 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinker: A vision-language foundation model for embodied intelligence
Jan 29, 2026When large vision-language models are applied to the field of robotics, they encounter problems that are simple for humans yet error-prone for models. Such issues include confusion between third-person and first-person perspectives and a tendency to overlook information in video endings during temporal reasoning. To address these challenges, we propose Thinker, a large vision-language foundation model designed for embodied intelligence. We tackle the aforementioned issues from two perspectives. Firstly, we construct a large-scale dataset tailored for robotic perception and reasoning, encompassing ego-view videos, visual grounding, spatial understanding, and chain-of-thought data. Secondly, we introduce a simple yet effective approach that substantially enhances the model's capacity for video comprehension by jointly incorporating key frames and full video sequences as inputs. Our model achieves state-of-the-art results on two of the most commonly used benchmark datasets in the field of task planning.
The Sampling-Gaussian for stereo matching
Oct 09, 2024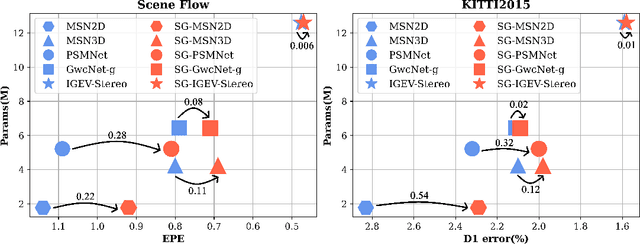

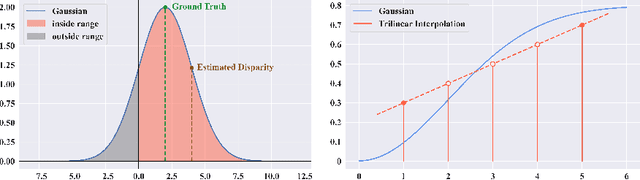
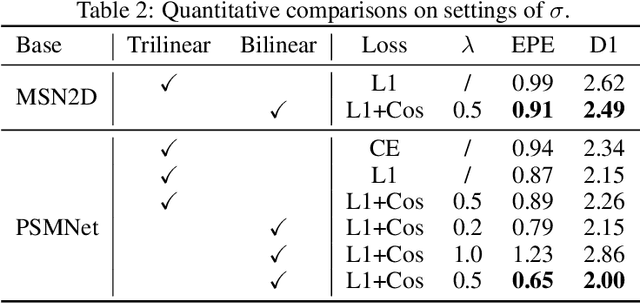
The soft-argmax operation is widely adopted in neural network-based stereo matching methods to enable differentiable regression of disparity. However, network trained with soft-argmax is prone to being multimodal due to absence of explicit constraint to the shape of the probability distribution. Previous methods leverages Laplacian distribution and cross-entropy for training but failed to effectively improve the accuracy and even compromises the efficiency of the network. In this paper, we conduct a detailed analysis of the previous distribution-based methods and propose a novel supervision method for stereo matching, Sampling-Gaussian. We sample from the Gaussian distribution for supervision. Moreover, we interpret the training as minimizing the distance in vector space and propose a combined loss of L1 loss and cosine similarity loss. Additionally, we leveraged bilinear interpolation to upsample the cost volume. Our method can be directly applied to any soft-argmax-based stereo matching method without a reduction in efficiency. We have conducted comprehensive experiments to demonstrate the superior performance of our Sampling-Gaussian. The experimental results prove that we have achieved better accuracy on five baseline methods and two datasets. Our method is easy to implement, and the code is available online.
Distill-then-prune: An Efficient Compression Framework for Real-time Stereo Matching Network on Edge Devices
May 20, 2024In recent years, numerous real-time stereo matching methods have been introduced, but they often lack accuracy. These methods attempt to improve accuracy by introducing new modules or integrating traditional methods. However, the improvements are only modest. In this paper, we propose a novel strategy by incorporating knowledge distillation and model pruning to overcome the inherent trade-off between speed and accuracy. As a result, we obtained a model that maintains real-time performance while delivering high accuracy on edge devices. Our proposed method involves three key steps. Firstly, we review state-of-the-art methods and design our lightweight model by removing redundant modules from those efficient models through a comparison of their contributions. Next, we leverage the efficient model as the teacher to distill knowledge into the lightweight model. Finally, we systematically prune the lightweight model to obtain the final model. Through extensive experiments conducted on two widely-used benchmarks, Sceneflow and KITTI, we perform ablation studies to analyze the effectiveness of each module and present our state-of-the-art results.