 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptuna Constrained Tree-Structured Parzen Estimator Is a Joint Density Generalization of c-TPE
Jun 03, 2026Constrained hyperparameter optimization (HPO) is common in practice, yet Optuna's widely used constrained TPE lacks algorithmic analysis. While c-TPE proposes an expected constrained improvement (ECI) approach assuming independence between the objective and constraints, Optuna uses a single joint density over both. We show that Optuna's constrained TPE is joint c-TPE -- the same ECI acquisition function using a joint likelihood. We demonstrate joint c-TPE is invariant to constraint duplication whereas independent c-TPE degrades as the product accumulates duplicated factors. We outline practical tradeoffs between the formulations and directions for future study.
Conditional PED-ANOVA: Hyperparameter Importance in Hierarchical & Dynamic Search Spaces
Jan 28, 2026We propose conditional PED-ANOVA (condPED-ANOVA), a principled framework for estimating hyperparameter importance (HPI) in conditional search spaces, where the presence or domain of a hyperparameter can depend on other hyperparameters. Although the original PED-ANOVA provides a fast and efficient way to estimate HPI within the top-performing regions of the search space, it assumes a fixed, unconditional search space and therefore cannot properly handle conditional hyperparameters. To address this, we introduce a conditional HPI for top-performing regions and derive a closed-form estimator that accurately reflects conditional activation and domain changes. Experiments show that naive adaptations of existing HPI estimators yield misleading or uninterpretable importance estimates in conditional settings, whereas condPED-ANOVA consistently provides meaningful importances that reflect the underlying conditional structure.
Batch Acquisition Function Evaluations and Decouple Optimizer Updates for Faster Bayesian Optimization
Nov 18, 2025


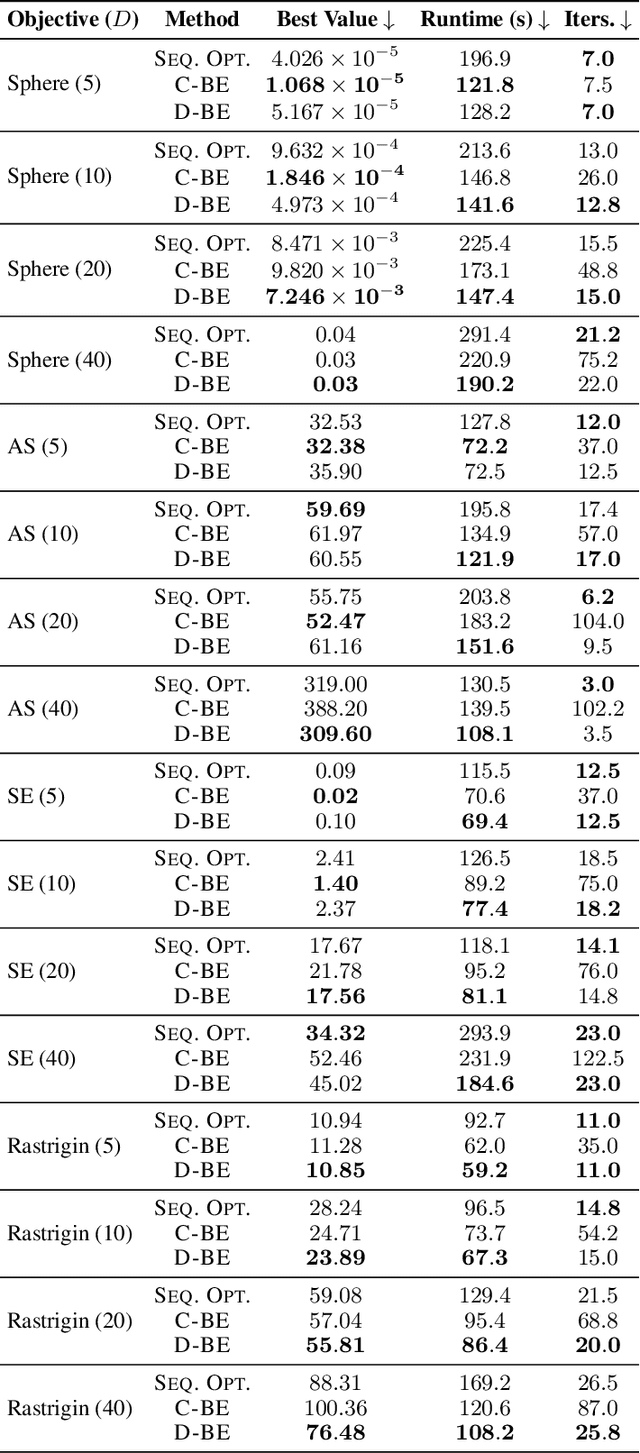
Bayesian optimization (BO) efficiently finds high-performing parameters by maximizing an acquisition function, which models the promise of parameters. A major computational bottleneck arises in acquisition function optimization, where multi-start optimization (MSO) with quasi-Newton (QN) methods is required due to the non-convexity of the acquisition function. BoTorch, a widely used BO library, currently optimizes the summed acquisition function over multiple points, leading to the speedup of MSO owing to PyTorch batching. Nevertheless, this paper empirically demonstrates the suboptimality of this approach in terms of off-diagonal approximation errors in the inverse Hessian of a QN method, slowing down its convergence. To address this problem, we propose to decouple QN updates using a coroutine while batching the acquisition function calls. Our approach not only yields the theoretically identical convergence to the sequential MSO but also drastically reduces the wall-clock time compared to the previous approaches. Our approach is available in GPSampler in Optuna, effectively reducing its computational overhead.
