 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional PED-ANOVA: Hyperparameter Importance in Hierarchical & Dynamic Search Spaces
Jan 28, 2026We propose conditional PED-ANOVA (condPED-ANOVA), a principled framework for estimating hyperparameter importance (HPI) in conditional search spaces, where the presence or domain of a hyperparameter can depend on other hyperparameters. Although the original PED-ANOVA provides a fast and efficient way to estimate HPI within the top-performing regions of the search space, it assumes a fixed, unconditional search space and therefore cannot properly handle conditional hyperparameters. To address this, we introduce a conditional HPI for top-performing regions and derive a closed-form estimator that accurately reflects conditional activation and domain changes. Experiments show that naive adaptations of existing HPI estimators yield misleading or uninterpretable importance estimates in conditional settings, whereas condPED-ANOVA consistently provides meaningful importances that reflect the underlying conditional structure.
Application of Contrastive Learning on ECG Data: Evaluating Performance in Japanese and Classification with Around 100 Labels
Apr 12, 2025The electrocardiogram (ECG) is a fundamental tool in cardiovascular diagnostics due to its powerful and non-invasive nature. One of the most critical usages is to determine whether more detailed examinations are necessary, with users ranging across various levels of expertise. Given this diversity in expertise, it is essential to assist users to avoid critical errors. Recent studies in machine learning have addressed this challenge by extracting valuable information from ECG data. Utilizing language models, these studies have implemented multimodal models aimed at classifying ECGs according to labeled terms. However, the number of classes was reduced, and it remains uncertain whether the technique is effective for languages other than English. To move towards practical application, we utilized ECG data from regular patients visiting hospitals in Japan, maintaining a large number of Japanese labels obtained from actual ECG readings. Using a contrastive learning framework, we found that even with 98 labels for classification, our Japanese-based language model achieves accuracy comparable to previous research. This study extends the applicability of multimodal machine learning frameworks to broader clinical studies and non-English languages.
JRadiEvo: A Japanese Radiology Report Generation Model Enhanced by Evolutionary Optimization of Model Merging
Nov 15, 2024With the rapid advancement of large language models (LLMs), foundational models (FMs) have seen significant advancements. Healthcare is one of the most crucial application areas for these FMs, given the significant time and effort required for physicians to analyze large volumes of patient data. Recent efforts have focused on adapting multimodal FMs to the medical domain through techniques like instruction-tuning, leading to the development of medical foundation models (MFMs). However, these approaches typically require large amounts of training data to effectively adapt models to the medical field. Moreover, most existing models are trained on English datasets, limiting their practicality in non-English-speaking regions where healthcare professionals and patients are not always fluent in English. The need for translation introduces additional costs and inefficiencies. To address these challenges, we propose a \textbf{J}apanese \textbf{Radi}ology report generation model enhanced by \textbf{Evo}lutionary optimization of model merging (JRadiEvo). This is the first attempt to extend a non-medical vision-language foundation model to the medical domain through evolutionary optimization of model merging. We successfully created a model that generates accurate Japanese reports from X-ray images using only 50 translated samples from publicly available data. This model, developed with highly efficient use of limited data, outperformed leading models from recent research trained on much larger datasets. Additionally, with only 8 billion parameters, this relatively compact foundation model can be deployed locally within hospitals, making it a practical solution for environments where APIs and other external services cannot be used due to strict privacy and security requirements.
The T05 System for The VoiceMOS Challenge 2024: Transfer Learning from Deep Image Classifier to Naturalness MOS Prediction of High-Quality Synthetic Speech
Sep 14, 2024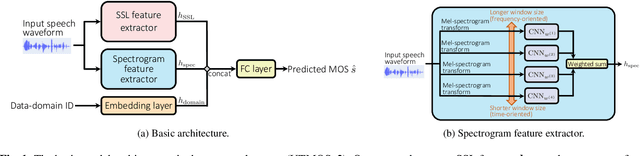
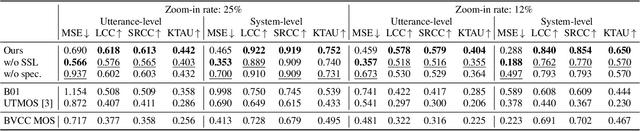

We present our system (denoted as T05) for the VoiceMOS Challenge (VMC) 2024. Our system was designed for the VMC 2024 Track 1, which focused on the accurate prediction of naturalness mean opinion score (MOS) for high-quality synthetic speech. In addition to a pretrained self-supervised learning (SSL)-based speech feature extractor, our system incorporates a pretrained image feature extractor to capture the difference of synthetic speech observed in speech spectrograms. We first separately train two MOS predictors that use either of an SSL-based or spectrogram-based feature. Then, we fine-tune the two predictors for better MOS prediction using the fusion of two extracted features. In the VMC 2024 Track 1, our T05 system achieved first place in 7 out of 16 evaluation metrics and second place in the remaining 9 metrics, with a significant difference compared to those ranked third and below. We also report the results of our ablation study to investigate essential factors of our system.