 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinker: A vision-language foundation model for embodied intelligence
Jan 29, 2026When large vision-language models are applied to the field of robotics, they encounter problems that are simple for humans yet error-prone for models. Such issues include confusion between third-person and first-person perspectives and a tendency to overlook information in video endings during temporal reasoning. To address these challenges, we propose Thinker, a large vision-language foundation model designed for embodied intelligence. We tackle the aforementioned issues from two perspectives. Firstly, we construct a large-scale dataset tailored for robotic perception and reasoning, encompassing ego-view videos, visual grounding, spatial understanding, and chain-of-thought data. Secondly, we introduce a simple yet effective approach that substantially enhances the model's capacity for video comprehension by jointly incorporating key frames and full video sequences as inputs. Our model achieves state-of-the-art results on two of the most commonly used benchmark datasets in the field of task planning.
MapVision: CVPR 2024 Autonomous Grand Challenge Mapless Driving Tech Report
Jun 14, 2024



Autonomous driving without high-definition (HD) maps demands a higher level of active scene understanding. In this competition, the organizers provided the multi-perspective camera images and standard-definition (SD) maps to explore the boundaries of scene reasoning capabilities. We found that most existing algorithms construct Bird's Eye View (BEV) features from these multi-perspective images and use multi-task heads to delineate road centerlines, boundary lines, pedestrian crossings, and other areas. However, these algorithms perform poorly at the far end of roads and struggle when the primary subject in the image is occluded. Therefore, in this competition, we not only used multi-perspective images as input but also incorporated SD maps to address this issue. We employed map encoder pre-training to enhance the network's geometric encoding capabilities and utilized YOLOX to improve traffic element detection precision. Additionally, for area detection, we innovatively introduced LDTR and auxiliary tasks to achieve higher precision. As a result, our final OLUS score is 0.58.
Distill-then-prune: An Efficient Compression Framework for Real-time Stereo Matching Network on Edge Devices
May 20, 2024



In recent years, numerous real-time stereo matching methods have been introduced, but they often lack accuracy. These methods attempt to improve accuracy by introducing new modules or integrating traditional methods. However, the improvements are only modest. In this paper, we propose a novel strategy by incorporating knowledge distillation and model pruning to overcome the inherent trade-off between speed and accuracy. As a result, we obtained a model that maintains real-time performance while delivering high accuracy on edge devices. Our proposed method involves three key steps. Firstly, we