a spatio-temporal contextual network, STC-Flow, for optical flow estimation. Unlike previous optical flow estimation approaches with local pyramid feature extraction and multi-level correlation, we propose a contextual relation exploration architecture by capturing rich long-range dependencies in spatial and temporal dimensions. Specifically, STC-Flow contains three key context modules - pyramidal spatial context module, temporal context correlation module and recurrent residual contextual upsampling module, to build the relationship in each stage of feature extraction, correlation, and flow reconstruction, respectively. Experimental results indicate that the proposed scheme achieves the state-of-the-art performance of two-frame based methods on the Sintel dataset and the KITTI 2012/2015 datasets.
FPCR-Net: Feature Pyramidal Correlation and Residual Reconstruction for Semi-supervised Optical Flow Estimation
Jan 17, 2020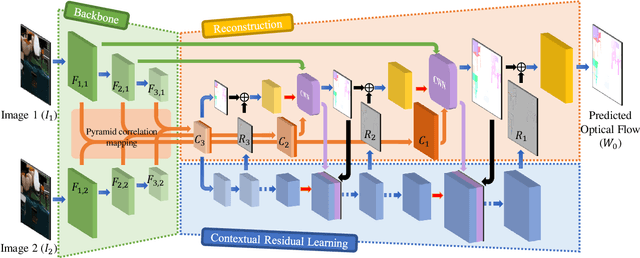
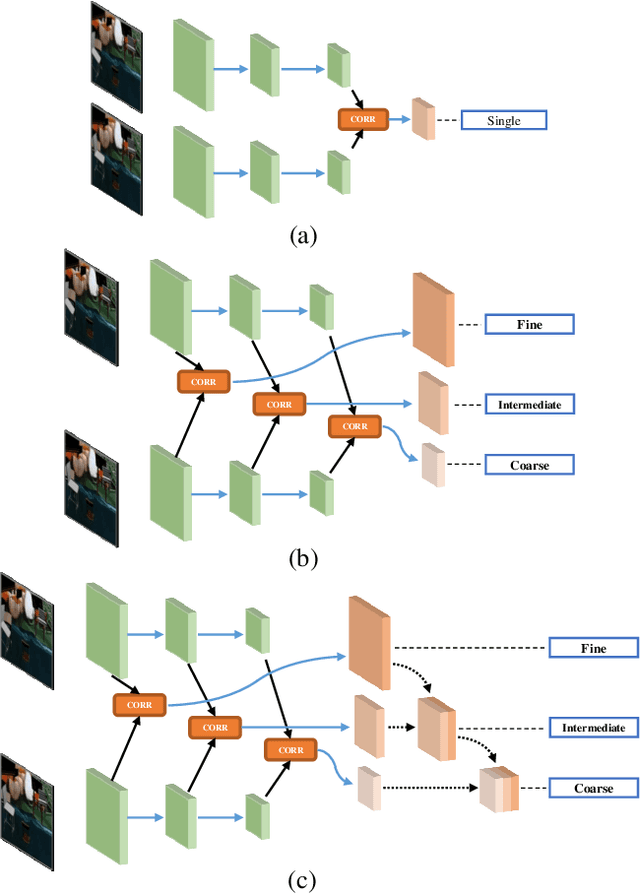
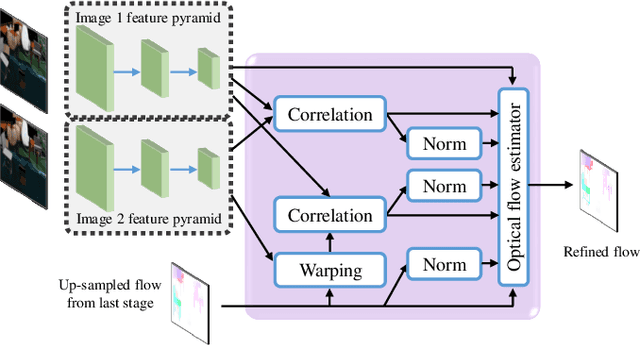
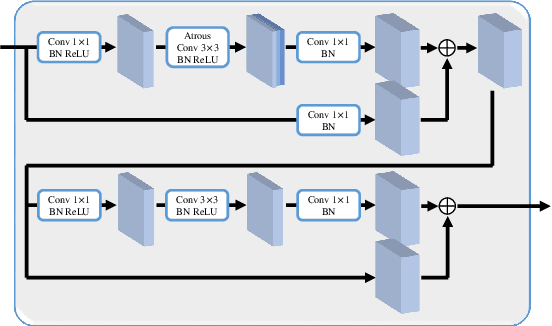
Optical flow estimation is an important yet challenging problem in the field of video analytics. The features of different semantics levels/layers of a convolutional neural network can provide information of different granularity. To exploit such flexible and comprehensive information, we propose a semi-supervised Feature Pyramidal Correlation and Residual Reconstruction Network (FPCR-Net) for optical flow estimation from frame pairs. It consists of two main modules: pyramid correlation mapping and residual reconstruction. The pyramid correlation mapping module takes advantage of the multi-scale correlations of global/local patches by aggregating features of different scales to form a multi-level cost volume. The residual reconstruction module aims to reconstruct the sub-band high-frequency residuals of finer optical flow in each stage. Based on