 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneses: Unified Generative Speech Enhancement and Separation
Jan 26, 2026Real-world audio recordings often contain multiple speakers and various degradations, which limit both the quantity and quality of speech data available for building state-of-the-art speech processing models. Although end-to-end approaches that concatenate speech enhancement (SE) and speech separation (SS) to obtain a clean speech signal for each speaker are promising, conventional SE-SS methods suffer from complex degradations beyond additive noise. To this end, we propose \textbf{Geneses}, a generative framework to achieve unified, high-quality SE--SS. Our Geneses leverages latent flow matching to estimate each speaker's clean speech features using multi-modal diffusion Transformer conditioned on self-supervised learning representation from noisy mixture. We conduct experimental evaluation using two-speaker mixtures from LibriTTS-R under two conditions: additive-noise-only and complex degradations. The results demonstrate that Geneses significantly outperforms a conventional mask-based SE--SS method across various objective metrics with high robustness against complex degradations. Audio samples are available in our demo page.
ReverbMiipher: Generative Speech Restoration meets Reverberation Characteristics Controllability
May 08, 2025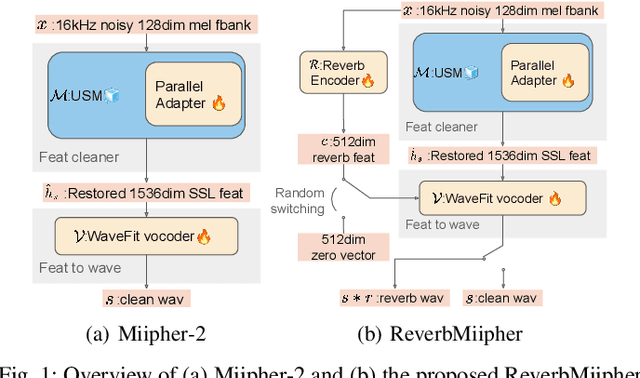
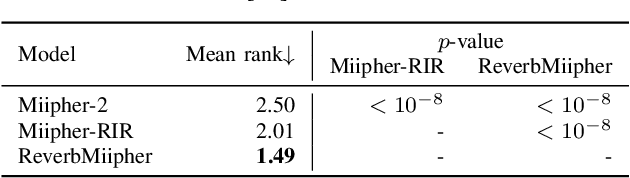
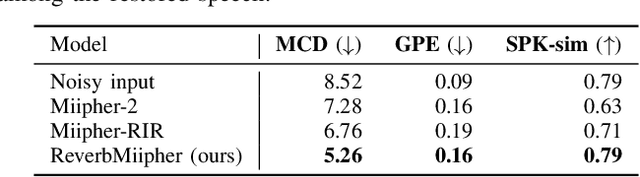
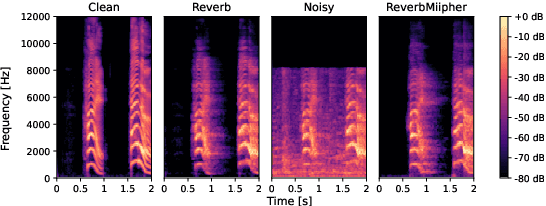
Reverberation encodes spatial information regarding the acoustic source environment, yet traditional Speech Restoration (SR) usually completely removes reverberation. We propose ReverbMiipher, an SR model extending parametric resynthesis framework, designed to denoise speech while preserving and enabling control over reverberation. ReverbMiipher incorporates a dedicated ReverbEncoder to extract a reverb feature vector from noisy input. This feature conditions a vocoder to reconstruct the speech signal, removing noise while retaining the original reverberation characteristics. A stochastic zero-vector replacement strategy during training ensures the feature specifically encodes reverberation, disentangling it from other speech attributes. This learned representation facilitates reverberation control via techniques such as interpolation between features, replacement with features from other utterances, or sampling from a latent space. Objective and subjective evaluations confirm ReverbMiipher effectively preserves reverberation, removes other artifacts, and outperforms the conventional two-stage SR and convolving simulated room impulse response approach. We further demonstrate its ability to generate novel reverberation effects through feature manipulation.
