 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS4OD: Semi-Supervised learning for Single-Stage Object Detection
Apr 09, 2022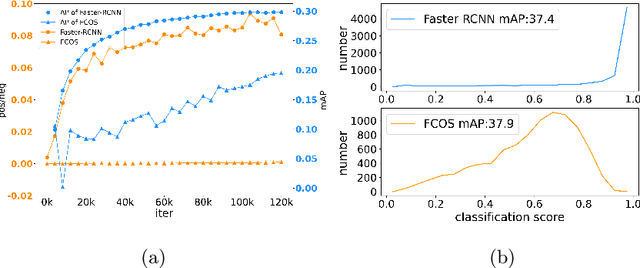
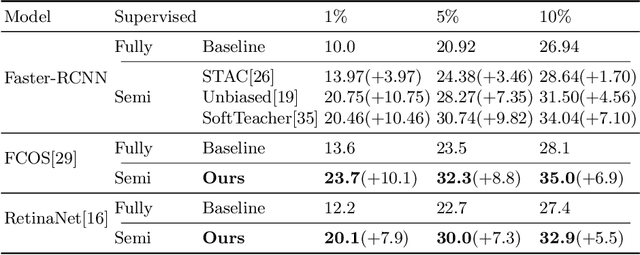
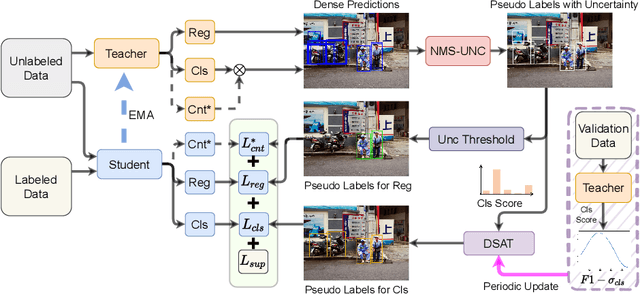

Single-stage detectors suffer from extreme foreground-background class imbalance, while two-stage detectors do not. Therefore, in semi-supervised object detection, two-stage detectors can deliver remarkable performance by only selecting high-quality pseudo labels based on classification scores. However, directly applying this strategy to single-stage detectors would aggravate the class imbalance with fewer positive samples. Thus, single-stage detectors have to consider both quality and quantity of pseudo labels simultaneously. In this paper, we design a dynamic self-adaptive threshold (DSAT) strategy in classification branch, which can automatically select pseudo labels to achieve an optimal trade-off between quality and quantity. Besides, to assess the regression quality of pseudo labels in single-stage detectors, we propose a module to compute the regression uncertainty of boxes based on Non-Maximum Suppression. By leveraging only 10% labeled data from COCO, our method achieves 35.0% AP on anchor-free detector (FCOS) and 32.9% on anchor-based detector (RetinaNet).
2nd Place Solution for Waymo Open Dataset Challenge -- Real-time 2D Object Detection
Jun 16, 2021
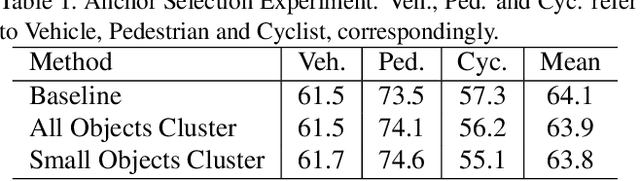
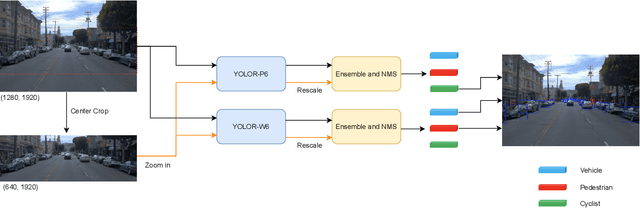
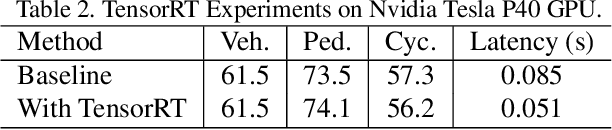
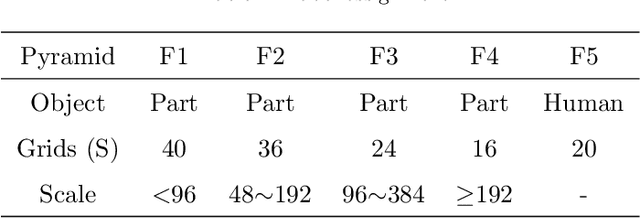
In an autonomous driving system, it is essential to recognize vehicles, pedestrians and cyclists from images. Besides the high accuracy of the prediction, the requirement of real-time running brings new challenges for convolutional network models. In this report, we introduce a real-time method to detect the 2D objects from images. We aggregate several popular one-stage object detectors and train the models of variety input strategies independently, to yield better performance for accurate multi-scale detection of each category, especially for small objects. For model acceleration, we leverage TensorRT to optimize the inference time of our detection pipeline. As shown in the leaderboard, our proposed detection framework ranks the 2nd place with 75.00% L1 mAP and 69.72% L2 mAP in the real-time 2D detection track of the Waymo Open Dataset Challenges, while our framework achieves the latency of 45.8ms/frame on an Nvidia Tesla V100 GPU.
Nondiscriminatory Treatment: a straightforward framework for multi-human parsing
Jan 26, 2021
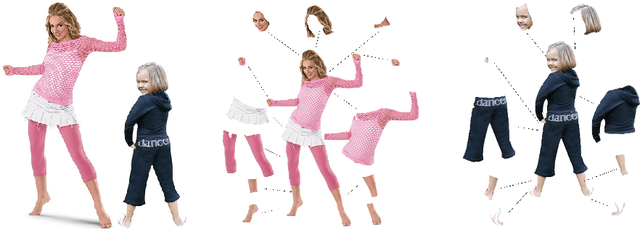

Multi-human parsing aims to segment every body part of every human instance. Nearly all state-of-the-art methods follow the "detection first" or "segmentation first" pipelines. Different from them, we present an end-to-end and box-free pipeline from a new and more human-intuitive perspective. In training time, we directly do instance segmentation on humans and parts. More specifically, we introduce a notion of "indiscriminate objects with categorie" which treats humans and parts without distinction and regards them both as instances with categories. In the mask prediction, each binary mask is obtained by a combination of prototypes shared among all human and part categories. In inference time, we design a brand-new grouping post-processing method that relates each part instance with one single human instance and groups them together to obtain the final human-level parsing result. We name our method as Nondiscriminatory Treatment between Humans and Parts for Human Parsing (NTHP). Experiments show that our network performs superiorly against state-of-the-art methods by a large margin on the MHP v2.0 and PASCAL-Person-Part datasets.