Derivation of Output Correlation Inferences for Multi-Output (aka Multi-Task) Gaussian Process
Jan 14, 2025Gaussian process (GP) is arguably one of the most widely used machine learning algorithms in practice. One of its prominent applications is Bayesian optimization (BO). Although the vanilla GP itself is already a powerful tool for BO, it is often beneficial to be able to consider the dependencies of multiple outputs. To do so, Multi-task GP (MTGP) is formulated, but it is not trivial to fully understand the derivations of its formulations and their gradients from the previous literature. This paper serves friendly derivations of the MTGP formulations and their gradients.
Derivation of Closed Form of Expected Improvement for Gaussian Process Trained on Log-Transformed Objective
Nov 27, 2024Expected Improvement (EI) is arguably the most widely used acquisition function in Bayesian optimization. However, it is often challenging to enhance the performance with EI due to its sensitivity to numerical precision. Previously, Hutter et al. (2009) tackled this problem by using Gaussian process trained on the log-transformed objective function and it was reported that this trick improves the predictive accuracy of GP, leading to substantially better performance. Although Hutter et al. (2009) offered the closed form of their EI, its intermediate derivation has not been provided so far. In this paper, we give a friendly derivation of their proposition.
Fast Benchmarking of Asynchronous Multi-Fidelity Optimization on Zero-Cost Benchmarks
Mar 04, 2024While deep learning has celebrated many successes, its results often hinge on the meticulous selection of hyperparameters (HPs). However, the time-consuming nature of deep learning training makes HP optimization (HPO) a costly endeavor, slowing down the development of efficient HPO tools. While zero-cost benchmarks, which provide performance and runtime without actual training, offer a solution for non-parallel setups, they fall short in parallel setups as each worker must communicate its queried runtime to return its evaluation in the exact order. This work addresses this challenge by introducing a user-friendly Python package that facilitates efficient parallel HPO with zero-cost benchmarks. Our approach calculates the exact return order based on the information stored in file system, eliminating the need for long waiting times and enabling much faster HPO evaluations. We first verify the correctness of our approach through extensive testing and the experiments with 6 popular HPO libraries show its applicability to diverse libraries and its ability to achieve over 1000x speedup compared to a traditional approach. Our package can be installed via pip install mfhpo-simulator.
Python Wrapper for Simulating Multi-Fidelity Optimization on HPO Benchmarks without Any Wait
May 27, 2023Hyperparameter (HP) optimization of deep learning (DL) is essential for high performance. As DL often requires several hours to days for its training, HP optimization (HPO) of DL is often prohibitively expensive. This boosted the emergence of tabular or surrogate benchmarks, which enable querying the (predictive) performance of DL with a specific HP configuration in a fraction. However, since actual runtimes of a DL training are significantly different from query response times, in a naive implementation, simulators of an asynchronous HPO, e.g. multi-fidelity optimization, must wait for the actual runtimes at each iteration; otherwise, the evaluation order in the simulator does not match with the real experiment. To ease this issue, we develop a Python wrapper to force each worker to wait in order to match the evaluation order with the real experiment and describe the usage. Our implementation reduces the waiting time to 0.01 seconds and it is available at https://github.com/nabenabe0928/mfhpo-simulator/.
Python Tool for Visualizing Variability of Pareto Fronts over Multiple Runs
May 15, 2023Hyperparameter optimization is crucial to achieving high performance in deep learning. On top of the performance, other criteria such as inference time or memory requirement often need to be optimized due to some practical reasons. This motivates research on multi-objective optimization (MOO). However, Pareto fronts of MOO methods are often shown without considering the variability caused by random seeds and this makes the performance stability evaluation difficult. Although there is a concept named empirical attainment surface to enable the visualization with uncertainty over multiple runs, there is no major Python package for empirical attainment surface. We, therefore, develop a Python package for this purpose and describe the usage. The package is available at https://github.com/nabenabe0928/empirical-attainment-func.
Tree-structured Parzen estimator: Understanding its algorithm components and their roles for better empirical performance
Apr 25, 2023Recent advances in many domains require more and more complicated experiment design. Such complicated experiments often have many parameters, which necessitate parameter tuning. Tree-structured Parzen estimator (TPE), a Bayesian optimization method, is widely used in recent parameter tuning frameworks. Despite its popularity, the roles of each control parameter and the algorithm intuition have not been discussed so far. In this tutorial, we will identify the roles of each control parameter and their impacts on hyperparameter optimization using a diverse set of benchmarks. We compare our recommended setting drawn from the ablation study with baseline methods and demonstrate that our recommended setting improves the performance of TPE. Our TPE implementation is available at https://github.com/nabenabe0928/tpe/tree/single-opt.
PED-ANOVA: Efficiently Quantifying Hyperparameter Importance in Arbitrary Subspaces
Apr 20, 2023The recent rise in popularity of Hyperparameter Optimization (HPO) for deep learning has highlighted the role that good hyperparameter (HP) space design can play in training strong models. In turn, designing a good HP space is critically dependent on understanding the role of different HPs. This motivates research on HP Importance (HPI), e.g., with the popular method of functional ANOVA (f-ANOVA). However, the original f-ANOVA formulation is inapplicable to the subspaces most relevant to algorithm designers, such as those defined by top performance. To overcome this problem, we derive a novel formulation of f-ANOVA for arbitrary subspaces and propose an algorithm that uses Pearson divergence (PED) to enable a closed-form computation of HPI. We demonstrate that this new algorithm, dubbed PED-ANOVA, is able to successfully identify important HPs in different subspaces while also being extremely computationally efficient.