 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional PED-ANOVA: Hyperparameter Importance in Hierarchical & Dynamic Search Spaces
Jan 28, 2026We propose conditional PED-ANOVA (condPED-ANOVA), a principled framework for estimating hyperparameter importance (HPI) in conditional search spaces, where the presence or domain of a hyperparameter can depend on other hyperparameters. Although the original PED-ANOVA provides a fast and efficient way to estimate HPI within the top-performing regions of the search space, it assumes a fixed, unconditional search space and therefore cannot properly handle conditional hyperparameters. To address this, we introduce a conditional HPI for top-performing regions and derive a closed-form estimator that accurately reflects conditional activation and domain changes. Experiments show that naive adaptations of existing HPI estimators yield misleading or uninterpretable importance estimates in conditional settings, whereas condPED-ANOVA consistently provides meaningful importances that reflect the underlying conditional structure.
PLaMo-100B: A Ground-Up Language Model Designed for Japanese Proficiency
Oct 10, 2024



We introduce PLaMo-100B, a large-scale language model designed for Japanese proficiency. The model was trained from scratch using 2 trillion tokens, with architecture such as QK Normalization and Z-Loss to ensure training stability during the training process. Post-training techniques, including Supervised Fine-Tuning and Direct Preference Optimization, were applied to refine the model's performance. Benchmark evaluations suggest that PLaMo-100B performs well, particularly in Japanese-specific tasks, achieving results that are competitive with frontier models like GPT-4.
Warm Starting CMA-ES for Hyperparameter Optimization
Dec 13, 2020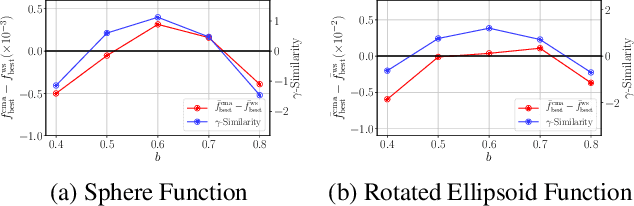

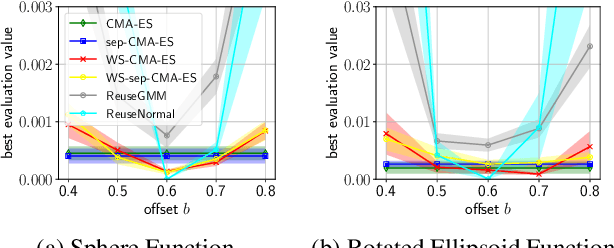
Hyperparameter optimization (HPO), formulated as black-box optimization (BBO), is recognized as essential for automation and high performance of machine learning approaches. The CMA-ES is a promising BBO approach with a high degree of parallelism, and has been applied to HPO tasks, often under parallel implementation, and shown superior performance to other approaches including Bayesian optimization (BO). However, if the budget of hyperparameter evaluations is severely limited, which is often the case for end users who do not deserve parallel computing, the CMA-ES exhausts the budget without improving the performance due to its long adaptation phase, resulting in being outperformed by BO approaches. To address this issue, we propose to transfer prior knowledge on similar HPO tasks through the initialization of the CMA-ES, leading to significantly shortening the adaptation time. The knowledge transfer is designed based on the novel definition of task similarity, with which the correlation of the performance of the proposed approach is confirmed on synthetic problems. The proposed warm starting CMA-ES, called WS-CMA-ES, is applied to different HPO tasks where some prior knowledge is available, showing its superior performance over the original CMA-ES as well as BO approaches with or without using the prior knowledge.