Causal Speech Enhancement with Predicting Semantics based on Quantized Self-supervised Learning Features
Dec 26, 2024Real-time speech enhancement (SE) is essential to online speech communication. Causal SE models use only the previous context while predicting future information, such as phoneme continuation, may help performing causal SE. The phonetic information is often represented by quantizing latent features of self-supervised learning (SSL) models. This work is the first to incorporate SSL features with causality into an SE model. The causal SSL features are encoded and combined with spectrogram features using feature-wise linear modulation to estimate a mask for enhancing the noisy input speech. Simultaneously, we quantize the causal SSL features using vector quantization to represent phonetic characteristics as semantic tokens. The model not only encodes SSL features but also predicts the future semantic tokens in multi-task learning (MTL). The experimental results using VoiceBank + DEMAND dataset show that our proposed method achieves 2.88 in PESQ, especially with semantic prediction MTL, in which we confirm that the semantic prediction played an important role in causal SE.
The T05 System for The VoiceMOS Challenge 2024: Transfer Learning from Deep Image Classifier to Naturalness MOS Prediction of High-Quality Synthetic Speech
Sep 14, 2024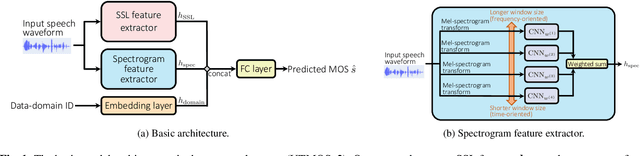
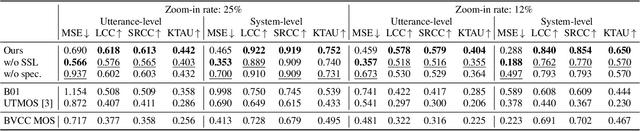

We present our system (denoted as T05) for the VoiceMOS Challenge (VMC) 2024. Our system was designed for the VMC 2024 Track 1, which focused on the accurate prediction of naturalness mean opinion score (MOS) for high-quality synthetic speech. In addition to a pretrained self-supervised learning (SSL)-based speech feature extractor, our system incorporates a pretrained image feature extractor to capture the difference of synthetic speech observed in speech spectrograms. We first separately train two MOS predictors that use either of an SSL-based or spectrogram-based feature. Then, we fine-tune the two predictors for better MOS prediction using the fusion of two extracted features. In the VMC 2024 Track 1, our T05 system achieved first place in 7 out of 16 evaluation metrics and second place in the remaining 9 metrics, with a significant difference compared to those ranked third and below. We also report the results of our ablation study to investigate essential factors of our system.
J-CHAT: Japanese Large-scale Spoken Dialogue Corpus for Spoken Dialogue Language Modeling
Jul 22, 2024



Spoken dialogue plays a crucial role in human-AI interactions, necessitating dialogue-oriented spoken language models (SLMs). To develop versatile SLMs, large-scale and diverse speech datasets are essential. Additionally, to ensure hiqh-quality speech generation, the data must be spontaneous like in-wild data and must be acoustically clean with noise removed. Despite the critical need, no open-source corpus meeting all these criteria has been available. This study addresses this gap by constructing and releasing a large-scale spoken dialogue corpus, named Japanese Corpus for Human-AI Talks (J-CHAT), which is publicly accessible. Furthermore, this paper presents a language-independent method for corpus construction and describes experiments on dialogue generation using SLMs trained on J-CHAT. Experimental results indicate that the collected data from multiple domains by our method improve the naturalness and meaningfulness of dialogue generation.
UTDUSS: UTokyo-SaruLab System for Interspeech2024 Speech Processing Using Discrete Speech Unit Challenge
Mar 20, 2024



We present UTDUSS, the UTokyo-SaruLab system submitted to Interspeech2024 Speech Processing Using Discrete Speech Unit Challenge. The challenge focuses on using discrete speech unit learned from large speech corpora for some tasks. We submitted our UTDUSS system to two text-to-speech tracks: Vocoder and Acoustic+Vocoder. Our system incorporates neural audio codec (NAC) pre-trained on only speech corpora, which makes the learned codec represent rich acoustic features that are necessary for high-fidelity speech reconstruction. For the acoustic+vocoder track, we trained an acoustic model based on Transformer encoder-decoder that predicted the pre-trained NAC tokens from text input. We describe our strategies to build these models, such as data selection, downsampling, and hyper-parameter tuning. Our system ranked in second and first for the Vocoder and Acoustic+Vocoder tracks, respectively.
