 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapVision: CVPR 2024 Autonomous Grand Challenge Mapless Driving Tech Report
Jun 14, 2024



Autonomous driving without high-definition (HD) maps demands a higher level of active scene understanding. In this competition, the organizers provided the multi-perspective camera images and standard-definition (SD) maps to explore the boundaries of scene reasoning capabilities. We found that most existing algorithms construct Bird's Eye View (BEV) features from these multi-perspective images and use multi-task heads to delineate road centerlines, boundary lines, pedestrian crossings, and other areas. However, these algorithms perform poorly at the far end of roads and struggle when the primary subject in the image is occluded. Therefore, in this competition, we not only used multi-perspective images as input but also incorporated SD maps to address this issue. We employed map encoder pre-training to enhance the network's geometric encoding capabilities and utilized YOLOX to improve traffic element detection precision. Additionally, for area detection, we innovatively introduced LDTR and auxiliary tasks to achieve higher precision. As a result, our final OLUS score is 0.58.
Mapping the Empirical Evidence of the GDPR Effectiveness: A Systematic Review
Oct 25, 2023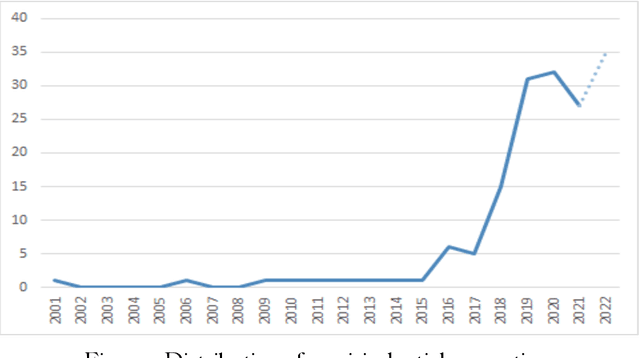
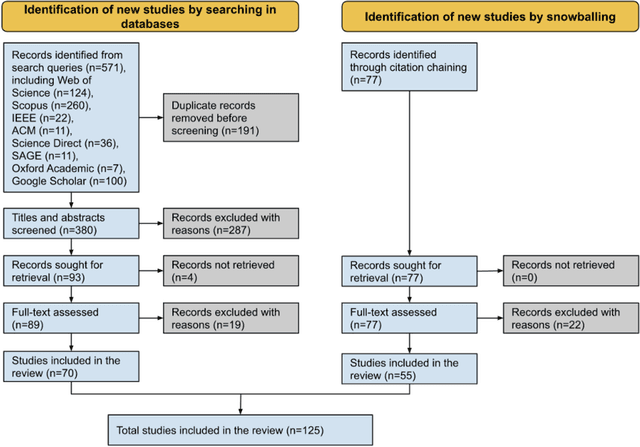
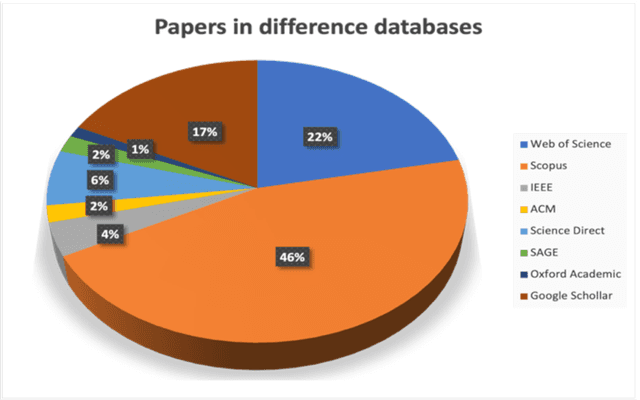
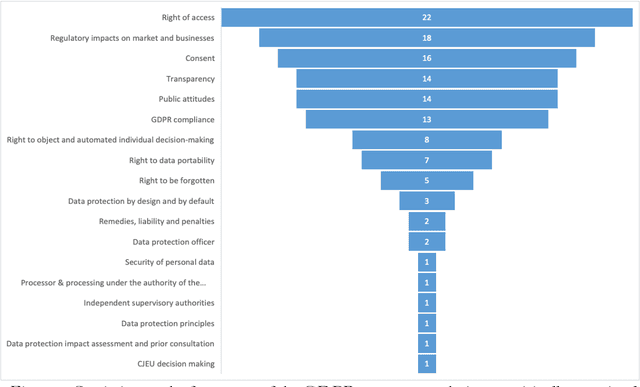
In the realm of data protection, a striking disconnect prevails between traditional domains of doctrinal, legal, theoretical, and policy-based inquiries and a burgeoning body of empirical evidence. Much of the scholarly and regulatory discourse remains entrenched in abstract legal principles or normative frameworks, leaving the empirical landscape uncharted or minimally engaged. Since the birth of EU data protection law, a modest body of empirical evidence has been generated but remains widely scattered and unexamined. Such evidence offers vital insights into the perception, impact, clarity, and effects of data protection measures but languishes on the periphery, inadequately integrated into the broader conversation. To make a meaningful connection, we conduct a comprehensive review and synthesis of empirical research spanning nearly three decades (1995- March 2022), advocating for a more robust integration of empirical evidence into the evaluation and review of the GDPR, while laying a methodological foundation for future empirical research.
