 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelfRemaster: Self-Supervised Speech Restoration with Analysis-by-Synthesis Approach Using Channel Modeling
Paper and Code
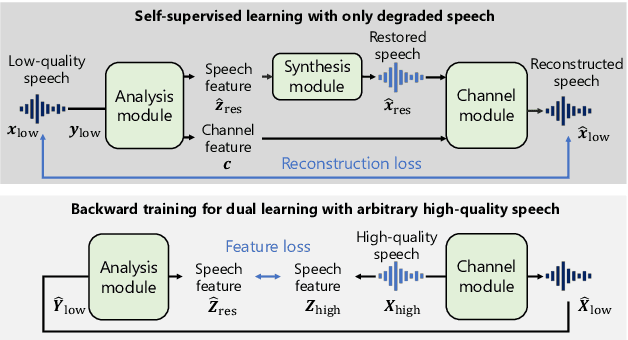
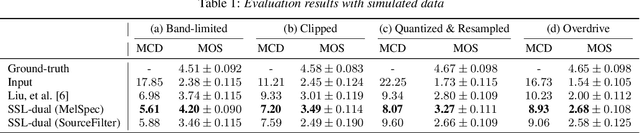
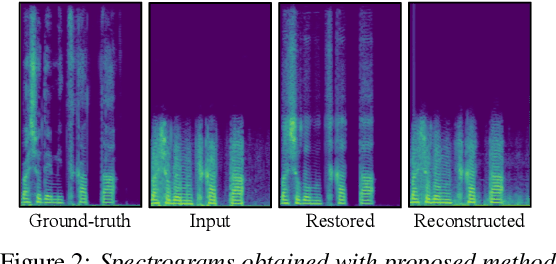
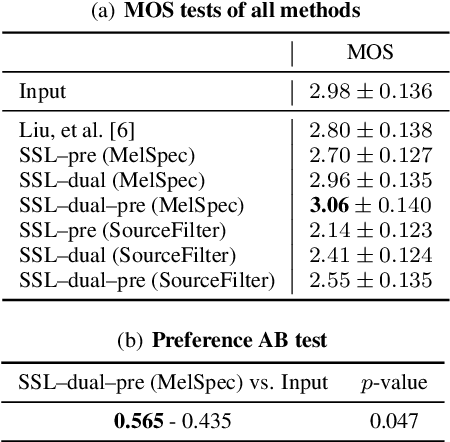
We present a self-supervised speech restoration method without paired speech corpora. Because the previous general speech restoration method uses artificial paired data created by applying various distortions to high-quality speech corpora, it cannot sufficiently represent acoustic distortions of real data, limiting the applicability. Our model consists of analysis, synthesis, and channel modules that simulate the recording process of degraded speech and is trained with real degraded speech data in a self-supervised manner. The analysis module extracts distortionless speech features and distortion features from degraded speech, while the synthesis module synthesizes the restored speech waveform, and the channel module adds distortions to the speech waveform. Our model also enables audio effect transfer, in which only acoustic distortions are extracted from degraded speech and added to arbitrary high-quality audio. Experimental evaluations with both simulated and real data show that our method achieves significantly higher-quality speech restoration than the previous supervised method, suggesting its applicability to real degraded speech materials.