Building speech corpus with diverse voice characteristics for its prompt-based representation
Mar 20, 2024



In text-to-speech synthesis, the ability to control voice characteristics is vital for various applications. By leveraging thriving text prompt-based generation techniques, it should be possible to enhance the nuanced control of voice characteristics. While previous research has explored the prompt-based manipulation of voice characteristics, most studies have used pre-recorded speech, which limits the diversity of voice characteristics available. Thus, we aim to address this gap by creating a novel corpus and developing a model for prompt-based manipulation of voice characteristics in text-to-speech synthesis, facilitating a broader range of voice characteristics. Specifically, we propose a method to build a sizable corpus pairing voice characteristics descriptions with corresponding speech samples. This involves automatically gathering voice-related speech data from the Internet, ensuring its quality, and manually annotating it using crowdsourcing. We implement this method with Japanese language data and analyze the results to validate its effectiveness. Subsequently, we propose a construction method of the model to retrieve speech from voice characteristics descriptions based on a contrastive learning method. We train the model using not only conservative contrastive learning but also feature prediction learning to predict quantitative speech features corresponding to voice characteristics. We evaluate the model performance via experiments with the corpus we constructed above.
Coco-Nut: Corpus of Japanese Utterance and Voice Characteristics Description for Prompt-based Control
Sep 24, 2023



In text-to-speech, controlling voice characteristics is important in achieving various-purpose speech synthesis. Considering the success of text-conditioned generation, such as text-to-image, free-form text instruction should be useful for intuitive and complicated control of voice characteristics. A sufficiently large corpus of high-quality and diverse voice samples with corresponding free-form descriptions can advance such control research. However, neither an open corpus nor a scalable method is currently available. To this end, we develop Coco-Nut, a new corpus including diverse Japanese utterances, along with text transcriptions and free-form voice characteristics descriptions. Our methodology to construct this corpus consists of 1) automatic collection of voice-related audio data from the Internet, 2) quality assurance, and 3) manual annotation using crowdsourcing. Additionally, we benchmark our corpus on the prompt embedding model trained by contrastive speech-text learning.