the pyramid correlation mapping, we further propose a correlation-warping-normalization (CWN) module to efficiently exploit the correlation dependency. Experiment results show that the proposed scheme achieves the state-of-the-art performance, with improvement by 0.80, 1.15 and 0.10 in terms of average end-point error (AEE) against competing baseline methods - FlowNet2, LiteFlowNet and PWC-Net on the Final pass of Sintel dataset, respectively.
Temporal-Spatial Mapping for Action Recognition
Sep 11, 2018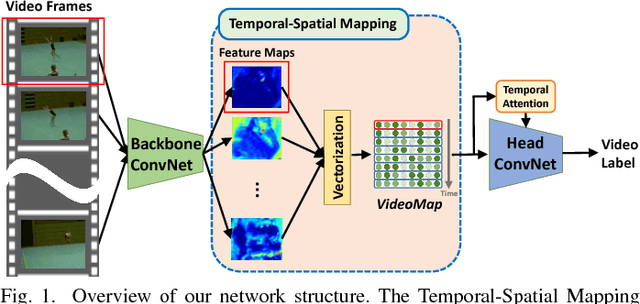
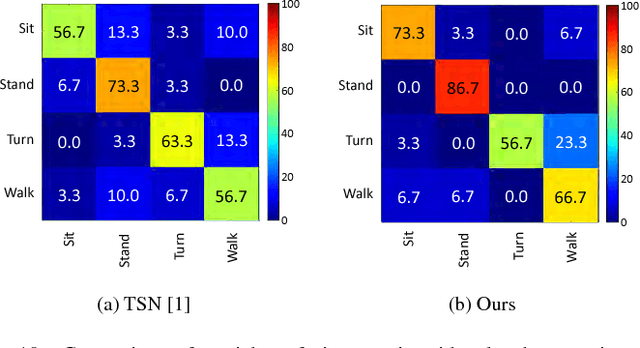

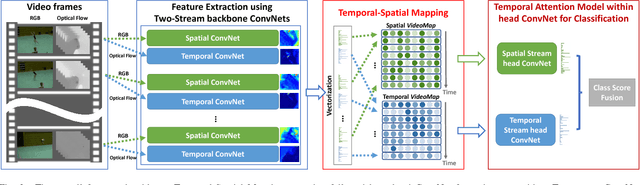
Deep learning models have enjoyed great success for image related computer vision tasks like image classification and object detection. For video related tasks like human action recognition, however, the advancements are not as significant yet. The main challenge is the lack of effective and efficient models in modeling the rich temporal spatial information in a video. We introduce a simple yet effective operation, termed Temporal-Spatial Mapping (TSM), for capturing the temporal evolution of the frames by jointly analyzing all the frames of a video. We propose a video level 2D feature representation by transforming the convolutional features of all frames to a 2D feature map, referred to as VideoMap. With each row being the vectorized feature representation of a frame, the temporal-spatial features are compactly represented, while the temporal dynamic evolution is also well embedded. Based on the VideoMap representation, we further propose a temporal attention model within a shallow convolutional neural network to efficiently exploit the temporal-spatial dynamics. The experiment results show that the proposed scheme achieves the state-of-the-art performance, with 4.2% accuracy gain over Temporal Segment Network (TSN), a competing baseline method, on the challenging human action benchmark dataset HMDB51.