 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJ-MAC: Japanese multi-speaker audiobook corpus for speech synthesis
Paper and Code
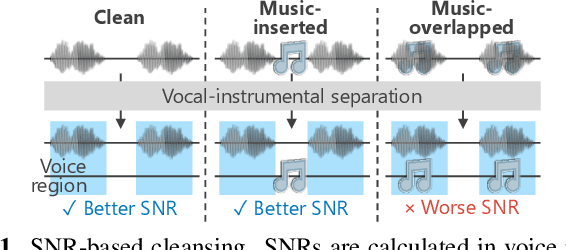

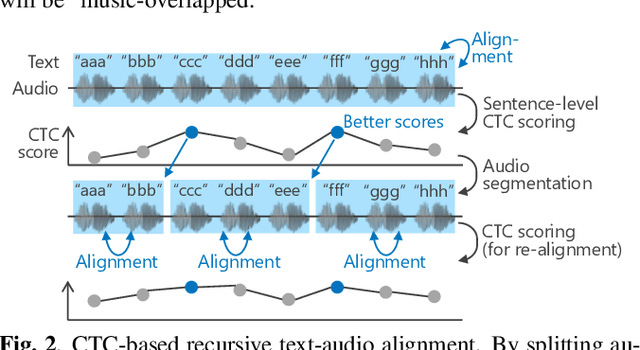
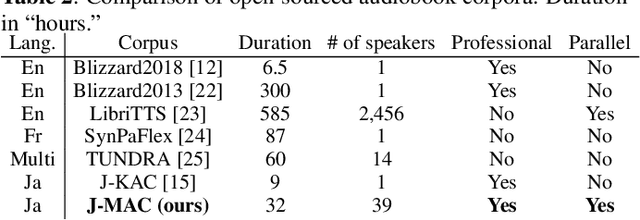
In this paper, we construct a Japanese audiobook speech corpus called "J-MAC" for speech synthesis research. With the success of reading-style speech synthesis, the research target is shifting to tasks that use complicated contexts. Audiobook speech synthesis is a good example that requires cross-sentence, expressiveness, etc. Unlike reading-style speech, speaker-specific expressiveness in audiobook speech also becomes the context. To enhance this research, we propose a method of constructing a corpus from audiobooks read by professional speakers. From many audiobooks and their texts, our method can automatically extract and refine the data without any language dependency. Specifically, we use vocal-instrumental separation to extract clean data, connectionist temporal classification to roughly align text and audio, and voice activity detection to refine the alignment. J-MAC is open-sourced in our project page. We also conduct audiobook speech synthesis evaluations, and the results give insights into audiobook speech synthesis.