S4OD: Semi-Supervised learning for Single-Stage Object Detection
Apr 09, 2022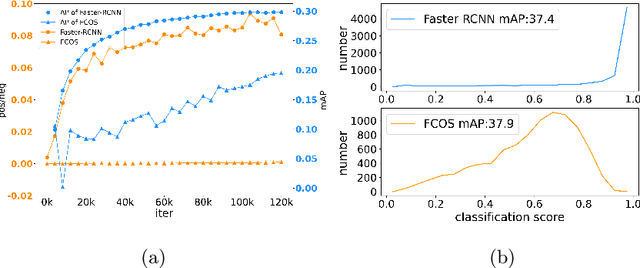
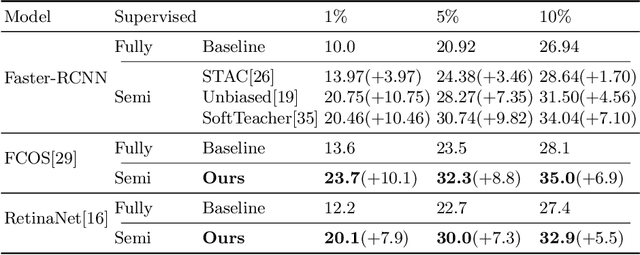
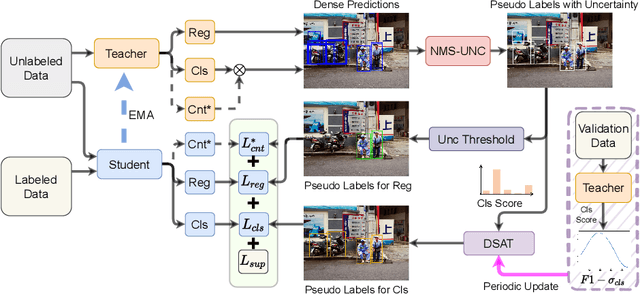

Single-stage detectors suffer from extreme foreground-background class imbalance, while two-stage detectors do not. Therefore, in semi-supervised object detection, two-stage detectors can deliver remarkable performance by only selecting high-quality pseudo labels based on classification scores. However, directly applying this strategy to single-stage detectors would aggravate the class imbalance with fewer positive samples. Thus, single-stage detectors have to consider both quality and quantity of pseudo labels simultaneously. In this paper, we design a dynamic self-adaptive threshold (DSAT) strategy in classification branch, which can automatically select pseudo labels to achieve an optimal trade-off between quality and quantity. Besides, to assess the regression quality of pseudo labels in single-stage detectors, we propose a module to compute the regression uncertainty of boxes based on Non-Maximum Suppression. By leveraging only 10% labeled data from COCO, our method achieves 35.0% AP on anchor-free detector (FCOS) and 32.9% on anchor-based detector (RetinaNet).
2nd Place Solution for VisDA 2021 Challenge -- Universally Domain Adaptive Image Recognition
Oct 27, 2021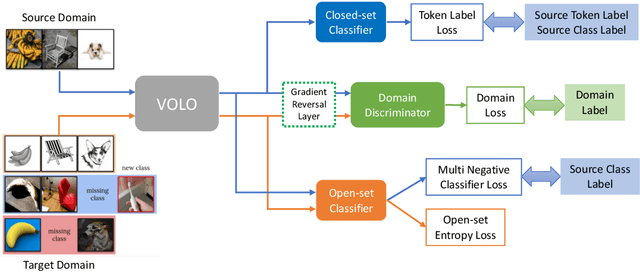
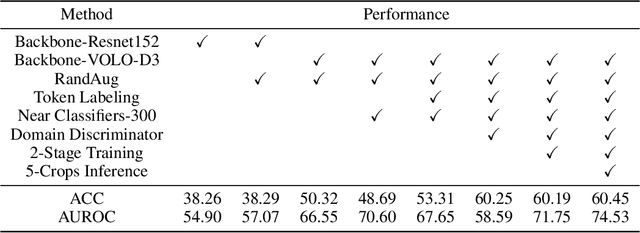
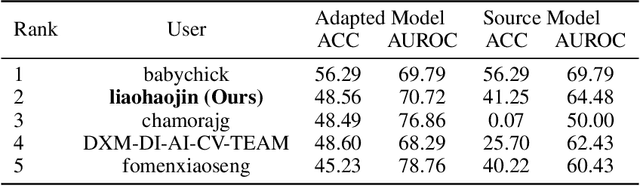
The Visual Domain Adaptation (VisDA) 2021 Challenge calls for unsupervised domain adaptation (UDA) methods that can deal with both input distribution shift and label set variance between the source and target domains. In this report, we introduce a universal domain adaptation (UniDA) method by aggregating several popular feature extraction and domain adaptation schemes. First, we utilize VOLO, a Transformer-based architecture with state-of-the-art performance in several visual tasks, as the backbone to extract effective feature representations. Second, we modify the open-set classifier of OVANet to recognize the unknown class with competitive accuracy and robustness. As shown in the leaderboard, our proposed UniDA method ranks the 2nd place with 48.56% ACC and 70.72% AUROC in the VisDA 2021 Challenge.