UTMOS: UTokyo-SaruLab System for VoiceMOS Challenge 2022
Apr 05, 2022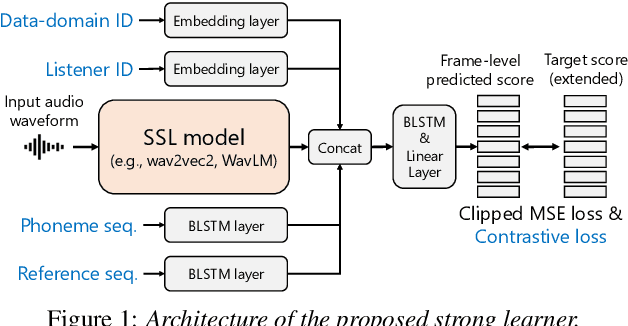
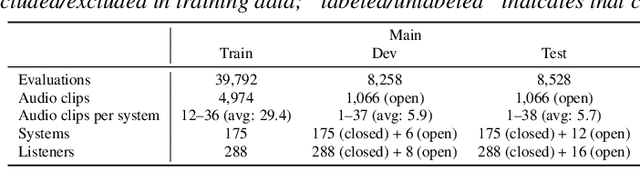
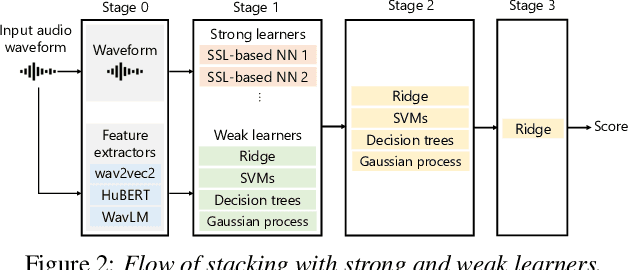
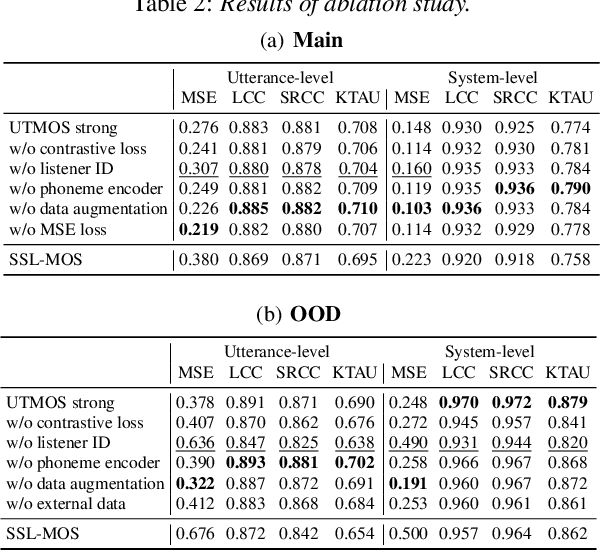
We present the UTokyo-SaruLab mean opinion score (MOS) prediction system submitted to VoiceMOS Challenge 2022. The challenge is to predict the MOS values of speech samples collected from previous Blizzard Challenges and Voice Conversion Challenges for two tracks: a main track for in-domain prediction and an out-of-domain (OOD) track for which there is less labeled data from different listening tests. Our system is based on ensemble learning of strong and weak learners. Strong learners incorporate several improvements to the previous fine-tuning models of self-supervised learning (SSL) models, while weak learners use basic machine-learning methods to predict scores from SSL features. In the Challenge, our system had the highest score on several metrics for both the main and OOD tracks. In addition, we conducted ablation studies to investigate the effectiveness of our proposed methods.
J-MAC: Japanese multi-speaker audiobook corpus for speech synthesis
Jan 26, 2022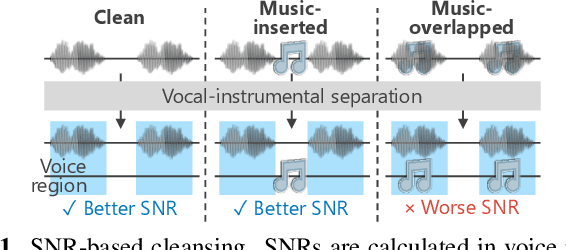

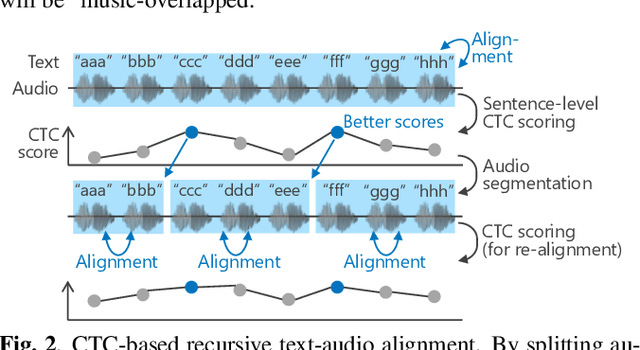
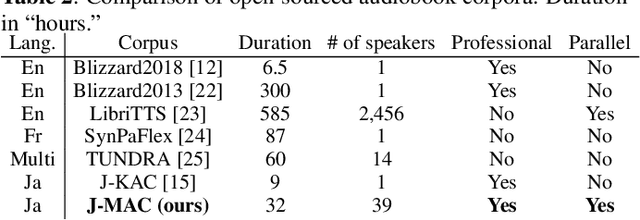
In this paper, we construct a Japanese audiobook speech corpus called "J-MAC" for speech synthesis research. With the success of reading-style speech synthesis, the research target is shifting to tasks that use complicated contexts. Audiobook speech synthesis is a good example that requires cross-sentence, expressiveness, etc. Unlike reading-style speech, speaker-specific expressiveness in audiobook speech also becomes the context. To enhance this research, we propose a method of constructing a corpus from audiobooks read by professional speakers. From many audiobooks and their texts, our method can automatically extract and refine the data without any language dependency. Specifically, we use vocal-instrumental separation to extract clean data, connectionist temporal classification to roughly align text and audio, and voice activity detection to refine the alignment. J-MAC is open-sourced in our project page. We also conduct audiobook speech synthesis evaluations, and the results give insights into audiobook speech synthesis.