review state-of-the-art methods and design our lightweight model by removing redundant modules from those efficient models through a comparison of their contributions. Next, we leverage the efficient model as the teacher to distill knowledge into the lightweight model. Finally, we systematically prune the lightweight model to obtain the final model. Through extensive experiments conducted on two widely-used benchmarks, Sceneflow and KITTI, we perform ablation studies to analyze the effectiveness of each module and present our state-of-the-art results.
MANet: Multimodal Attention Network based Point- View fusion for 3D Shape Recognition
Feb 28, 2020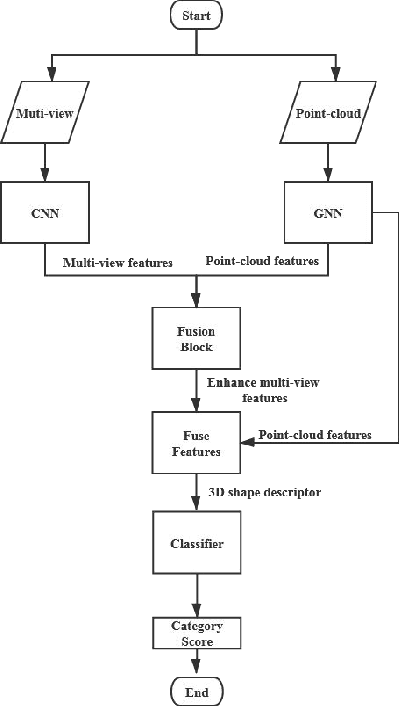
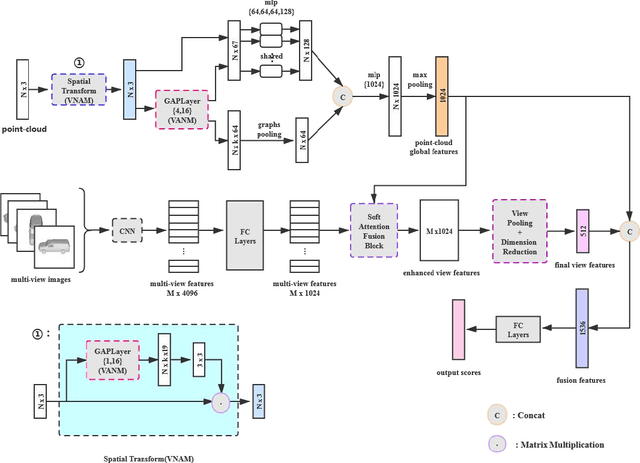
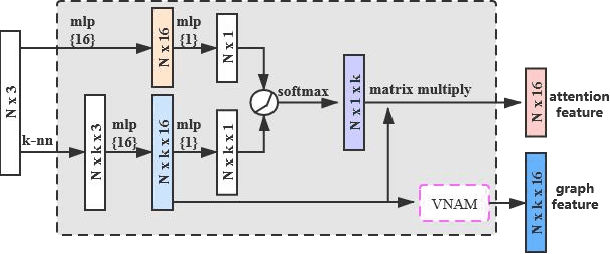
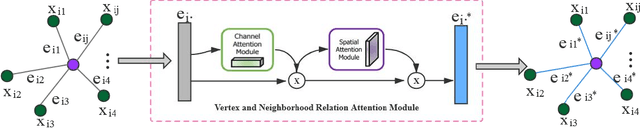
3D shape recognition has attracted more and more attention as a task of 3D vision research. The proliferation of 3D data encourages various deep learning methods based on 3D data. Now there have been many deep learning models based on point-cloud data or multi-view data alone. However, in the era of big data, integrating data of two different modals to obtain a unified 3D shape descriptor is bound to improve the recognition accuracy. Therefore, this paper proposes a fusion network based on multimodal attention mechanism for 3D shape recognition. Considering the limitations of multi-view data, we introduce a soft attention scheme, which can use the global point-cloud features to filter the multi-view features, and then realize the effective fusion of the two features. More specifically, we obtain the enhanced multi-view features by mining the contribution of each multi-view image to the overall shape recognition, and then fuse the point-cloud features and the enhanced multi-view features to obtain a more discriminative 3D shape descriptor. We have performed relevant experiments on the ModelNet40 dataset, and experimental results verify the effectiveness of our method.
MagicVO: End-to-End Monocular Visual Odometry through Deep Bi-directional Recurrent Convolutional Neural Network
Nov 28, 2018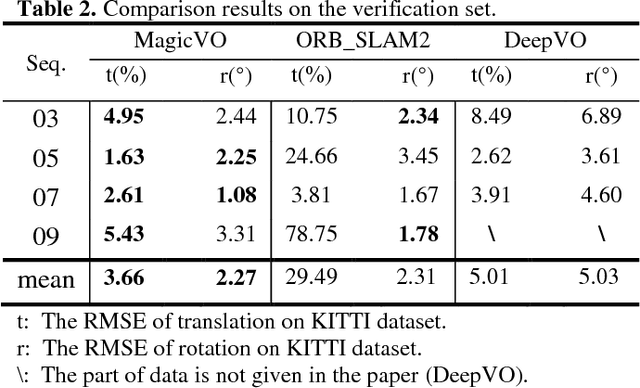
This paper proposes a new framework to solve the problem of monocular visual odometry, called MagicVO . Based on Convolutional Neural Network (CNN) and Bi-directional LSTM (Bi-LSTM), MagicVO outputs a 6-DoF absolute-scale pose at each position of the camera with a sequence of continuous monocular images as input. It not only utilizes the outstanding performance of CNN in image feature processing to extract the rich features of image frames fully but also learns the geometric relationship from image sequences pre and post through Bi-LSTM to get a more accurate prediction. A pipeline of the MagicVO is shown in Fig. 1. The MagicVO system is end-to-end, and the results of experiments on the KITTI dataset and the ETH-asl cla dataset show that MagicVO has a better performance than traditional visual odometry (VO) systems in the accuracy of pose and the generalization ability.