 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgejaCappella Corpus: A Japanese a Cappella Vocal Ensemble Corpus
Dec 09, 2022



We construct a corpus of Japanese a cappella vocal ensembles (jaCappella corpus) for vocal ensemble separation and synthesis. It consists of 35 copyright-cleared vocal ensemble songs and their audio recordings of individual voice parts. These songs were arranged from out-of-copyright Japanese children's songs and have six voice parts (lead vocal, soprano, alto, tenor, bass, and vocal percussion). They are divided into seven subsets, each of which features typical characteristics of a music genre such as jazz and enka. The variety in genre and voice part match vocal ensembles recently widespread in social media services such as YouTube, although the main targets of conventional vocal ensemble datasets are choral singing made up of soprano, alto, tenor, and bass. Experimental evaluation demonstrates that our corpus is a challenging resource for vocal ensemble separation. Our corpus is available on our project page (https://tomohikonakamura.github.io/jaCappella_corpus/).
SelfRemaster: Self-Supervised Speech Restoration with Analysis-by-Synthesis Approach Using Channel Modeling
Mar 24, 2022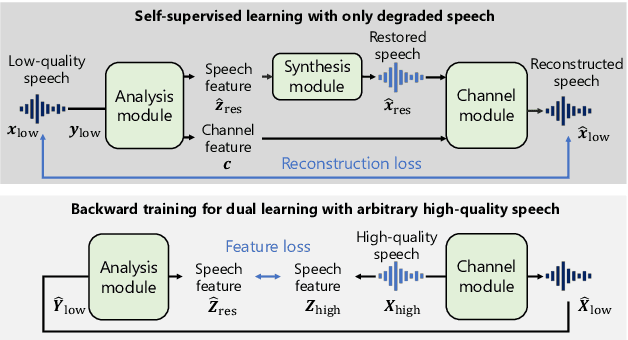
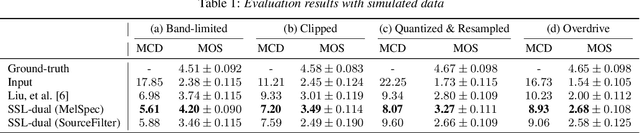
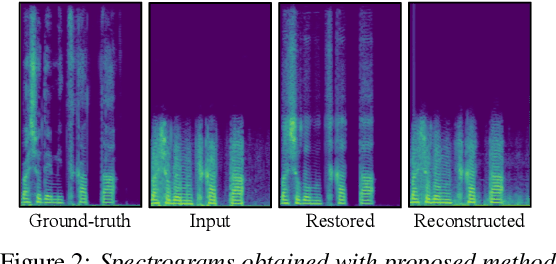
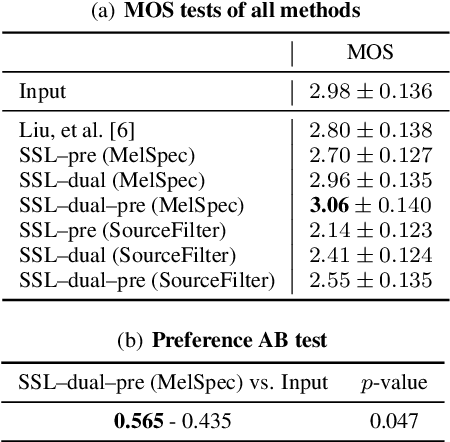
We present a self-supervised speech restoration method without paired speech corpora. Because the previous general speech restoration method uses artificial paired data created by applying various distortions to high-quality speech corpora, it cannot sufficiently represent acoustic distortions of real data, limiting the applicability. Our model consists of analysis, synthesis, and channel modules that simulate the recording process of degraded speech and is trained with real degraded speech data in a self-supervised manner. The analysis module extracts distortionless speech features and distortion features from degraded speech, while the synthesis module synthesizes the restored speech waveform, and the channel module adds distortions to the speech waveform. Our model also enables audio effect transfer, in which only acoustic distortions are extracted from degraded speech and added to arbitrary high-quality audio. Experimental evaluations with both simulated and real data show that our method achieves significantly higher-quality speech restoration than the previous supervised method, suggesting its applicability to real degraded speech materials.
J-MAC: Japanese multi-speaker audiobook corpus for speech synthesis
Jan 26, 2022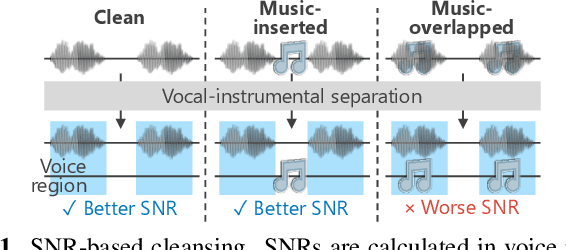

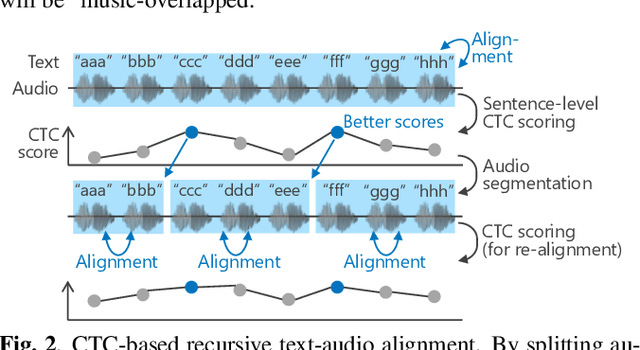
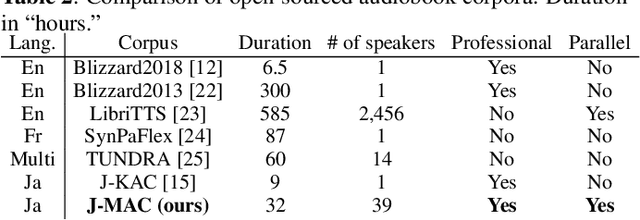
In this paper, we construct a Japanese audiobook speech corpus called "J-MAC" for speech synthesis research. With the success of reading-style speech synthesis, the research target is shifting to tasks that use complicated contexts. Audiobook speech synthesis is a good example that requires cross-sentence, expressiveness, etc. Unlike reading-style speech, speaker-specific expressiveness in audiobook speech also becomes the context. To enhance this research, we propose a method of constructing a corpus from audiobooks read by professional speakers. From many audiobooks and their texts, our method can automatically extract and refine the data without any language dependency. Specifically, we use vocal-instrumental separation to extract clean data, connectionist temporal classification to roughly align text and audio, and voice activity detection to refine the alignment. J-MAC is open-sourced in our project page. We also conduct audiobook speech synthesis evaluations, and the results give insights into audiobook speech synthesis.