2nd Place Solution for Waymo Open Dataset Challenge -- Real-time 2D Object Detection
Jun 16, 2021
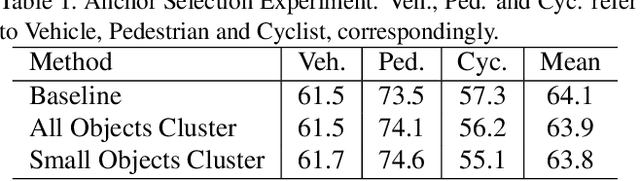
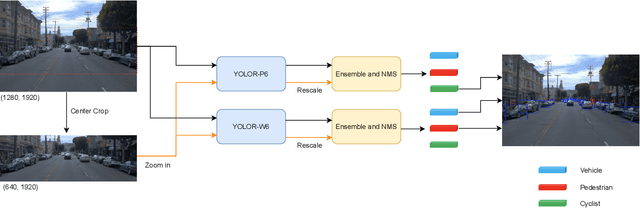
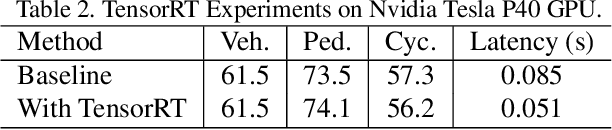
In an autonomous driving system, it is essential to recognize vehicles, pedestrians and cyclists from images. Besides the high accuracy of the prediction, the requirement of real-time running brings new challenges for convolutional network models. In this report, we introduce a real-time method to detect the 2D objects from images. We aggregate several popular one-stage object detectors and train the models of variety input strategies independently, to yield better performance for accurate multi-scale detection of each category, especially for small objects. For model acceleration, we leverage TensorRT to optimize the inference time of our detection pipeline. As shown in the leaderboard, our proposed detection framework ranks the 2nd place with 75.00% L1 mAP and 69.72% L2 mAP in the real-time 2D detection track of the Waymo Open Dataset Challenges, while our framework achieves the latency of 45.8ms/frame on an Nvidia Tesla V100 GPU.
Nondiscriminatory Treatment: a straightforward framework for multi-human parsing
Jan 26, 2021
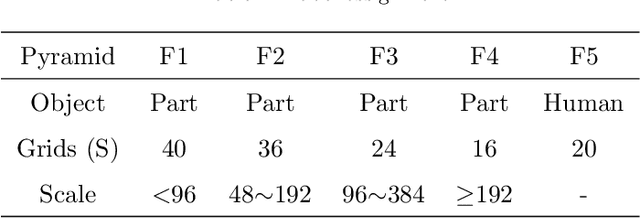
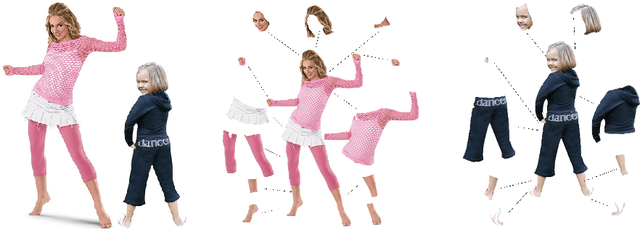

Multi-human parsing aims to segment every body part of every human instance. Nearly all state-of-the-art methods follow the "detection first" or "segmentation first" pipelines. Different from them, we present an end-to-end and box-free pipeline from a new and more human-intuitive perspective. In training time, we directly do instance segmentation on humans and parts. More specifically, we introduce a notion of "indiscriminate objects with categorie" which treats humans and parts without distinction and regards them both as instances with categories. In the mask prediction, each binary mask is obtained by a combination of prototypes shared among all human and part categories. In inference time, we design a brand-new grouping post-processing method that relates each part instance with one single human instance and groups them together to obtain the final human-level parsing result. We name our method as Nondiscriminatory Treatment between Humans and Parts for Human Parsing (NTHP). Experiments show that our network performs superiorly against state-of-the-art methods by a large margin on the MHP v2.0 and PASCAL-Person-Part datasets.